Hello mọi người đến hẹn lại lên =))). Ở bài viết Viblo lần này mình sẽ chia sẻ về một bài toán mà hầu hết các trang TMDT đều cần – Phân Khúc Khách Hàng. Tuy nhiên mình sẽ dùng model ML để giải quyết bài toán này.
Phân khúc khách hàng là việc tìm và lựa chọn nhóm khách hàng mà doanh nghiệp, tổ chức có khẳ năng thỏa mãn nhu cầu tốt hơn đối thủ cạnh tranh. mình tham khảo ở đây
Mục đích:
- Để lựa chọn khách hàng phù hợp và phục vụ một cách tốt nhất
- Tạo lợi thế cạnh tranh với các đối thủ trên thị trường
- Thấu hiểu khách hàng và khẳng định thương hiệu
Cách để phân khúc khách hàng mà các doanh nghiệp hiện nay đang thực hiện: - Địa lý
- Giới tính
- Độ tuổi
- Thu nhập.
Phân khúc khách hàng áp dụng ML
Dữ liệu
Ở đây mình có sử dụng dữ liệu dựa trên dữ liệu của 1 trang thương mại điện tử về giao dịch của khách hàng, mọi người có thể down tại đây
Đọc dữ liệu để xem data của chúng ta có những gì nào.
1 2 3 4 5 6 | import pandas as pd dataset = pd.read_csv('customerSpending.csv', header = 0, index_col = 0) print(dataset.shape) dataset.head() |
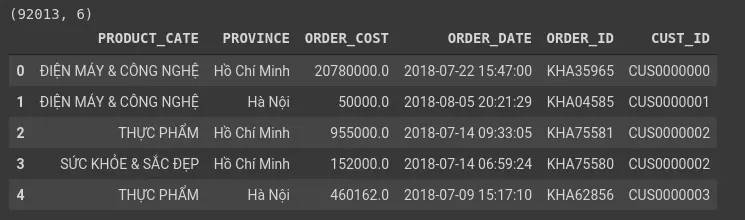
Dữ liệu của chúng ta bao gồm các trường:
- PRODUCT_CATE: Loại sản phẩm giao dịch
- PROVINCE: tỉnh thành giao dịch
- ORDER_COST: Giá sản phẩm
- ORDER_DATE: Thời gian order
- ORDER_ID: mã order
- CUST_ID: ID của khách hàng
Định dạng dữ liệu của các trường:
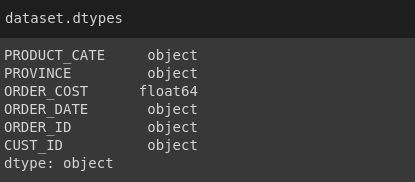
Ở đây trường ORDER_ID là quan trọng nhất nhé mn.
Preprocessing Data
Xử lý và convert lại data
Đầu tiên chúng ta sẽ convert datetime từ Object về định dạng Datetime64.
1 2 3 4 5 6 7 8 9 | from datetime import datetime def strToDatetime(x): return datetime.strptime(x, '%Y-%m-%d %H:%M:%S') # Kiểm tra định dạng các trường của pandas dataframe print(dataset.dtypes) # Convert dữ liệu về đúng định dạng dataset['ORDER_DATE'] = dataset['ORDER_DATE'].apply(strToDatetime) dataset.dtypes |
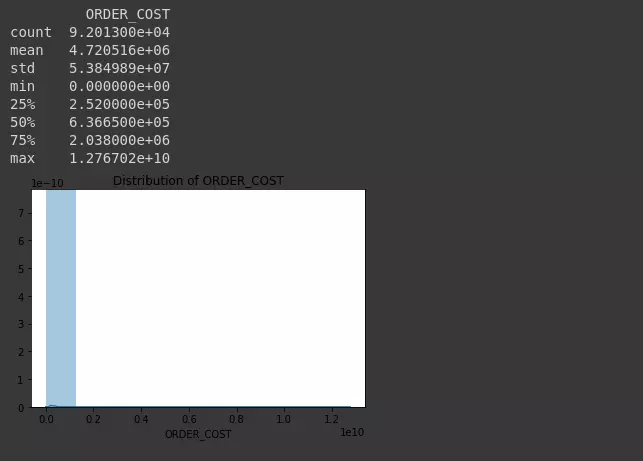
Tiếp theo chúng ta cũng thử vẽ ra biểu đồ phân phối các biến nhé (bins =10)
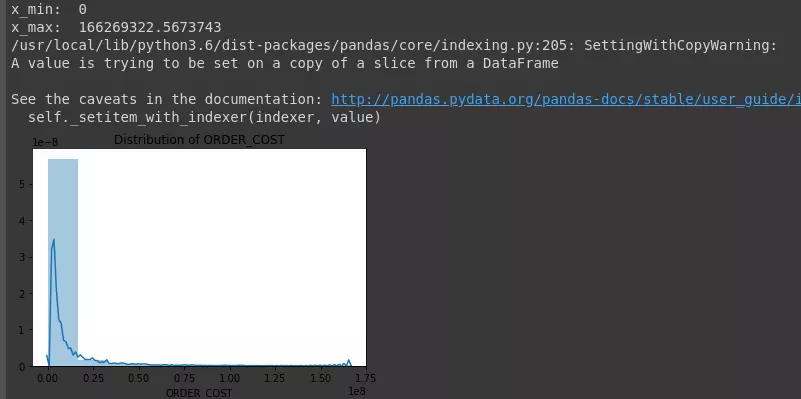
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # Thống kê mô tả print(dataset.describe()) # Vẽ biểu đồ phân phối các biến import seaborn as sns import matplotlib.pyplot as plt def plotNumeric(colname, n_bins = 10, hist = True, kde = True): sns.distplot(dataset[colname], hist = hist, kde = kde, bins = n_bins) plt.title('Distribution of {}'.format(colname)) plt.show() plotNumeric('ORDER_COST', hist = True, kde = True, n_bins = 10) |
