1. Lời mở đầu
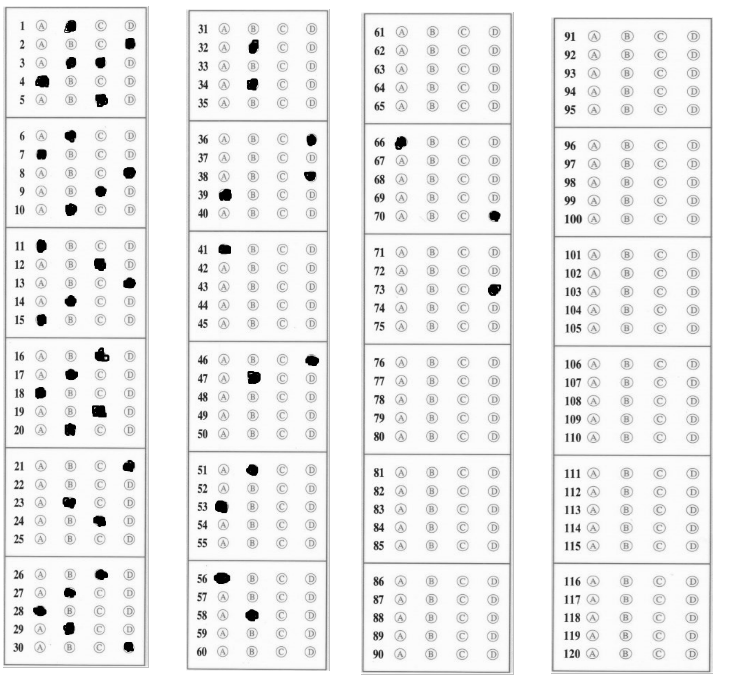
Xin chào các bạn, tiếp tục nối tiếp các bài viết về xử lý ảnh bằng OpenCV như Nhận diện biển số xe Việt Nam, Corner Detection, Edge Detection, …. Hôm nay mình xin tiếp tục giới thiệu cho các bạn phương pháp chấm điểm bài thi trắc nghiệm bằng OpenCV. Mẫu đề trắc nghiệm tương đối đa dạng nhưng trong bài viết lần này mình lấy mẫu chính là đề thi trung học phổ thông quốc gia năm 2020 gồm 120 câc. Các bạn click trực tiếp và tải về ảnh bên dưới đây để cùng làm với mình nhé.

Ảnh 1: Đề thi trung học phổ thông quốc gia năm 2020
2. Các bước thực hiện
Ở mẫu đề thi lần này chúng ta có 120 câu hỏi được chia thành 4 cột. Mỗi cột có 6 ô, mỗi ô có 5 câu hỏi. Và ở mỗi câu hỏi ta có 4 đáp án: “A”, “B”, “C”, “D” và một điều đặc biệt nữa là một câu hỏi có thể có nhiều hơn 1 đáp án. Sau khi nắm được tổng quát cấu trúc đầu vào, mình chia cách giải quyết bài toán gồm các bước sau:
- Xử lý ảnh đầu vào tách ra 4 cột đáp án
- Chia mỗi cột đáp án ra thành 6 box, mỗi box lại chia tiếp lấy ra 5 câu hỏi
- Xử lý từng câu hỏi để lấy ra các hình tròn chứa đáp án (bubble choice)
- Sử dụng model CNN tiến hành phân loại đáp án đó có được tô hay không ?
2.1 Xử lý ảnh đầu vào tách ra 4 cột đáp án
Do mỗi cột đáp án có viền hồng liền nhau bao xung quang bốn cạnh nên ta có thể dùng hàm cv2.findContour() của OpenCV. Nhắc lại một chút về khái niệm , Contour chính là những nét liền nhau bao quanh những khối, hình và hàm cv2.findContour sẽ tìm và trả về cho ta những nét như thế. Để áp dụng được hàm này, đầu tiên ta chuyển ảnh đọc vào thành dạng GRAY, sử dụng GaussianBlur để giảm bớt nhiễu, sau đó áp dụng sử dụng thuật toán Canny Edge Detection để phát hiện ra các cạnh có trong ảnh đầu vào. Cuối cùng ta mới có thể dùng hàm cv2.findContours .
