The knowledge helps your website up to N times faster
Introduction
ISUCON is a competition in Japan, and it is only in Japan. This is a pretty typical competition because of the interesting way of testing, those who compete instead of build products like hackathon, or solve math problems like competitive programming, At ISUCON, each team (usually 2- 3 members) will be given a host on which a website has been run (including source code), and your job to do is within 8 hours, how to tune it so that the site achieves the highest throughput . As a result, the Vietnamese team first attended, including me and a friend , standing for about 20 out of 300 participating teams, not going to the next round.
You can use any way such as changing the database structure, pasting the index, adding middleware, rewriting the logic of the app, but still must ensure:
- Test of the benchmark program to calculate the score of the organizers must pass (usually test will have the update, delete data so you think of the solution page cache the whole endpoint, then leave it =)))
- Do not change the host spec as more RAM or add CPU.
So to test ISUCON, you must have the skills:
- Know how a website runs, the stack to run that site
- Operation, tuning middleware layer with commonly used stacks such as nginx, mysql ….
- Using the tool to benchmarking, discover bottleneck
- Proficiently using the languages provided by the organizer, usually there will be: ruby, python, golang, perl, java, scala
In order to participate in this competition, I spent a few weeks to review, the preparation process also gained some knowledge that I found quite useful, especially for web developers. Below is a list of things I find quite interesting.
How to index index for mysql for good?
To speed up a website, the most important skill I think is mysql query tuning. Basically mysql, or any database, is a search system, that is, it supports you with the shortest path to find with the data you need to find, but mysql does not always find itself. Shortest path, which needs support from the developer . Typing index for mysql is what you "support" mysql to find the shortest path there.
Many of you probably know, mysql uses B-Tree to store index (Storage engine is InnoDB)
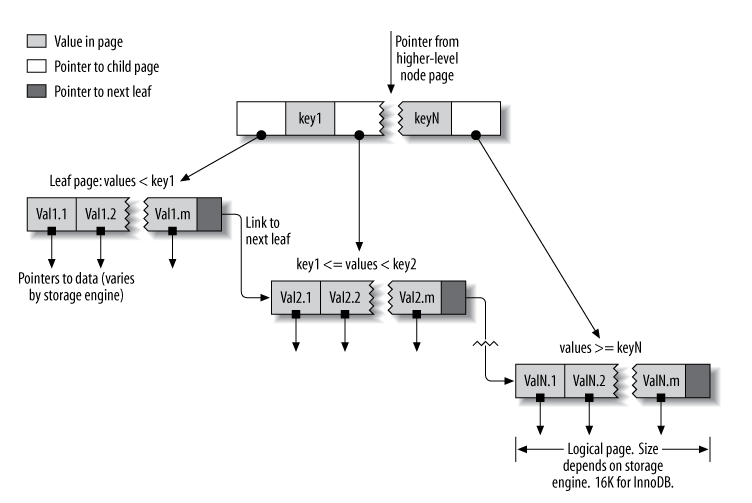
You don't need to know too much about B-Tree, just know
- It is a tree =)))
- It supports range query
- And to support range query it will have a pointer between leaves (instead of just having a pointer from parent -> child as a regular tree). This will lead to an interesting fact about indexing for mysql that I will talk about below
Order when indexing is very important!
You can see in the image above, the pointer of the leaf will be pointed from left to right . So your index is similar, assuming you have the following query:
1 | SELECT foo, bar FROM XYZ WHERE foo = '1' AND bar = '2' AND hoge = '3' |
In the above query you will query using AND ie you need an index to cover both foo and bar field to support mysql so that it can rely on the index of both to find the information you need.
1 | ALTER TABLE XYZ ADD INDEX idx_foo_bar_hoge (foo, bar, hoge) |
However, multicolumn index only works when you select your order in the correct order or reverse order (reverse or forward order) compared to when the index is created. So if you choose compared to the change order a bit.
