Bắt đầu
Zipkin là gì? Zipkin là một hệ thống truy tìm phân tán. Và truy tìm là gì? Truy tìm là một kỹ thuật để ghi lại thông tin về một yêu cầu như đường dẫn thực hiện, độ trễ, lỗi là gì và cứ thế. Điều này mang lại cho bạn là khả năng khắc phục sự cố về hiệu năng như nút cổ chai, tình trạng ứng dụng xuất phát từ đâu, nguyên nhân là gì, cung cấp cho bạn tổng quan về toàn bộ ứng dụng của bạn và cho bạn thấy sự tương tác giữa mỗi dịch vụ từ bắt đầu đến cuối mỗi yêu cầu Techinique có thể áp dụng cho bất kỳ kiến trúc phần mềm nào, nhưng cực kỳ cần thiết cho một hệ thống phân tán.
Có rất nhiều thư viện ngoài kia có thể giúp bạn thêm nó vào hệ thống của bạn, nhưng những gì chúng ta sẽ xem xét trong bài viết này là thư viện có tên Zipkin . Trước khi chúng tôi bắt đầu, hãy để tôi làm rõ điều này trước. Zipkin không phải là một phần mềm mà chúng ta có thể chạy và mong đợi sẽ hoạt động một cách kỳ diệu. Nó là một công cụ và thư viện mà chúng tôi, nhà phát triển, phải thêm vào mã ứng dụng mà chúng tôi muốn theo dõi.
Ngành kiến trúc
Có 4 thành phần chính mà Zipkin cung cấp
- Người sưu tầm
- Dịch vụ truy vấn
- Lưu trữ
- Giao diện người dùng web
Trong một ứng dụng có các bộ theo dõi ghi dữ liệu về các hoạt động diễn ra. Họ thường làm việc cùng với các dịch vụ của chúng tôi và minh bạch cho người dùng. Mục tiêu chính của họ là thu thập dữ liệu từ dịch vụ của chúng tôi bằng cách thêm một mã định danh, được gọi là Trace ID , cùng với siêu dữ liệu tùy chỉnh mà chúng tôi muốn theo dõi. Dữ liệu này đang được thu thập được gọi là Span . Các nhịp hoàn thành được báo cáo cho Zipkin không đồng bộ bởi một Phóng viên . Phóng viên gửi dữ liệu theo dõi bằng cách sử dụng một trong các vận chuyển máy chủ.
Dưới đây là một sơ đồ để minh họa cách dữ liệu đến zipkin
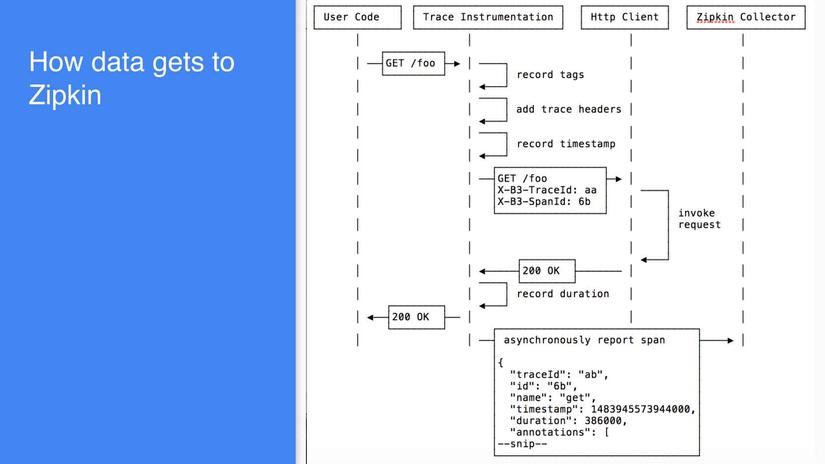
Người sưu tầm
Về cơ bản, đây là một dịch vụ chỉ cần ngồi ở đó và nhận dữ liệu từ phóng viên và lưu nó vào bộ lưu trữ liên tục, sau này sẽ được sử dụng bởi một dịch vụ truy vấn. Zipkin có ba phương tiện vận chuyển chính được tích hợp sẵn
- HTTP
- Kafka
- Ghi chép
Mặc dù có nhiều phần khác có sẵn dưới dạng phần mở rộng của bên thứ ba.
