Hey yoo, hi everyone, in this article I will talk about how to build a small Web Scraping project and test demo code.
You can check out my previous two posts to learn more about Scrapy.
Choose site
In this article I will use the Web site https://9to5mac.com/ to make a demo. I will get all the articles on this site. 
Web analytics
Before we begin, we have to know what kind of render the site is.
There are 2 common types of renderings, which are HTML and JSON.
I tried going to the network tab and found … 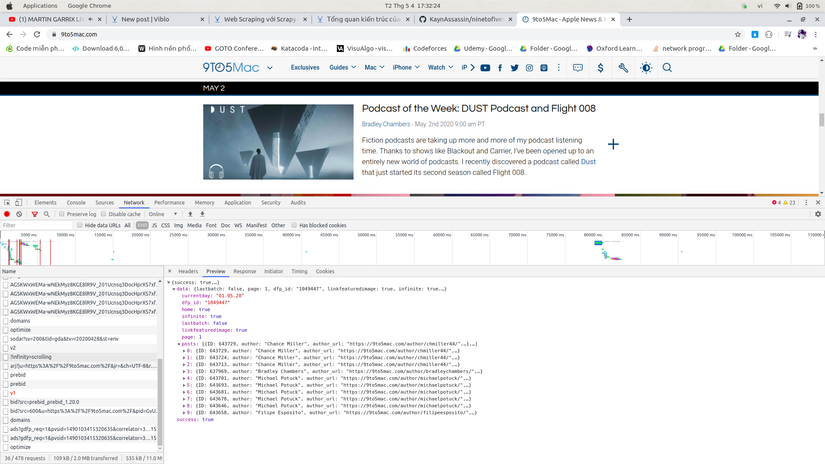
Oh this site renders JSON, so easy …
Initialize project
I initialized the project with the commands
1 2 | scrapy startproject ninetofivemac |
1 2 | cd ninetofivemac |
1 2 | scrapy genspider mac 9to5mac.com |
In MacSpider class, convert start_urls to start_urls = ['https://9to5mac.com/?infinity=scrolling']
We configure the properties of the MacSpider class as follows:
1 2 3 4 | name = 'mac' allowed_domains = ['9to5mac.com'] start_urls = ['https://9to5mac.com/?infinity=scrolling'] |
Write code for Spider
Add Class Request to make http Request to get data.
1 2 | from scrapy import Request |
The start_requests method always runs first when running the Spider. Since this site is an infinite scroll page so I set the page to 10, in fact I tested it to have more than 1000 pages.
I use the POST method with formdata as the index of the page and will call the callback function containing the response is the result returned after making an HTTP request.
1 2 3 4 | def start_requests(self): for i in range(1,10): yield scrapy.http.FormRequest(url=self.start_urls[0],formdata = {"page":str(i)},callback=self.parse_info) |
After each request, I will parse the response from the text into json by:
1 2 | res = json.loads(response.text) |
Response after Scrape about looks like the following, I tried with Postman:
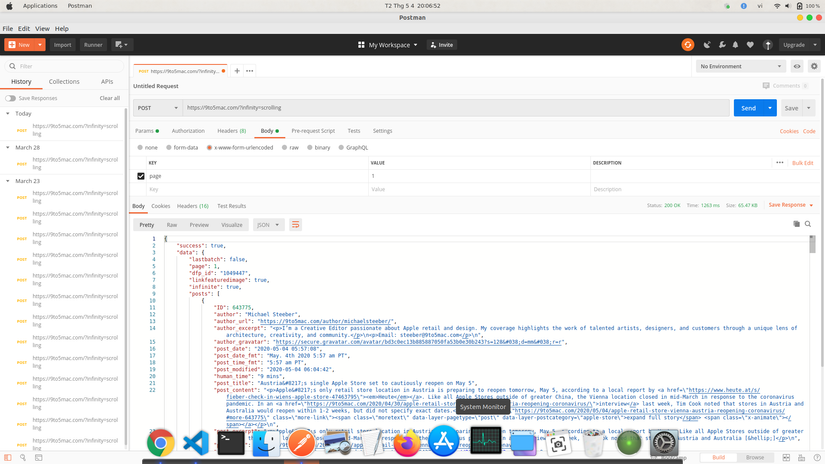
Realizing that this Json-type response is missing data in each Item, this data can be retrieved according to the permalink field contained in the response so I continue to request to get the remaining data.