1 | SELECT foo, bar FROM XYZ WHERE foo = '1' AND hoge = '2' AND bar = '3' |
MySQL will not know whether to reorder the query and use idx_foo_bar_hoge to support the search. You will then have to create a new index with the correct order:
1 | ALTER TABLE XYZ ADD INDEX idx_hoge_bar_foo (bar, hoge, foo) |
Note: knowledge of order index is no longer true because mysql now supports Index Condition Pushdown Optimization
The order of indexes will have the greatest impact when using the LIKE statement, which details refer to:
http://dev.mysql.com/doc/refman/5.7/en/multiple-column-indexes.html
How does Index affect OR queries
With AND queries, everything is pretty straight forward so you can imagine whether an index is working with a query. However, things are not so easy with OR queries.
1 | SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20; |
The biggest difference of AND queries with OR queries is that with AND queries you can use the multi column index and the OR query index is … no. The reason is very easy to understand, you need the information of both key1 and key2 fields, but not at the same time, because it is an OR . When did you have to beat the index?
You probably think it's too easy, just have 1 index of field 1, and 1 index of field 2 is done! So you think completely … right: P. But it is not natural that it works, but because mysql has supported us with a mechanism called merge index , it will first find all records related to the index of field 1, and then find all records. both records are related to the index of field 2, then merge the results together.
You can find out more at: http://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html
(I recommend reading the above document because it refers to some cases like complex WHERE when there are both AND and OR nested).
What is the covering index ???
The covering index is a special index type, which contains all the data to be searched . Normally, as I said above, index is only to "help" MySQL can know the address of the data it needs to search , but the index index is a special index type that you do not need to search. Where is the remote, because everything you need is right there. Usually b-tree index is a tree, but its leaves will be key (index) and field information, so if everything you find ( in the SELECT query) used in index (in WHERE ) then mysql will not need to go far to find all the information you need.
The explanation is lengthy, but I summarize: try to only select things in WHERE, and how everything in WHERE is indexed , it saves a lot of random IO.
Refer to: http://planet.mysql.com/entry/?id=661727
Be careful with the query function
Many times in your query will use the calculation functions of mysql as addition and subtraction and multiplication, adding dates. With a fairly simple example below:
1 | SELECT field FROM table WHERE field + 1 = 5 |
Even if the field is indexed completely, mysql cannot use that index, the reason is simple, mysql is not smart enough to know that the query is equivalent to
1 | SELECT field FROM table WHERE field = 4 |
Should use auto increment for primary key
All of the above are for the biggest purpose: how to quickly query, or optimize the read operation. So how to manipulate write ( INSERT ) as fast as possible (or how to insert INSERT into fields with the fastest index). Back to the above definition of index, it is a tree, not a regular tree but a sorted tree. The difference between inserting a sorted data-structure and a non-sorted data-structure is that it is easy to insert into the non-sort guy, just insert the butt (like WAL, write ahead log), and insert into the guy If sorted, we need to find out where to insert it, then insert it, right: D.
From idea above we can easily give the conclusion that insert into a table that auto-increment primary key will be faster than insert into a table where the primary key is string uuid, the reason is as above, if index is autoincrement, it is too easy, mysql only need to insert it into the butt.
Null or not Null?
Mysql support for null values, ie there exists a state of no data. To support this state, mysql must save more information for each row (such as a field may be null or not), causing the data to bulge out. Therefore we should not use default null for all fields
Config buffer pool
Innodb uses a memory area called the buffer pool for the purpose of cache data and saving the index. This memory is stored in units of page (default is 16kb) and uses LRU algorithm to evict cache. Basically, the larger the buffer, the better =))). The bigger the buffer, the more cache the query will be, leading to a query that doesn't need to hit IO. How do you set the other apps to run on the same instance with enough memory to use: v.
Refer:
http://dba.stackexchange.com/questions/27328/how-large-should-be-mysql-innodb-buffer-pool-size
https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
http://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_page_size
How to use nginx for good
Nginx is a perfect solution that can help you with a lot of things, from reverse proxy, to static deliver files (such as css / js / image), to load balancing. Understanding what nginx can do, and what you can customize,
Remove the limitations in the kernel layer
To be able to make good use of nginx, sometimes there is a lot of limit on the kernel layer that was originally set up without matching. The settings I mentioned below are edited in /etc/sysctl.conf .