Dịch vụ truy vấn
Dữ liệu Trance, được lưu trữ và lập chỉ mục trong bộ lưu trữ, được trích xuất bởi trình nền truy vấn cung cấp API JSON đơn giản để tìm và truy xuất. Người tiêu dùng chính của API này là Giao diện người dùng web, nhưng có thể là bản dựng tùy chỉnh được điều chỉnh để phù hợp với một nhu cầu cụ thể.
Lưu trữ
Zipkin vốn hỗ trợ Cassandra , MySQL và ElSTERearhc là công cụ lưu trữ phụ trợ, nhưng như mọi công cụ khác đều có sẵn dưới dạng tiện ích mở rộng của bên thứ ba.
Giao diện người dùng web
Một máy khách web có giao diện đẹp để xem dấu vết. Bạn có thể truy vấn dữ liệu dựa trên tên dịch vụ, thời gian, chú thích hoặc thẻ.
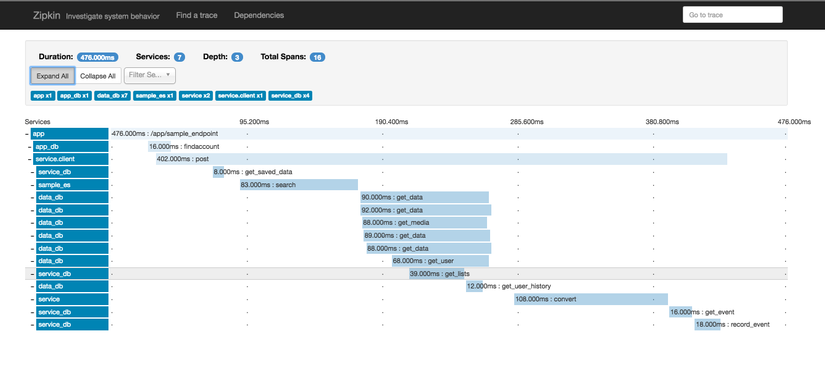
Đây là những gì bảng điều khiển trông giống như. Bạn có thể thấy thời lượng của mỗi dịch vụ được gọi và mối quan hệ của chúng.
Đang cài đặt
Docker
Cách nhanh nhất để tải và chạy zipkin là sử dụng hình ảnh docker dựng sẵn. Bạn có thể lấy nó bằng lệnh sau. Điều này sẽ kéo hình ảnh docker, quay nó trong nền và hiển thị nó trên cổng 9411
1 2 3 | $ docker pull openzipkin/zipkin $ docker run -d -p 9411:9411 openzipkin/zipkin |
Công cụ lưu trữ mặc định đi kèm với thư viện lõi là lưu trữ trong Bộ nhớ , để thay đổi nó thành elaticsearch, bạn có thể quay thùng chứa elaticsearch và đặt biến môi trường như trong tệp soạn thảo docker bên dưới.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <span class="token key atrule">version</span> <span class="token punctuation">:</span> <span class="token string">"3"</span> <span class="token key atrule">services</span> <span class="token punctuation">:</span> <span class="token key atrule">elasticsearch</span> <span class="token punctuation">:</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> openzipkin/zipkin <span class="token punctuation">-</span> elasticsearch <span class="token key atrule">zipkin</span> <span class="token punctuation">:</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> openzipkin/zipkin <span class="token key atrule">environment</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> STORAGE_TYPE=elasticsearch <span class="token punctuation">-</span> ES_HOSTS=elasticsearch <span class="token punctuation">:</span> <span class="token number">9200</span> <span class="token key atrule">ports</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> 9411 <span class="token punctuation">:</span> <span class="token number">9411</span> <span class="token key atrule">depends_on</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> elasticsearch6 |
Để biết thêm tài liệu kiểm tra cấu hình lưu trữ trên trang github của họ
Cái gì tiếp theo?
Điều này kết luận sự hiểu biết cơ bản và làm thế nào để có được zipkin và chạy. Trong bài viết tiếp theo, chúng tôi sẽ xem xét cách tích hợp nó với ứng dụng Go.