1 2 3 4 5 6 7 8 9 10 11 12 13 | <span class="token comment"># convert image from BGR to GRAY to apply canny edge detection algorithm</span> gray_img <span class="token operator">=</span> cv2<span class="token punctuation">.</span>cvtColor<span class="token punctuation">(</span>img<span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>COLOR_BGR2GRAY<span class="token punctuation">)</span> <span class="token comment"># remove noise by blur image</span> blurred <span class="token operator">=</span> cv2<span class="token punctuation">.</span>GaussianBlur<span class="token punctuation">(</span>gray_img<span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token number">5</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">)</span> <span class="token comment"># apply canny edge detection algorithm</span> img_canny <span class="token operator">=</span> cv2<span class="token punctuation">.</span>Canny<span class="token punctuation">(</span>blurred<span class="token punctuation">,</span> <span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">200</span><span class="token punctuation">)</span> <span class="token comment"># find contours</span> cnts <span class="token operator">=</span> cv2<span class="token punctuation">.</span>findContours<span class="token punctuation">(</span>img_canny<span class="token punctuation">.</span>copy<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>RETR_TREE<span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>CHAIN_APPROX_SIMPLE<span class="token punctuation">)</span> cnts <span class="token operator">=</span> imutils<span class="token punctuation">.</span>grab_contours<span class="token punctuation">(</span>cnts<span class="token punctuation">)</span> |
Để chuẩn bị cho phần sau, ta xây dựng một hàm nhận đầu vào là một contour và trả về diện tích của hình chữ nhật bao quanh contour đó :
1 2 3 4 | <span class="token keyword">def</span> <span class="token function">get_x_ver1</span><span class="token punctuation">(</span>s<span class="token punctuation">)</span><span class="token punctuation">:</span> s <span class="token operator">=</span> cv2<span class="token punctuation">.</span>boundingRect<span class="token punctuation">(</span>s<span class="token punctuation">)</span> <span class="token keyword">return</span> s<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">*</span> s<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> |
Và một hàm nhận đầu vào list, mỗi phần tử trong list có dạng [image, (x, y, w, h)] và trả về tọa độ x:
1 2 3 | <span class="token keyword">def</span> <span class="token function">get_x</span><span class="token punctuation">(</span>s<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">return</span> s<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> |
Tiếp tục phần xử lý, nếu cv2.findContours phát hiện được contour (len(cnts) > 0), ta sử dụng hàm cv2.boundingRect để có thể lấy ra tọa độ (xmin, ymin) cũng như chiều dài và rộng của hình chữ nhật bao quanh contour. Vì chúng ta sẽ thu được vô số các contour do trong hình ta có vô số nét liền nhau chữ chữ, bảng, ….. Do đó để lấy ra 4 cột chúng ta mong muốn có diện tích lớn hơn hẳn so với các hình khối khác nên mình sử dụng điều kiện diện tích của contour đó phải lớn hơn 100000 (con số này tùy thuộc vào bài toán các bạn điều chỉnh cho phù hợp ).
Chú ý, đôi khi cv2.findCoutours() sẽ trả về những contour trùng nhau một phần hoặc toàn bộ, chúng có thể cùng tọa độ (xmin, ymin) nhưng (xmax, ymax) khác nhau hoặc ngược lại. Mình đã sắp xếp list contours theo chiều giảm dần diện tích và kiểm tra trùng nhau (overlap) bằng hai biến check_xy_min và check_xy_max để đảm bảo thu được những contour tốt nhất diện tích lớn nhất và không trùng nhau.