The first is net.core.somaxconn : This is the number of connection max that gets nginx queue (buffering) before processing. The more Access is -> nginx will not process it properly and the larger the buffer into the queue, the larger the queue, the more buffer, the less the block, will increase nginx relative
Next is net.ipv4.ip_local_port_range : When using nginx as a reverse proxy, each connection to the proxy will use an ephemeral port , so when access is much, it will quickly reach the port, leading to blocking. Increasing this index will help connect upstream more, less blocking
Next is sys.fs.file_max : This is the maximum number of file descriptors that the linux server can use, but as you know the linux socket is a file, so the larger the index, the more nginx opens the socket, will help for max connection increase.
Finally, net.ipv4.tcp_wmem and net.ipv4.tcp_rmem : these are the two indicators of kernel for buffering for TCP / IP. In general, the bigger the better =)).
Below is the config set that is recommended for nginx server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | net.ipv4.ip_local_port_range = '1024 65000' net.ipv4.tcp_tw_reuse = '1' net.ipv4.tcp_fin_timeout = '15 ' net.core.netdev_max_backlog = '4096' net.core.rmem_max = '16777216' net.core.somaxconn = '4096' net.core.wmem_max = '16777216' net.ipv4.tcp_max_syn_backlog = '20480' net.ipv4.tcp_max_tw_buckets = '400000' net.ipv4.tcp_no_metrics_save = '1' net.ipv4.tcp_rmem = '4096 87380 16777216' net.ipv4.tcp_syn_retries = '2' net.ipv4.tcp_synack_retries = '2' net.ipv4.tcp_wmem = '4096 65536 16777216' vm.min_free_kbytes = '65536' |
Analyze log nginx to find bottle neck
Analyzing log access from nginx will help you know where the bottle neck is, a very simple tool
https://github.com/matsuu/kataribe
To use this tool, you need to set nginx log format to use directive
1 2 3 4 | log_format with_time '$ remote_addr - $ remote_user [$ time_local]' '"$ request" $ status $ body_bytes_sent' "" $ http_referer "" $ http_user_agent "$ request_time '; access_log /var/log/nginx/access.log with_time; |
Caching with nginx
When using Nginx for static server files, you should pay close attention to cache settings, and compression. Setting using gzip for static files is also very important.
Using gzip will greatly reduce the cost associated with IO, and transmission. Setting cache control will help the server not to request that static file again until the cache expire. You can refer to the settings below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | http { gzip on; gzip_http_version 1.0; gzip_types text / plain text / html text / xml text / css application / xml application / xhtml + xml application / rss + xml application / atom_xml application / javascript application / x-javascript application / x-httpd-php; gzip_disable "MSIE [1-6]"; gzip_disable "Mozilla / 4"; gzip_comp_level 1; gzip_proxied any; gzip_vary on; gzip_buffers 4 8k; gzip_min_length 1100; |
Note: Thanks to @visudoblog added
When using nginx as a reverse proxy, if your memory is excessive, and the amount of data to respond to is not large, you can set to nginx cache on memory instead of on file
1 | proxy_cache_path / dev / shm / nginx levels = 1: 2 keys_zone = czone: 16m max_size = 32m inactive = 10m; |
Advance nginx
A setting is also very good to use keepalive. Normally keep alive is a technique of http that helps "keep" connection TCP even when HTTP connection session has ended, so that it can reuse for the next request. This technique is very useful when a user will normally send a lot of requests for static resources.

Using keepalive on nginx is as simple as adding a keepalive directive to the upstream section
1 2 3 4 | upstream app { server 127.0.0.1 tim000; keepalive 16; } |
Explore more
- http://www.mysql.gr.jp/frame/modules/bwiki/index.php?plugin=attach&refer=matsunobu&openfile=Session-Index.pdf
- Mastering nginx: https://www.google.co.jp/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=mastering%20nginx
- High performance mysql: https://www.amazon.co.jp/High-Performance-MySQL-Optimization-Replication/dp/1449314287
- http://www.nari64.com/?p=579
- https://www.nginx.com/blog/http-keepalives-and-web-performance/