Apache Hadoop or Hadoop is a software framework that supports data-intensive applications under a free license. It allows the application to work with thousands of computers that compute independently and petabytes of data. Hadoop is derived from articles MapReduce by Google and Google File System.
Hadoop is only powerful when it is set up and deployed on a cluster of multiple machines, but to get familiar with Hadoop, you can use Hadoop Single Node to get familiar with Hadoop commands, configuration, … You can follow the instructions below to install Hadoop Single Node:Installation Instructions for Hadoop Single Node

To be able to run a Java program on Hadoop, you must build it into a jar file and then run that jar file on hadoop. This article I will guide in detail on how to build the program to a jar file and run it on Hadoop (I will run on Hadoop Single Node, running on Hadoop Multi Node with Single Node is the same, just different from the configuration step. deploying clusters only)
First of all, I have a WordCount project here: WordCount project . You clone project first, the project is the maven project so you just need to clone it, import it into the IDE that you use and it will automatically update the required library.
I explain a bit about this project for everyone to understand, WordCount is a problem of calculating the frequency of occurrence of a word in a text or an input text set, this problem is a classic Hadoop problem. Mapreduce . My project has 2 input parameters which are the path to the input file and the path where the output file is located.
In the pom.xml file, I will configure the hadoop-common and hadoop-hdfs . More importantly, to build the project to the jar file, you must add the following lines and between the 2 <plugins> tags:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <executions> <execution> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <archive> <manifest> <mainClass> com.hadoop.mapreduce.WordCount </mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </execution> </executions> </plugin> |
In which between the two <mainClass> tags must be the path to the Class containing your main function (the project WordCount you clone about, I have added it fully, you can follow in the project and you just clone. ).
If you use a different version of jdk than jdk-11, please pay attention to the maven-compiler-plugin :
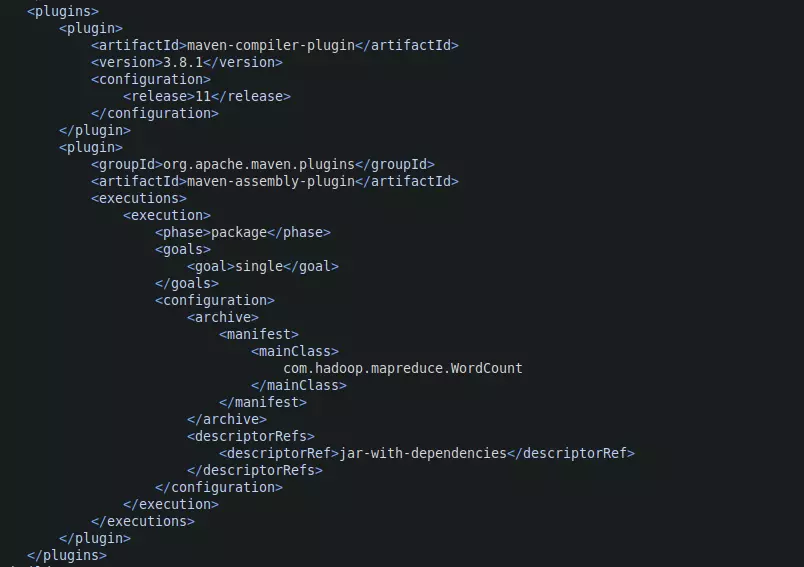
Between the 2 tags <release> please change to match your version. For example, if you are using jdk-15, change the number 11 to 15. If you are using Java 8 it is a little more complicated. Remove the <release> tag and add between the 2 <configuration> tags are the following 2 tags:
