Những kiến thức giúp website của bạn nhanh lên gấp N lần
Introduction
ISUCON là một cuộc thi ở Nhật, và cũng chỉ có riêng ở Nhật. Đây là một cuộc thi khá đặc trưng bởi sự thú vị của cách thi của nó, những người thi thay vì build sản phẩm như hackathon, hay là giải bài toán như là competitive programming, Tại ISUCON thì mỗi 1 team (thường là 2-3 members) sẽ được phát một host trên đó đã được chạy sẵn một trang web (có cả source code), và công việc phải làm của bạn là trong vòng 8 tiếng, phải tune thế nào để trang web đó đạt được throughput cao nhất. Kết quả team Việt Nam lần đầu tham dự, gồm có tôi và một bạn nữa, đứng khoảng thứ 20 trên 300 đội tham dự, không được vào vòng kế tiếp
Bạn có thể dùng bất kì cách gì như thay đổi cấu trúc database, dán index, thêm middleware, viết lại logic của app, tuy nhiên vẫn phải đảm bảo:
- Test của chương trình benchmark để tính điểm của ban tổ chức phải pass (thường test sẽ có cả update , xoá dữ liệu nên bạn nào nghĩ đến giải pháp page cache toàn bộ endpoint thì bỏ đi nhé =)) )
- Không được thay đổi spec của host như là thêm RAM hay là thêm CPU.
Như vậy để thi được ISUCON thì đòi hỏi bạn phải có các kĩ năng:
- Biết một trang web chạy thế nào, các stack để chạy trang web đó
- Vận hành, tuning middleware layer với các stack hay được sử dụng như là nginx, mysql….
- Sử dụng tool để benchmarking, phát hiện bottleneck
- Sử dụng thành thạo các ngôn ngữ mà ban tổ chức cung cấp, thông thường sẽ có : ruby, python, golang, perl, java, scala
Để tham gia cuộc thi này thì tôi đã bỏ ra một vài tuần để ôn luyện, quá trình ôn luyện cũng đã thu được một vài kiến thức mà tôi thấy khá hữu ích, đặc biệt cho những người làm web. Dưới đây sẽ là list những thứ tôi thấy khá thú vị.
Đánh index cho mysql thế nào cho tốt ?
Để tăng tốc cho một trang web thì kĩ năng tôi nghĩ quan trọng nhất chính là mysql query tuning. Về cơ bản mysql, hay bất kì một database nào cũng là một hệ thống tìm kiếm, tức là nó support cho bạn con đường ngắn nhất để tìm đến với data mà bạn cần tìm, tuy nhiên không phải lúc nào mysql cũng tự tìm được đường ngắn nhất, mà cần support từ developer. Đánh index cho mysql chính là việc bạn “hỗ trợ” cho mysql tìm đươc con đường ngắn nhất đó.
Chắc nhiều bạn đã biết thì mysql sử dụng B-Tree để lưu index (Storage engine là InnoDB)
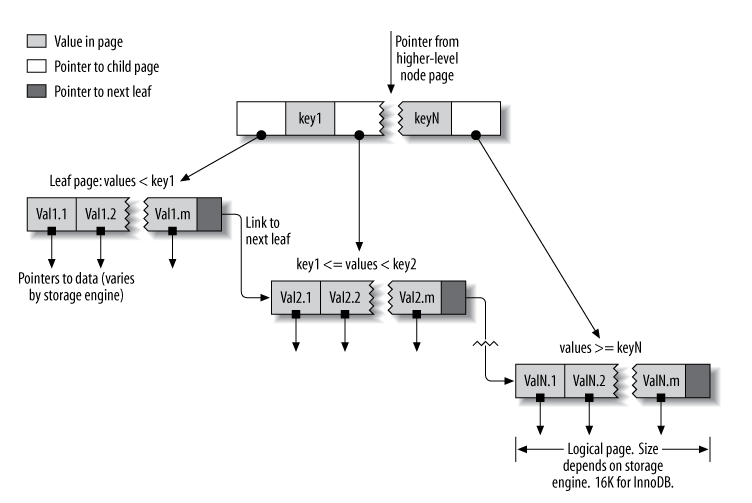
Bạn không cần biết quá nhiều về B-Tree, chỉ cần biết
- Nó là 1 cái cây =)))
- Nó support range query
- Và để support range query nó sẽ có pointer giữa các leaf (thay vì chỉ có pointer từ cha -> con như một cây thông thường). Việc này sẽ dấn đến một sự thật khá thú vị về đánh index cho mysql mà tôi sẽ nói ở dưới đây ?