Xác định các điểm outlier của biến giá trị đơn hàng “ORDER_COST” dựa trên nguyên lý 3 sigma. Theo nguyên lý 3 sigma thì 99.75% giá trị đơn hàng sẽ nằm trong khoảng từ:
outliers là những điểm được xác định nằm ngoài khoảng giá trị trên.
1 2 | dataset.loc[[1, 2]]['ORDER_COST'] |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def fillOutlier(colname): mu = np.mean(dataset[colname]) sigma = np.std(dataset[colname]) x_min = max(mu - 3*sigma, 0) x_max = mu + 3*sigma print('x_min: ', x_min) print('x_max: ', x_max) out_lower_id = dataset[dataset[colname] < x_min].index out_upper_id = dataset[dataset[colname] > x_max].index dataset[colname].loc[out_lower_id] = x_min dataset[colname].loc[out_upper_id] = x_max fillOutlier('ORDER_COST') plotNumeric('ORDER_COST', hist = True, kde = True, n_bins = 10) |
Thống kê tổng giá trị theo “PRODUCT_CATE” ứng với “CUST_ID”.
1 2 3 4 5 6 7 8 9 10 | dfSummary = pd.pivot_table(data = dataset, values = ['ORDER_COST', 'ORDER_ID'], index = ['CUST_ID'], columns = ['PRODUCT_CATE'], aggfunc= {'ORDER_COST': np.sum} ) print(dfSummary.shape) dfSummary.head() |

Sau khi thống kê xong chúng ta sẽ fill các giá trị na nhé, ở đây mình fillna bằng 0 nha.
1 2 3 4 5 6 7 8 | from sklearn.preprocessing import StandardScaler dfSummary.fillna(0, inplace = True) scaler = StandardScaler() scaler.fit(dfSummary) X = scaler.transform(dfSummary) |
Training Model
Chia tập train và tập test nha mn mình chia 80/20:
1 2 3 4 5 | from sklearn.model_selection import train_test_split X_train, X_test, id_train, id_test = train_test_split(X, np.arange(X.shape[0]), test_size = 0.2) |
Xây dựng model Kmeans mọi người có thể tham khảo KMean ở đây nhé
1 2 3 4 5 6 7 8 9 10 11 12 | from sklearn.cluster import KMeans # Khởi tạo mô hình kmean cluster với số cluster từ 2->16 kmeans = [] wcss = [] for i in np.arange(2, 17, 1): km_i = KMeans(n_clusters=i,init='k-means++', max_iter=300, n_init=10, random_state=0) km_i.fit(X_train) wcss.append(km_i.inertia_) kmeans.append(km_i) |
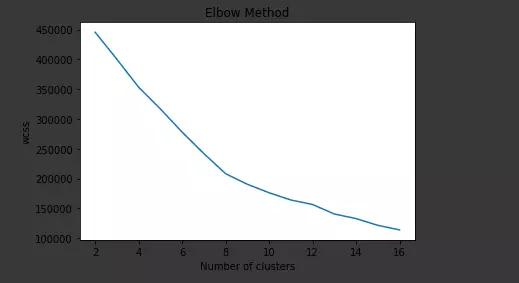
wcss: đo lường sự sai lệch đến điểm centerpoints. Khi làm số lượng clusster làm cho chỉ số wcss giảm không đáng kể thì ta có thể lựa chọn
1 2 3 4 5 6 7 8 | # Vẽ biểu đồ wcss vs n_clusters plt.plot(np.arange(2, 17),wcss) plt.title('Elbow Method') plt.xlabel('Number of clusters') plt.ylabel('wcss') # plt.ylim(0, 800000) plt.show() |