1 2 3 | <source>1.8</source> <target>1.8</target> |
Create jar file with maven
To build jar file with maven, open a terminal and go to the root directory of that project and run the command:
1 2 | mvn clean package |
The results of the program will look like this:
(Currently the word BUILD SUCCESS as above is built successfully)
Start Hadoop
Of course, to run on Hadoop, you have to start Hadoop first (followthe instructions to install Hadoop Single Node above by yourself). After booting you run the command jps to check, if there are enough 6 daemons as below, it has successfully booted:
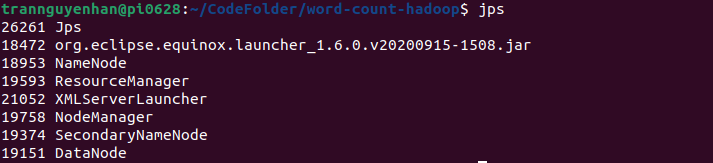
(the org.eclipse …. jar I should not pay much attention to it, only the other 6)
Run the WordCount jar file on Hadoop
Before running, we have to prepare the input data first, in the Project we have an input.txt file, we use this file as a file, now must push it to HDFS with the following command:
1 2 | hdfs dfs -copyFromLocal input.txt / |
Verify that it was successful by checking the files and folders in HDFS with the command:
1 2 | hdfs dfs -ls / |
Or you can also see the UI tool directly at: http://localhost:9870/explorer.html#
Now, to run the jar file WordCount, run the following command:
1 2 | hadoop jar target/wordcount-V1.jar com.hadoop.mapreduce.WordCount hdfs://localhost:9001/input.txt hdfs://localhost:9001/output |
Inside :
target/wordcount-V1.jaris the path to the WordCount jar filecom.hadoop.mapreduce.WordCountis the path to theClasslocation containing themainfunctionhdfs://localhost:9001/input.txtis the input file path in HDFS [1]hdfs://localhost:9001/outputis the path of the directory where the output [2][1] and [2] are 2 parameters that I specified in Project, in your Project you can set the parameters as you like, you can fix the output hard and only get 1 input parameter. Just input is also completely OK. It is also important that because I have a port conflict, I have my Hadoop HDFS configuration on port 9001 (usually port 9000), so if you configured HDFS at port 9000 then edit the path above tolocalhost:9000
After running an ouput directory will be generated on HDFS you can access http://localhost:9870/explorer.html# to check, the results will be as follows:
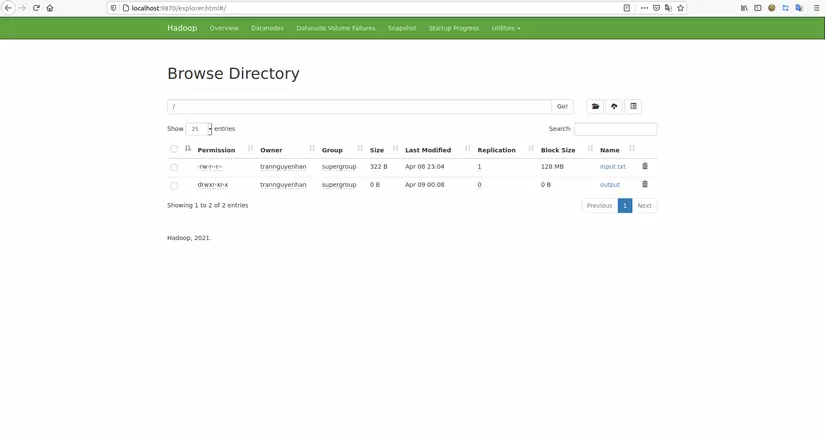
(Sometimes it spawns a / tmp directory, so whatever it is)
Run the following command to check the results:
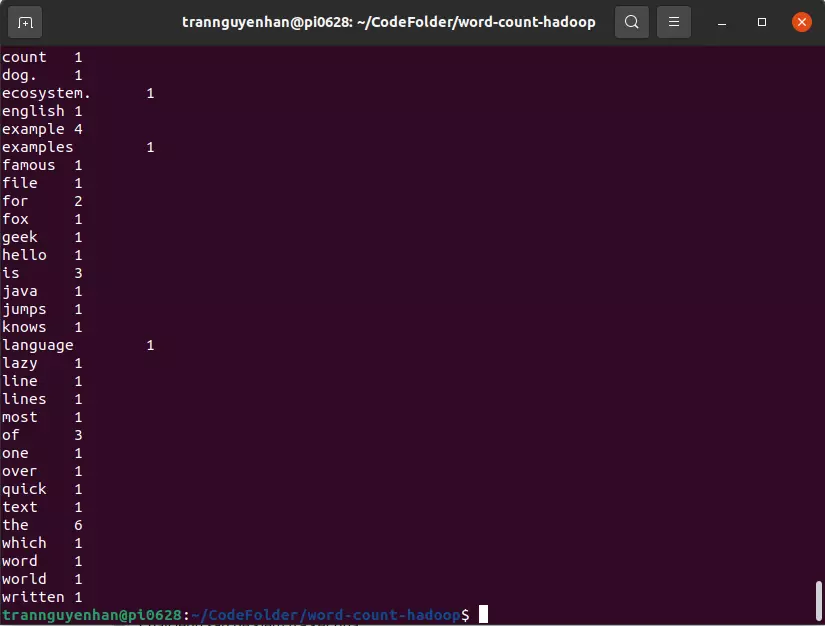
1 2 | hdfs dfs -cat /output/part-r-00000 |
The displayed results will be as follows:
See the full source code at the link github : https://github.com/trannguyenhan/word-count-hadoop
Reference: hadoop.apache.org ,tailieubkhn.com