The reason why Uber has to switch from Postgres to MySQL
Introduction
At first, Uber uses monolithic backend application written in Python and uses Postgres to data consistency. After a while, the structure of Uber has changed markedly, to the new microservices and data platform models. In particular, in many cases of using Postgres before, it is now possible to resolve with Schemaless (the new database sharding layer is built on MySQL). In this article, we'll explore some of the drawbacks when Uber still uses Postgres, and explains why Schemaless and other backend services are built on MySQL.
Postgres structure
Postgres limitations that Uber faces:
- Inefficient architecture for write queries
- Data replication is not effective
- Errors related to table corruption
- Poor MVCC backup support
- Difficult to update the new version
We will explore in detail these limitations through Postgres manifest data that are analyzed from data tables and indexes on the hard drive, especially when compared to the way MySQL represents. Data type with InnoDB storage engine . Note, the data here is mainly based on Uber activity with the old version of Postgres 9.2.
On-Disk Format
A relational database must perform the following tasks:
- Allow insert / update / delete
- Allow schema changes
- Deploy mechanism for multiversion concurrency control (MVCC, so that different connections have transactional view of corresponding data.
Envisioning the combination of these features is an essential part of having to design how the database displays data on the hard drive.
Immutable row data is also an essential design aspect of Postgres. In Postgres parlance, these constant data rows are called "tuples". These tuples are uniquely identified by ctid . A ctid represents the on-disk location (such as physical disk offset) of a tuple. Many ctids can describe a single row (such as when multiple versions of a row exist for MVCC purposes; or when the old version of the row has not yet been taken over by the autovacuum process). A set of tuples that will be arranged, will form a table. Tables themselves have indexes, arranged in a binary tree structure (usually B-trees) that map index fields to a ctid containing all of its corresponding data.
Usually, these citds are very clear to users. Once you know how the citd works, you can understand the on-disk structure of Postgres tables. To see the existing ctid of the row, you can add ctid to the column list in the WHERE clause:
1 2 3 4 5 6 7 | uber @ [local] uber => SELECT ctid, * FROM my_table LIMIT 1; - [RECORD 1] -------- + ------------------------------ ctid | (0.1) ... các trường khác này ... |
For a detailed explanation, see the following simple user table examples. For each user, we have auto-incrementing user ID primary key (primary key, user ID increment when inserting), user name, year of user. We also define the compound secondary index based on the user 's full name, and another secondary index based on the user' s year of birth. Here is DDL (data definition language) to create such a table:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | CREATE TABLE users ( id SERIAL, first TEXT, last TEXT, birth_year INTEGER, PRIMARY KEY (id) ); CREATE INDEX ix_users_first_last ON users (first, last); CREATE INDEX ix_users_birth_year ON users (birth_year); |
Notice the three indexes in this definition include: the primary key index and the two secondary indexes defined.
To the example in the article, we have the following table, including the data aggregate famous mathematicians of history:
| id | first | last | birth_year |
| first | Blaise | Pascal | 1623 |
| 2 | Gottfried | Leibniz | 1646 |
| 3 | Emmy | Noether | 1882 |
| 4 | Muhammad | al-Khwārizmī | 780 |
| 5 | Alan | Turing | 1912 |
| 6 | Srinivasa | Ramanujan | 1887 |
| 7 | Ada | Lovelace | 1815 |
| 8 | Henri | Poincaré | 1854 |
As mentioned, each row contains an independent ctid. Therefore, we can look at the table above in the following way:
| ctid | id | first | last | birth_year |
| A | first | Blaise | Pascal | 1623 |
| B | 2 | Gottfried | Leibniz | 1646 |
| C | 3 | Emmy | Noether | 1882 |
| D | 4 | Muhammad | al-Khwārizmī | 780 |
| E | 5 | Alan | Turing | 1912 |
| F | 6 | Srinivasa | Ramanujan | 1887 |
| G | 7 | Ada | Lovelace | 1815 |
| HOUR | 8 | Henri | Poincaré | 1854 |
The primary key index helps map ids to ctids, defined as follows:
| id | ctid |
| first | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | HOUR |
The B-tree is defined on the id field, and each node in the B-tree contains the ctid value. Notice, in this case, the sort order of the fields in the B-tree is naturally the same as the order in the table, that is because we use the id itself to increase itself.