Trước khi kết thúc bước này, ta sắp xếp lại một lần nữa 4 cột ta thu được theo chiều từ trái sang phải đảm bảo thứ tự để tiện xử lý ở các bước sau.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | ans_blocks <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> x_old<span class="token punctuation">,</span> y_old<span class="token punctuation">,</span> w_old<span class="token punctuation">,</span> h_old <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">0</span> <span class="token comment"># ensure that at least one contour was found</span> <span class="token keyword">if</span> <span class="token builtin">len</span><span class="token punctuation">(</span>cnts<span class="token punctuation">)</span> <span class="token operator">></span> <span class="token number">0</span><span class="token punctuation">:</span> <span class="token comment"># sort the contours according to their size in descending order</span> cnts <span class="token operator">=</span> <span class="token builtin">sorted</span><span class="token punctuation">(</span>cnts<span class="token punctuation">,</span> key<span class="token operator">=</span>get_x_ver1<span class="token punctuation">)</span> <span class="token comment"># loop over the sorted contours</span> <span class="token keyword">for</span> i<span class="token punctuation">,</span> c <span class="token keyword">in</span> <span class="token builtin">enumerate</span><span class="token punctuation">(</span>cnts<span class="token punctuation">)</span><span class="token punctuation">:</span> x_curr<span class="token punctuation">,</span> y_curr<span class="token punctuation">,</span> w_curr<span class="token punctuation">,</span> h_curr <span class="token operator">=</span> cv2<span class="token punctuation">.</span>boundingRect<span class="token punctuation">(</span>c<span class="token punctuation">)</span> <span class="token keyword">if</span> w_curr <span class="token operator">*</span> h_curr <span class="token operator">></span> <span class="token number">100000</span><span class="token punctuation">:</span> <span class="token comment"># check overlap contours</span> check_xy_min <span class="token operator">=</span> x_curr <span class="token operator">*</span> y_curr <span class="token operator">-</span> x_old <span class="token operator">*</span> y_old check_xy_max <span class="token operator">=</span> <span class="token punctuation">(</span>x_curr <span class="token operator">+</span> w_curr<span class="token punctuation">)</span> <span class="token operator">*</span> <span class="token punctuation">(</span>y_curr <span class="token operator">+</span> h_curr<span class="token punctuation">)</span> <span class="token operator">-</span> <span class="token punctuation">(</span>x_old <span class="token operator">+</span> w_old<span class="token punctuation">)</span> <span class="token operator">*</span> <span class="token punctuation">(</span>y_old <span class="token operator">+</span> h_old<span class="token punctuation">)</span> <span class="token comment"># if list answer box is empty</span> <span class="token keyword">if</span> <span class="token builtin">len</span><span class="token punctuation">(</span>ans_blocks<span class="token punctuation">)</span> <span class="token operator">==</span> <span class="token number">0</span><span class="token punctuation">:</span> ans_blocks<span class="token punctuation">.</span>append<span class="token punctuation">(</span> <span class="token punctuation">(</span>gray_img<span class="token punctuation">[</span>y_curr<span class="token punctuation">:</span>y_curr <span class="token operator">+</span> h_curr<span class="token punctuation">,</span> x_curr<span class="token punctuation">:</span>x_curr <span class="token operator">+</span> w_curr<span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token punctuation">[</span>x_curr<span class="token punctuation">,</span> y_curr<span class="token punctuation">,</span> w_curr<span class="token punctuation">,</span> h_curr<span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># update coordinates (x, y) and (height, width) of added contours</span> x_old <span class="token operator">=</span> x_curr y_old <span class="token operator">=</span> y_curr w_old <span class="token operator">=</span> w_curr h_old <span class="token operator">=</span> h_curr <span class="token keyword">elif</span> check_xy_min <span class="token operator">></span> <span class="token number">20000</span> <span class="token keyword">and</span> check_xy_max <span class="token operator">></span> <span class="token number">20000</span><span class="token punctuation">:</span> ans_blocks<span class="token punctuation">.</span>append<span class="token punctuation">(</span> <span class="token punctuation">(</span>gray_img<span class="token punctuation">[</span>y_curr<span class="token punctuation">:</span>y_curr <span class="token operator">+</span> h_curr<span class="token punctuation">,</span> x_curr<span class="token punctuation">:</span>x_curr <span class="token operator">+</span> w_curr<span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token punctuation">[</span>x_curr<span class="token punctuation">,</span> y_curr<span class="token punctuation">,</span> w_curr<span class="token punctuation">,</span> h_curr<span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># update coordinates (x, y) and (height, width) of added contours</span> x_old <span class="token operator">=</span> x_curr y_old <span class="token operator">=</span> y_curr w_old <span class="token operator">=</span> w_curr h_old <span class="token operator">=</span> h_curr <span class="token comment"># sort ans_blocks according to x coordinate</span> sorted_ans_blocks <span class="token operator">=</span> <span class="token builtin">sorted</span><span class="token punctuation">(</span>ans_blocks<span class="token punctuation">,</span> key<span class="token operator">=</span>get_x<span class="token punctuation">)</span> |
Kết quả sau phần này ta sẽ thu được một list chứa 4 cột đáp án đã được sắp xếp theo chiều từ trái sang phải :
2.2 Từ mỗi cột đáp án lấy ra các câu hỏi
Sau khi thu được một list 4 cột đáp án ở bước trên, ở đây ta thực hiện một vòng lặp qua list 4 cột đáp án(ans_blocks) để có thể xử lý từng cột.