Thứ tự khi đánh index rất quan trọng!
Bạn có thể nhìn thấy ở hình trên, pointer của các leaf sẽ được chỉ từ trái sang phải. Do đó index của bạn cũng tương tự, giả sử bạn có query sau:
1 | SELECT foo, bar FROM XYZ WHERE foo = '1' AND bar = '2' AND hoge = '3' |
Ở query trên bạn sẽ query sử dụng AND tức là bạn cần một index cover cả foo và bar field để support cho mysql để nó có thể dựa vào index của cả 2 để tìm được thông tin mình cần.
1 | ALTER TABLE XYZ ADD INDEX idx_foo_bar_hoge(foo, bar, hoge) |
Tuy nhiên multicolumn index chỉ work khi mà select order của bạn theo đúng thứ tự hoặc theo thứ tự ngược (reverse or forward order) so với khi index được tạo. Do đó nếu bạn select so với thứ tự đổi đi một chút.
1 | SELECT foo, bar FROM XYZ WHERE foo = '1' AND hoge = '2' AND bar = '3' |
thì MySQL sẽ không biết là cần phải reorder lại query và dùng idx_foo_bar_hoge hỗ trợ cho việc tìm kiếm. Khi đó bạn sẽ phải tạo một index mới với thứ tự đúng:
1 | ALTER TABLE XYZ ADD INDEX idx_hoge_bar_foo(bar, hoge, foo) |
Note: kiến thức về order index đã không còn đúng do hiện nay mysql đã hỗ trợ Index Condition Pushdown Optimization
Thứ tự index sẽ ảnh hưởng lớn nhất khi dùng câu lệnh LIKE, mà chi tiết tham khảo thêm:
http://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html
Index ảnh hưởng thế nào với OR query
Với AND query thì mọi thứ khá straight forward để bạn hình dung là 1 index liệu có work với 1 query hay không. Tuy nhiên mọi thứ không dễ dàng như thế với OR query.
1 | SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20; |
Điểm khác lớn nhất của AND query với OR query là với AND query bạn có thể dùng multi column index còn OR query index thì … không. Lý do rất dễ hiểu, bạn cần thông tin của cả 2 field key1 và key2, nhưng không cần cùng 1 lúc, vì nó là OR mà. Khi đó bạn phải đánh index thế nào nhỉ?
Chắc bạn đang nghĩ là quá dễ, chỉ cần có 1 index của field 1, và 1 index của field 2 là xong! Vậy thì bạn nghĩ hoàn toàn … đúng rồi :P. Cơ mà không phải tự nhiên mà nó work, mà là do mysql đã support cho chúng ta một cơ chế gọi là merge index, tức là đầu tiên nó sẽ tìm tất cả record liên quan đến index của field 1, và sau đó tìm tất cả records liên quan đến index của field 2, sau đó merge kết quả vào nhau.
Bạn có thể tìm hiểu kĩ hơn tại: http://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html
(Tôi khuyên là bạn nên đọc tài liệu ở trên vì nó có nói đến một số trường hợp như complex WHERE khi mà có cả AND lẫn OR lồng vào nhau)
Covering index là gì???
Covering index là một loại index đặc biệt, mà nó chứa luôn cả data cần tìm kiếm. Thông thường thì như mình đã nói ở trên, index chỉ là để “giúp đỡ” mysql có thể biết được địa chỉ của data mà nó cần tìm kiếm, tuy nhiên covering index lại là loại index đặc biệt mà bạn không cần phải tìm kiếm thêm ở đâu xa, bởi mọi thứ mà bạn cần đã ở ngay đó.Thông thường b-tree index là một cái cây, mà lá của nó sẽ là key (index) và field information, do đó mà nếu mọi thứ bạn tìm (nằm trong SELECT query) được sử dụng trong index (nằm trong WHERE) thì mysql sẽ không cần phải đi đâu xa mà tìm được mọi thông tin bạn cần.
