Hey yoo,chào mọi người,trong bài viết này mình sẽ nói về cách xây dựng một project Web Scraping nho nhỏ và chạy thử code demo.
Các bạn có thể xem hai bài viết trước của mình để hiểu thêm về Scrapy.
Chọn trang web
Trong bài viết này mình sẽ dùng trang Web https://9to5mac.com/ để làm demo.Mình sẽ lấy hết các bài báo trên trang web này.
Phân tích trang web
Trước khi bắt đầu thì chúng ta phải biết xem trang web thuộc loại render gì ?
Có 2 kiểu render thường thấy đó là render ra HTML và render ra JSON.
Mình đã thử vào tab network và thấy ……
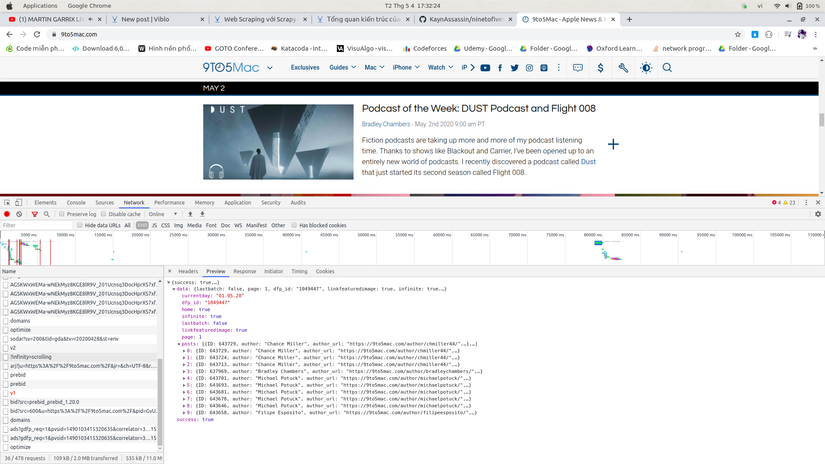
Oh trang web này render ra JSON ,vậy là dễ rồi …
Khởi tạo project
MÌnh khởi tạo project bằng các lệnh
1 2 | scrapy startproject ninetofivemac |
1 2 | cd ninetofivemac |
1 2 | scrapy genspider mac 9to5mac.com |
Trong class MacSpider chuyển start_urls thành start_urls = ['https://9to5mac.com/?infinity=scrolling']
Chúng ta cấu hình cho thuộc tính của class MacSpider như sau :
1 2 3 4 | name = 'mac' allowed_domains = ['9to5mac.com'] start_urls = ['https://9to5mac.com/?infinity=scrolling'] |
Viết code cho Spider
Thêm Class Request để thực hiện http Request để lấy data.
1 2 | from scrapy import Request |
Method start_requests luôn chạy đầu tiên khi chạy Spider. Do trang web này là infinite scroll page nên mình để page là 10,thực tế mình đã test nó có hơn 1000 trang.
Mình dùng phương thức POST với formdata là index của trang và sẽ gọi hàm callback chứa response là kết quả trả về sau khi thực hiện HTTP request.
1 2 3 4 | def start_requests(self): for i in range(1,10): yield scrapy.http.FormRequest(url=self.start_urls[0],formdata = {"page":str(i)},callback=self.parse_info) |
Sau mỗi request mình sẽ parse cái response từ dạng text thành json bằng cách :
1 2 | res = json.loads(response.text) |
Response sau khi Scrape về có dạng như sau ,mình thử với Postman:
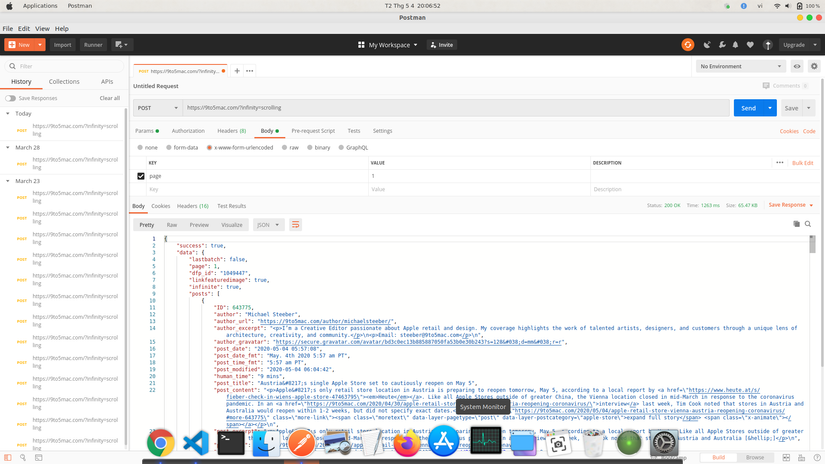
Nhận thấy response dạng Json này còn thiếu data ở mỗi Item,data này có thể lấy theo field permalink chứa trong response nên mình tiếp tục request để lấy lượng data còn lại.