Đối với mỗi cột để thu được danh sách câu hỏi cần được xử lý qua 2 bước:
- Bước 1: Chia cột ra 6 box nhỏ: Do 6 box này có kích thước bằng nhau nên chỉ cần lấy chiều cao của cột chia 6 ta sẽ thu được chiều cao của từng box (offset1) và dễ dàng thu được từng box như mong muốn
- Bước 2: Chia mỗi box ra thành 5 câu hỏi: Ở đây ta cần để ý một chút đó là khoảng cách các cạnh trên dưới của một box và 5 câu hỏi trong box đó không cách đều nhau do đó ta không thể chia ngay được. Trong bài toán này, để giải quyết vấn đề chênh lệch đó mình thu gọn kích thước hai đầu trên dưới của 1 box bằng câu lệnh ” box_img = box_img[14:height_box-14, :]”. Sau đó ta chia chiều cao của box cho 5 (5 ở đây là 5 câu hỏi ) ra chiều cao của một câu hỏi, từ đó lấy được từng câu hỏi.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | <span class="token keyword">def</span> <span class="token function">process_ans_blocks</span><span class="token punctuation">(</span>ans_blocks<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token triple-quoted-string string">""" this function process 2 block answer box and return a list answer has len of 200 bubble choices :param ans_blocks: a list which include 2 element, each element has the format of [image, [x, y, w, h]] """</span> list_answers <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token comment"># Loop over each block ans in</span> <span class="token keyword">for</span> ans_block <span class="token keyword">in</span> ans_blocks<span class="token punctuation">:</span> ans_block_img <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>ans_block<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span> offset1 <span class="token operator">=</span> ceil<span class="token punctuation">(</span>ans_block_img<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">/</span> <span class="token number">6</span><span class="token punctuation">)</span> <span class="token comment"># Loop over each box in answer block</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">6</span><span class="token punctuation">)</span><span class="token punctuation">:</span> box_img <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>ans_block_img<span class="token punctuation">[</span>i <span class="token operator">*</span> offset1<span class="token punctuation">:</span><span class="token punctuation">(</span>i <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">)</span> <span class="token operator">*</span> offset1<span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">]</span><span class="token punctuation">)</span> height_box <span class="token operator">=</span> box_img<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> box_img <span class="token operator">=</span> box_img<span class="token punctuation">[</span><span class="token number">14</span><span class="token punctuation">:</span>height_box<span class="token operator">-</span><span class="token number">14</span><span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">]</span> offset2 <span class="token operator">=</span> ceil<span class="token punctuation">(</span>box_img<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">/</span> <span class="token number">5</span><span class="token punctuation">)</span> <span class="token comment"># loop over each line in a box</span> <span class="token keyword">for</span> j <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">:</span> list_answers<span class="token punctuation">.</span>append<span class="token punctuation">(</span>box_img<span class="token punctuation">[</span>j <span class="token operator">*</span> offset2<span class="token punctuation">:</span><span class="token punctuation">(</span>j <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">)</span> <span class="token operator">*</span> offset2<span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">return</span> list_answers |
Kết quả chúng ta sẽ thu được từng câu hỏi của mỗi box. Ví dụ :

2.3 Xử lý từng câu hỏi để lấy ra các hình tròn chứa đáp án (bubble choice)
Sau khi thu được kết quả ở bước trên là một list các câu hỏi đã được sắp xếp, ta thực hiện xử lý để lấy ra các ô đáp án.
Để giải quyết vấn đề này, ta có hai giải pháp :
- Sử dụng các thuật toán phát hiện ra đường tròn để lấy trực tiếp ra các ô đáp án.Ưu điểm : Cách này không phải dùng các biến cố định để chia ô như phương pháp 2 mình sẽ giới thiệu bên dưới, ổn định trong các trường hợp cần phải align lại do nghiêng,….
Nhược điểm : Nếu không may chúng ta bắt thiếu mất một ô hay ta bắt nhầm thêm một dị vật có kích thước như ô (thí sinh nghịch tô vài nét trong giấy thi….) thì sẽ dẫn đến sai toàn bộ phần chấm đáp án do mất thứ tự nên không biết câu nào với câu nào.