Giải thích thì dài dòng nhưng mình tóm gọn lại là: nên cố gắng chỉ select những thứ nằm trong WHERE, và làm thế nào để mọi thứ trong WHERE đều được index, thì sẽ tiết kiệm được rất nhiều random IO
Tham khảo thêm: http://planet.mysql.com/entry/?id=661727
Cẩn thận với query function
Nhiều khi trong query của bạn sẽ sử dụng các hàm tính toán của mysql như là cộng trừ nhân chia, thêm ngày tháng. Với ví dụ khá đơn giản dưới đây:
1 | SELECT field FROM table WHERE field + 1 = 5 |
Thì ngay cả khi field được đánh index một cách trọn vẹn thì mysql cũng không thể sử dụng index đó được, lý do rất đơn giản, mysql không đủ thông minh để biét được rằng query trên tương đương với
1 | SELECT field FROM table WHERE field = 4 |
Nên sử dụng auto increment cho primary key
Tất cả những mục ở trên đều nhằm cho một mục đích lớn nhât: làm thế nào để query sao cho nhanh nhất, hay là optimize cho thao tác đọc. Vậy làm thế nào để thao tác ghi (INSERT) sao cho nhanh nhất (hay là làm thế nào để INSERT vào những field có index sao cho nhanh nhất). Quay lại định nghĩa ở trên về index, thì nó là 1 cái cây, mà không phải là 1 cái cây thông thường mà là một cái cây đã được sort. Điểm khác nhau giữa việc insert vào một sorted data-structure và non-sorted data-structure là để insert vào thằng không sort thì quá dễ, cứ insert vào mông (giống kiểu WAL, write ahead log) là được, còn insert vào thằng sorted thì chúng ta cần tìm xem nên insert vào đâu đã , rồi mới insert được, đúng không :D.
Từ idea ở trên chúng ta có thể dễ dàng đưa ra kêt luận là: insert vào một table mà primary key là auto-increment sẽ nhanh hơn là insert vào một table mà primary key là uuid dạng string, lý do thì như ở trên, nếu index là autoincrement thì quá dễ, mysql chỉ cần insert vào mông là đủ.
Null hay không Null?
Mysql support cho giá trị null, tức là tồn tại một trạng thái không có dữ liệu. Để support trạng thái này thì mysql phải lưu thêm thông tin mỗi row (dạng như 1 field có thể là có null hay không), khiến cho data bị phình to ra. Do đó chúng ta không nên dùng default null cho tất cả các field
Config buffer pool
Innodb sử dụng một vùng nhớ gọi là buffer pool cho mục đích là cache data và lưu index. Vùng nhớ này lưu theo đơn vị là page (default là 16kb) và sử dụng LRU algorithm để evict cache. Về cơ bản thì buffer càng to càng tốt =))). Buffer càng to, query cache được càng nhiều, dẫn đến query không cần hit IO cũng ok. Bạn set to thế nào để các app khác chạy trên cùng instance có đủ memory để dùng là đc :v.
Tham khảo:
http://dba.stackexchange.com/questions/27328/how-large-should-be-mysql-innodb-buffer-pool-size
https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
http://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_page_size
Sử dụng nginx thế nào cho tốt
Nginx là một giải pháp hoàn hảo có thể giúp cho bạn rất nhiều thứ, từ reverse proxy, đến deliver static file (như là css/js/image), đến load balancing. Việc hiểu rõ nginx có thể làm gì, và bạn có thể tuỳ chỉnh gì,
Loại bỏ các limitation ở tầng kernel
Để có thể tận dụng tốt nginx thì đôi khi có nhiều limit ở tầng kernel vốn được setup default mà không phù hợp. Những setting mà tôi nói đến dưới đây được chỉnh ở file /etc/sysctl.conf.
Đầu tiên là net.core.somaxconn: Đây là số lượng connection max mà được nginx queue (buffering) trước khi xử lý. Access càng nhiều -> nginx sẽ không xử lý kịp và phải buffer vào queue, queue càng lớn, buffer càng nhiều, block càng ít, sẽ làm nginx tăng lên tương đối
Tiếp theo là net.ipv4.ip_local_port_range: Khi sử dụng nginx dưới dạng một reverse proxy, thì mỗi một connection đến proxy sẽ sử dụng một ephemeral ports, do đó khi access nhiều sẽ dấn đên nhanh hết port, dấn đến blocking. Tăng chỉ số này sẽ giúp connection đến upstream được nhiều hơn, giúp ít blocking hơn
Tiếp nữa là sys.fs.file_max: Đây là số file descriptor max mà linux server có thể sử dụng được, mà như bạn đã biết socket trên linux là file, do đó chỉ số này càng lớn, nginx mở đc càng nhiều socket, sẽ giúp cho max connection tăng.
