
Ai,Machine Learning đang là xu thế hot trong kỉ nguyên công nghệ 4.0. Để có thể làm việc với nó thì một trong những thứ quan trọng hàng đầu đó là data,với lượng data càng lớn và tính xác thực càng cao,thì càng tốt cho việc huấn luyện.
Trong bài viết này mình xin được giới thiệu cách thu thập data với Scrapy.
Cài đặt
Yêu cầu đầu tiên để sử dụng Scrapy đó là phải cài Python3 và Scrapy (tất nhiên rồi ^^ ) .
Python3
1.Mở terminal và nhập vào lệnh
1 2 | sudo add-apt-repository ppa:jonathonf/python-3.6 && sudo apt-get update |
2.Install python 3.6 bằng lệnh
1 2 | sudo apt-get install python3.6 |
Scrapy
1.Install Scrapy bằng lệnh
1 2 | pip install scrapy |
Viết chương trình đầu tiên
Trong bài viết này mình sẽ dùng trang web https://9to5mac.com/ để demo cho việc Scraping.
Khởi tạo Project
1.Mở terminal,khởi tạo Project Scrapy đầu tiên bằng lệnh
1 2 | scrapy startproject "tên project" |
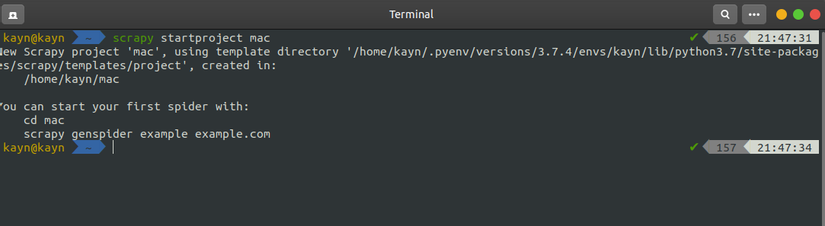
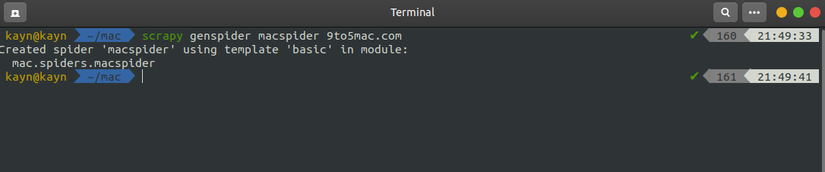
2.Dùng cd để trỏ đến Project ,sau đó khởi tạo Spider bằng lệnh
1 2 | scrapy genspider "tên spider" "tên domain" |
ở đây mình đặt là :
1 2 | scrapy genspider macspider 9to5mac.com |
Viết code cho Spider đầu tiên
1.Các bạn dùng IDE mở project lên,mở file Spider trong thư mục spiders .
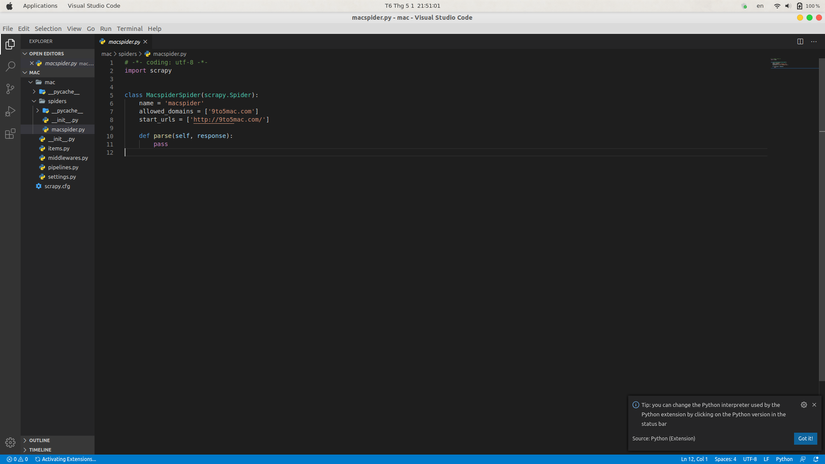
2.Để bắt đầu mình sẽ import object Request bằng cú pháp :
1 2 | from scrapy import Request |
3.Bắt đầu request bằng việc khởi tạo method start_requests.
1 2 3 4 | def start_requests(self): for url in self.start_urls: yield Request(url = url,callback = self.parse_info) |
Hàm callback parse_info sẽ chứa object là response của trang html.
Tạo method parse_info
1 2 3 4 | def parse_info(self,response): y = response.text print(y) |
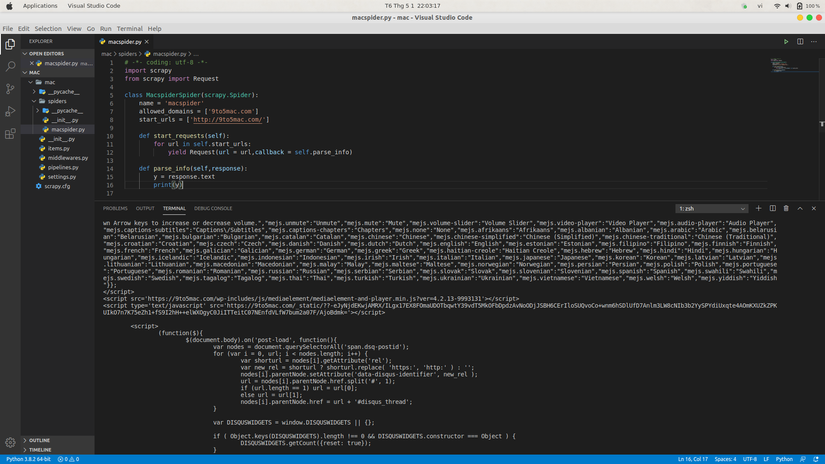
Sau đó chúng ta chạy Spider bằng lệnh :
1 2 | scrapy crawl macspider |
Như chúng ta thấy ở hình dưới ,Data đã được scrape về
Kết luận
Ô kê bạn ơi,qua bài viết này mình đã giới thiệu qua về Scrapy,bài viết tiếp theo mình sẽ giới thiệu về engine bên dưới của nó,cảm ơn mọi người đã quan tâm
1 2 | VIỆT NAM VÔ ĐỊCH |