- Chia cố định lấy ra từng ô đáp ánƯu điểm : Bạn sẽ thoải mái không lo mất ô đáp án nào cả vì kiểu gì bạn cũng lấy được ô đó ra nhờ chia bằng những thông số cố định
Nhược điểm : Tuy nhiên để chọn được ra những tọa độ cố định bạn phải mất công thử sao cho phù hợp với bài toán đầu vào của mình và kém linh hoạt hơn khi bị nghiêng lệch….(có thể khắc phục bằng cách sử dụng align image xoay thẳng lại ảnh )
Do bài toán của mình đầu vào là ảnh có được bằng cách scan file pdf trực tiếp không sợ bị nghiêng lệch nên mình chọn phương án thứ . Chú ý do ở mỗi câu hỏi ngoài các ô đáp án còn chứa số thứ tự câu như 1, 2, 3… nên để có thể chia đều để lấy ra các ô đáp án giống như các bước phía trên thì ta sử dụng hai biến : start để loại bỏ phần đầu câu chứa số thứ tự câu và offset dùng để chia đều lấy ra các ô đáp án giống cách sử dụng offset ở các bước trước nhưng khác một chỗ ở bước này áp dụng cho chiều rộng không phải chiều cao do các ô đáp án trải đều theo chiều rộng.
Chúng ta cần phải lấy ngưỡng bằng cách sử dụng threshold đưa ảnh về dạng đen trắng để chỉ tập trung vào những đặc trưng cần thiết và reshape chúng thành ảnh có kích thước (28, 28, 1) phù hợp mạng CNN dùng để phân loại ở bước sau ta sử dụng.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | <span class="token keyword">def</span> <span class="token function">process_list_ans</span><span class="token punctuation">(</span>list_answers<span class="token punctuation">)</span><span class="token punctuation">:</span> list_choices <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> offset <span class="token operator">=</span> <span class="token number">44</span> start <span class="token operator">=</span> <span class="token number">32</span> <span class="token keyword">for</span> answer_img <span class="token keyword">in</span> list_answers<span class="token punctuation">:</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">4</span><span class="token punctuation">)</span><span class="token punctuation">:</span> bubble_choice <span class="token operator">=</span> answer_img<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> start <span class="token operator">+</span> i <span class="token operator">*</span> offset<span class="token punctuation">:</span>start <span class="token operator">+</span> <span class="token punctuation">(</span>i <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">)</span> <span class="token operator">*</span> offset<span class="token punctuation">]</span> bubble_choice <span class="token operator">=</span> cv2<span class="token punctuation">.</span>threshold<span class="token punctuation">(</span>bubble_choice<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">255</span><span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>THRESH_BINARY_INV <span class="token operator">|</span> cv2<span class="token punctuation">.</span>THRESH_OTSU<span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> bubble_choice <span class="token operator">=</span> cv2<span class="token punctuation">.</span>resize<span class="token punctuation">(</span>bubble_choice<span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token number">28</span><span class="token punctuation">,</span> <span class="token number">28</span><span class="token punctuation">)</span><span class="token punctuation">,</span> cv2<span class="token punctuation">.</span>INTER_AREA<span class="token punctuation">)</span> bubble_choice <span class="token operator">=</span> bubble_choice<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token number">28</span><span class="token punctuation">,</span> <span class="token number">28</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">)</span> list_choices<span class="token punctuation">.</span>append<span class="token punctuation">(</span>bubble_choice<span class="token punctuation">)</span> <span class="token keyword">if</span> <span class="token builtin">len</span><span class="token punctuation">(</span>list_choices<span class="token punctuation">)</span> <span class="token operator">!=</span> <span class="token number">480</span><span class="token punctuation">:</span> <span class="token keyword">raise</span> ValueError<span class="token punctuation">(</span><span class="token string">"Length of list_choices must be 480"</span><span class="token punctuation">)</span> <span class="token keyword">return</span> list_choices |
Sau khi thực hiện được bước này ta thu được một danh sách gồm 480 ô đáp án (120 câu hỏi * 4 ô ). Các ô thu được gồm hai loại : tô và chưa tô