Cuối cùng là net.ipv4.tcp_wmem và net.ipv4.tcp_rmem: đây là 2 chỉ số của kernel để buffering cho TCP/IP. Nói chung là càng to càng tốt =)).
Dưới đây là bộ config được recommend cho nginx server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | net.ipv4.ip_local_port_range='1024 65000' net.ipv4.tcp_tw_reuse='1' net.ipv4.tcp_fin_timeout='15' net.core.netdev_max_backlog='4096' net.core.rmem_max='16777216' net.core.somaxconn='4096' net.core.wmem_max='16777216' net.ipv4.tcp_max_syn_backlog='20480' net.ipv4.tcp_max_tw_buckets='400000' net.ipv4.tcp_no_metrics_save='1' net.ipv4.tcp_rmem='4096 87380 16777216' net.ipv4.tcp_syn_retries='2' net.ipv4.tcp_synack_retries='2' net.ipv4.tcp_wmem='4096 65536 16777216' vm.min_free_kbytes='65536' |
Phân tích log nginx để tìm bottle neck
Phân tích access log từ nginx sẽ giúp bạn biết bottle neck ở đâu, có một tool rất đơn giản là
https://github.com/matsuu/kataribe
Để sử dụng tool này thì bạn cần setting nginx log format sử dụng directive
1 2 3 4 | log_format with_time '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" $request_time'; access_log /var/log/nginx/access.log with_time; |
Caching with nginx
Nginx khi sử dụng để server static file thì bạn nên để ý kĩ các setting về cache, và compression. Setting sử dụng gzip cho static file cũng rất quan trọng.
Sử dụng gzip sẽ giúp giảm rất nhiều cost liên quan đến IO, và đường truyền. Setting cache control sẽ giúp server không request lại static file đó nữa cho đến khi cache expire. Bạn có thể tham khảo setting dưới đây.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | http { gzip on; gzip_http_version 1.0; gzip_types text/plain text/html text/xml text/css application/xml application/xhtml+xml application/rss+xml application/atom_xml application/javascript application/x-javascript application/x-httpd-php; gzip_disable "MSIE [1-6]."; gzip_disable "Mozilla/4"; gzip_comp_level 1; gzip_proxied any; gzip_vary on; gzip_buffers 4 8k; gzip_min_length 1100; |
Note: Thanks to @visudoblog added
Khi sử dụng nginx dưới dạng reverse proxy, nếu memory của bạn thừa thãi, và lượng data để response cũng không lớn bạn có thể set để nginx cache trên memory thay vì trên file
1 | proxy_cache_path /dev/shm/nginx levels=1:2 keys_zone=czone:16m max_size=32m inactive=10m; |
Advance nginx
Một setting cũng rất hay được sử dụng là keepalive. Thông thường keep alive là một technique của http giúp “giữ” connection TCP lại ngay cả khi HTTP connection session đã kết thúc, để có thể reuse lại cho request tiếp theo. Technique này rất có lợi khi mà thông thường một user sẽ gửi rất nhiều request để lấy cả static resource.

Sử dụng keepalive trên nginx rất đơn giản bằng cách thêm directive keepalive vào trong upstream section
1 2 3 4 | upstream app { server 127.0.0.1:5000; keepalive 16; } |
Tham khảo thêm
- http://www.mysql.gr.jp/frame/modules/bwiki/index.php?plugin=attach&refer=matsunobu&openfile=Session-Index.pdf
- Mastering nginx : https://www.google.co.jp/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=mastering%20nginx
- High performance mysql: https://www.amazon.co.jp/High-Performance-MySQL-Optimization-Replication/dp/1449314287
- http://www.nari64.com/?p=579
- https://www.nginx.com/blog/http-keepalives-and-web-performance/
ITZone via Kipalog