Visualize các nhóm clusters:
Đầu tiên mình sẽ sử dụng tnse để giảm chiều dữ liệu từ 9 xuống 2:
1 2 3 4 5 6 | from sklearn.manifold import TSNE import time time_start = time.time() tsne = TSNE(n_components=2, verbose=1, perplexity=40, n_iter=300) tsne_results = tsne.fit_transform(X_train) |
Tiếp theo là Visualize:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | X_ = tsne_results y_label = kmeans[7].predict(X_train) plt.figure(figsize = (12, 8)) plt.scatter(X_[y_label==0,0],X_[y_label==0,1],s=50, c='purple',label='Cluster1') plt.scatter(X_[y_label==1,0],X_[y_label==1,1],s=50, c='blue',label='Cluster2') plt.scatter(X_[y_label==2,0],X_[y_label==2,1],s=50, c='green',label='Cluster3') plt.scatter(X_[y_label==3,0],X_[y_label==3,1],s=50, c='cyan',label='Cluster4') plt.scatter(X_[y_label==4,0],X_[y_label==4,1],s=50, c='yellow',label='Cluster5') plt.scatter(X_[y_label==5,0],X_[y_label==5,1],s=50, c='brown',label='Cluster6') plt.scatter(X_[y_label==6,0],X_[y_label==6,1],s=50, c='purple',label='Cluster7') plt.scatter(X_[y_label==7,0],X_[y_label==7,1],s=50, c='pink',label='Cluster8') # plt.scatter(X_[y_label==8,0],X_[y_label==8,1],s=50, c='orange',label='Cluster9') # plt.scatter(X[y_means==4,0],X[y_means==4,1],s=50, c='yellow',label='Cluster5') # plt.scatter(kmeans_7.cluster_centers_[:,0], kmeans_7.cluster_centers_[:,1],s=100,marker='s', c='red', alpha=0.7, label='Centroids') plt.scatter(kmeans[7].cluster_centers_[:,0], kmeans[7].cluster_centers_[:,1],s=100,marker='s', c='red', alpha=0.7, label='Centroids') plt.title('Customer segments') plt.xlabel('tsne-2d-one') plt.ylabel('tsne-2d-two') plt.legend() plt.show() |
cùng xem xem kết quả như thế nào nha mọi người:
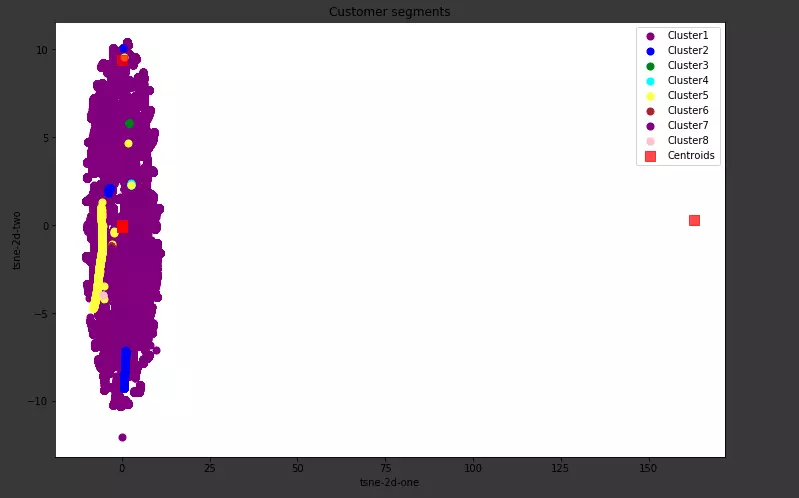
Ở trên mình sử dụng Kmeans để phân khúc khách hàng hoặc mọi người có thể tham khảo bài của Anh Khánh về RFM ở đây sử dụng mô hình RFM (Recency – Frequency – Monetary model) để phân khúc khách hàng bằng rank.
- Khách hàng VIP: rank từ 8-10.
- Khách hàng đại chúng: rank từ 5-7.
- Khách hàng thứ cấp: rank < 5.
Mọi người tham khảo code RFM tại đây nhé
Kết Luận
Bài toán customer segmentation khá phổ biến đối với TMDT để góp phần đánh đúng vào nhu cầu khách hàng hơn. Tuy nhiên bài toán của mình khá là đơn giản hi vọng mọi người có thể góp ý để những bài viết của mình tốt hơn.
Reference
https://machinelearningcoban.com/2017/01/01/kmeans/
https://phamdinhkhanh.github.io/2019/11/08/RFMModel.html