1 2 3 4 5 6 | def parse_info(self,response): res = json.loads(response.text) if res["success"] == True : for i in res["data"]["posts"]: yield Request(url=i["permalink"]+"json/content/",callback=self.parse_final_info,meta={"item":i}) |
Kết quả trả về như hình
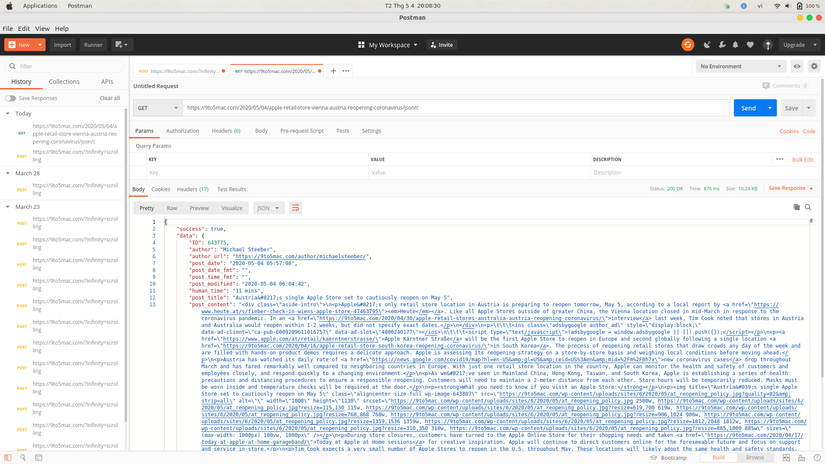
Lượng data còn thiếu của mỗi Item mình sẽ merge với Item đó .
1 2 3 4 5 6 | def parse_final_info(self,response): res = response.meta.get("item") sub_content = json.loads(response.text) res["sub_content"] = sub_content yield res |
Viết code cho pipelines
Mỗi Item trả về sẽ đi qua pipeline mà mình config trong file pipelines,pipeline sẽ khởi tạo và lưu response vào một file JSON.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from scrapy.exporters import JsonItemExporter class JsonPipeline(object): def __init__(self): self.file = open("1.json", 'wb') self.exporter = JsonItemExporter(self.file, encoding='utf-8', ensure_ascii=False) self.exporter.start_exporting() def close_spider(self, spider): self.exporter.finish_exporting() self.file.close() def process_item(self, item, spider): self.exporter.export_item(item) return item |
Run code
Chạy code với câu lệnh :
1 2 | scrapy crawl "tên spider" |
Chúng ta chạy code và … tada… được kết quả như hình.
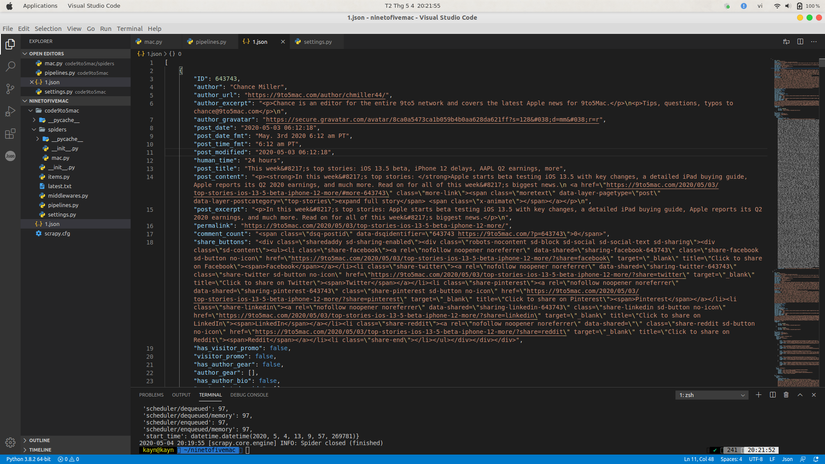
Kết luận
Trên đây mình đã demo một project nho nhỏ về Scrape data,hi vọng mọi người thích.Nếu thích hãy cho mình một click up nhé,cảm ơn 
Source code : https://github.com/KaynAssassin/ninetofivemac