1 2 3 4 5 6 | def parse_info(self,response): res = json.loads(response.text) if res["success"] == True : for i in res["data"]["posts"]: yield Request(url=i["permalink"]+"json/content/",callback=self.parse_final_info,meta={"item":i}) |
The results returned as shown 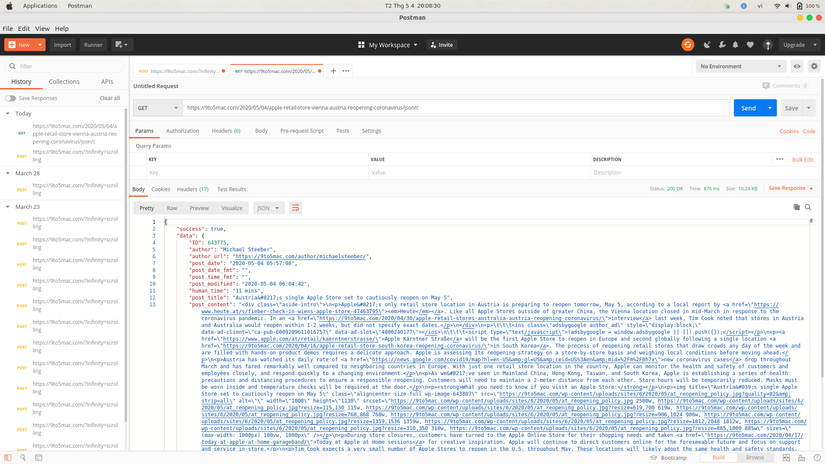
The amount of missing data of each Item I will merge with that Item.
1 2 3 4 5 6 | def parse_final_info(self,response): res = response.meta.get("item") sub_content = json.loads(response.text) res["sub_content"] = sub_content yield res |
Write code for pipelines
Each returned Item will go through the pipeline that I configured in the pipelines file, the pipeline will initialize and save the response into a JSON file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from scrapy.exporters import JsonItemExporter class JsonPipeline(object): def __init__(self): self.file = open("1.json", 'wb') self.exporter = JsonItemExporter(self.file, encoding='utf-8', ensure_ascii=False) self.exporter.start_exporting() def close_spider(self, spider): self.exporter.finish_exporting() self.file.close() def process_item(self, item, spider): self.exporter.export_item(item) return item |
Run code
Run the code with the command:
1 2 | scrapy crawl "tên spider" |
We run the code and … tada … get the following result.
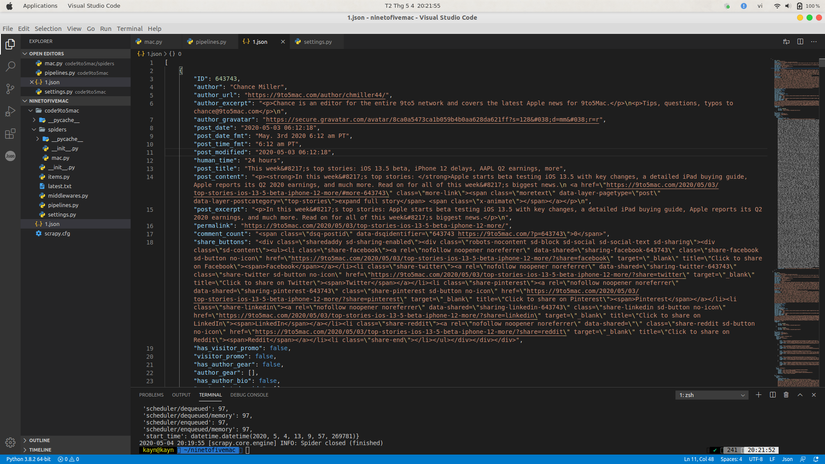
Conclude
Above, I have demoed a small project about Scrape data, hope everyone likes it. If you like please give me a click up, thanks 
Source code: https://github.com/KaynAssassin/ninetofivemac