2.4 Sử dụng model CNN tiến hành phân loại đáp án đó có được tô hay không ?
Các bạn có thể tự cắt các ô ra train lại hoặc sử dụng trực tiếp pretrained weight với model ở trong github của mình. Đầu tiên mình khởi tạo một dictonary result để lưu giữ kết quả. Với mỗi score hay confidence score trong list scores mà model predict, nếu confidence score mà lớn hơn 0.9 thì ô đã được tô và lấy ra kết quả “A”, “B”, “C”, “D” tương ứng bằng cách truyền số thứ tự của ô đó trong list vào map_answer(). Hàm này tương đối đơn giản các bạn có thể vào xem trong github của mình nhé
Nhờ vào việc cứ confidence score lớn hơn 0.9 thì nó sẽ là đáp án đã được tô nên cho phép xử lý một câu có nhiều hơn một đáp án. Hơn nữa các đặc trưng của các ô được tô hay không tô rất rõ nét nên trường hợp nhận nhầm xác suất rất thấp, độ chính xác của model mình train có 2, 3 epoch batch size=32 nhưng đã đạt 100% trên cả tập train và val rồi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <span class="token keyword">def</span> <span class="token function">get_answers</span><span class="token punctuation">(</span>list_ans<span class="token punctuation">)</span><span class="token punctuation">:</span> results <span class="token operator">=</span> defaultdict<span class="token punctuation">(</span><span class="token builtin">list</span><span class="token punctuation">)</span> model <span class="token operator">=</span> CNN_Model<span class="token punctuation">(</span><span class="token string">'weight.h5'</span><span class="token punctuation">)</span><span class="token punctuation">.</span>build_model<span class="token punctuation">(</span>rt<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">)</span> list_ans <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>list_ans<span class="token punctuation">)</span> scores <span class="token operator">=</span> model<span class="token punctuation">.</span>predict_on_batch<span class="token punctuation">(</span>list_ans <span class="token operator">/</span> <span class="token number">255.0</span><span class="token punctuation">)</span> <span class="token keyword">for</span> idx<span class="token punctuation">,</span> score <span class="token keyword">in</span> <span class="token builtin">enumerate</span><span class="token punctuation">(</span>scores<span class="token punctuation">)</span><span class="token punctuation">:</span> question <span class="token operator">=</span> idx <span class="token operator">//</span> <span class="token number">4</span> <span class="token comment"># score [unchoiced_cf, choiced_cf]</span> <span class="token keyword">if</span> score<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span> <span class="token operator">></span> <span class="token number">0.9</span><span class="token punctuation">:</span> <span class="token comment"># choiced confidence score > 0.9</span> chosed_answer <span class="token operator">=</span> map_answer<span class="token punctuation">(</span>idx<span class="token punctuation">)</span> results<span class="token punctuation">[</span>question<span class="token operator">+</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">.</span>append<span class="token punctuation">(</span>chosed_answer<span class="token punctuation">)</span> <span class="token keyword">return</span> results |
Và tèn tén ten, hàm này sẽ trả về cho 120 câu hỏi cùng đáp án của nó. Những câu hỏi không được bất cứ ô nào được tô sẽ không được có danh sách này nhé.
1 2 3 4 5 6 | defaultdict(<class 'list'>, {1: ['B'], 2: ['D'], 3: ['B', 'C'], 4: ['A'], 5: ['C'], 6: ['B'], 7: ['A'], 8: ['D'], 9: ['C'], 10: ['B'], 11: ['A'], 12: ['C'], 13: ['D'], 14: ['B'], 15: ['A'], 16: ['C'], 17: ['B'], 18: ['A'], 19: ['C'], 20: ['B'], 21: ['D'], 23: ['B'], 24: ['C'], 26: ['C'], 27: ['B'], 28: ['A'], 29: ['B'], 30: ['D'], 32: ['B'], 34: ['B'], 36: ['D'], 38: ['D'], 39: ['A'], 41: ['A'], 46: ['D'], 47: ['B'], 51: ['B'], 53: ['A'], 56: ['A'], 58: ['B'], 66: ['A'], 70: ['D'], 73: ['D']}) |
3. Kết luận
Bài toán chấm điểm phiếu trắc nghiệm tuy đơn giản nhưng là một bài toán thích hợp cho những bạn nào định tập tành với OpenCV. Với cách giải quyết bài toán như trên của mình, cho phép chấm được những câu hỏi có nhiều đáp án và không lo vấn đề bị thiếu câu hay đán án so với cách sử dụng findContours. Đồng thời nó cũng nhanh hơn nhiều so với các phương pháp bằng Deep Learning thuần.Hy vọng bài viết của mình có thể giúp ích cho các bạn. Ở trên đây mình mới chỉ giới thiệu các ý chính còn chi tiết hơn về cách code bạn có thể xem tại link github tại đây của mình. Nhớ like and subscribe để theo dõi tiếp những bài viết của mình nhé