Two secondary indexes look similar; The main difference is that these fields are stored in a different order, because B-trees must be sorted according to the lexicographical order (a form of alphabetical order Alphabet). Index (first, last) starts with the name (first) at the top of the alphabet down:
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | HOUR |
| Muhammad | al-Khwārizmī | D |
| Srinivasa | Ramanujan | F |
Similarly, the index birth_year is sorted in descending order:
| birth_year | ctid |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | HOUR |
| 1887 | F |
| 1882 | C |
| 1912 | E |
As you can see, in both cases, the ctid field in the corresponding secondary index does not increase in Alphabet order, unlike the case of increasing itself in the primary key.
Suppose, we need to update a record in this table. For example, updating the year of birth for another year of al-Khwārizmī's birth year, 770 AD. And as we said, tuples are immutable. Therefore, to update the record, we have to add a new tuple to the table. This tuple has a new hidden ctid, which is called I. Postgres needs to distinguish the new tuple I and the old tuple D. Postgres is contained in each tuple with a version field and a pointer to the previous tuple (if any). Thus, the new structure of the table is as follows:
| ctid | prev | id | first | last | birth_year |
| A | null | first | Blaise | Pascal | 1623 |
| B | null | 2 | Gottfried | Leibniz | 1646 |
| C | null | 3 | Emmy | Noether | 1882 |
| D | null | 4 | Muhammad | al-Khwārizmī | 780 |
| E | null | 5 | Alan | Turing | 1912 |
| F | null | 6 | Srinivasa | Ramanujan | 1887 |
| G | null | 7 | Ada | Lovelace | 1815 |
| HOUR | null | 8 | Henri | Poincaré | 1854 |
| I | D | 4 | Muhammad | al-Khwārizmī | 770 |
As long as there are two versions of al-Khwārizmī row, indexes must contain entries for both rows. To ensure brevity, we will remove the primary key index and display only the secondary index here, as follows:
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | HOUR |
| Muhammad | al-Khwārizmī | D |
| Muhammad | al-Khwārizmī | I |
| Srinivasa | Ramanujan | F |
| birth_year | ctid |
| 770 | I |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | HOUR |
| 1887 | F |
| 1882 | C |
| 1912 | E |
We have shown the old red version and the new green version. The truth is, Postgres uses another field to keep the version of the row, to determine which tuple is the latest. This extra field helps the database determine which tuple of the row will participate in the transaction process (may not be allowed to see the latest version of the row).
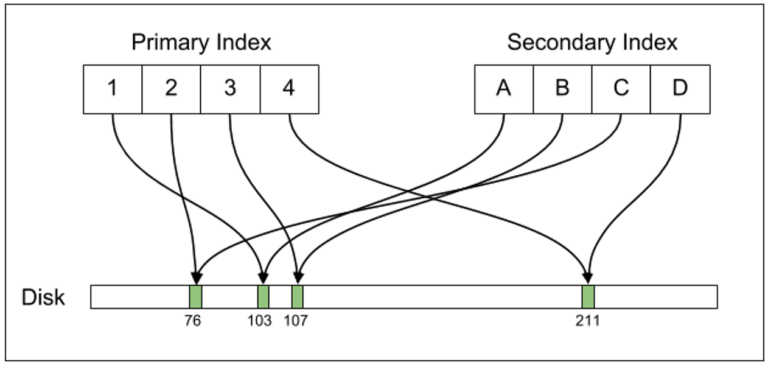
Replication
When we import a new row into the table, Postgress needs to back up, if streaming replication is open. To ensure data recovery when crashing, Uber's database has maintained a write-ahead log (WAL) and uses the WAL to implement two-phase commits . The database must maintain this WAL even when streaming backup is not open, because the WAL is necessary for the safety and durability of ACID .
When researching events that occur when the database crashes unexpectedly (such as when a power failure occurs suddenly), we can understand more about the WAL. The WAL is like a "household book" that records changes that the database intends to perform on the table's on-disk content and index. When the Postgres service is active, the process compares the data in this household book with the actual data on the hard drive. If the household book contains data that is not reflected on the hard drive, the database will correct all tuples or index data to reflect the data indicated by the WAL. After that, the database will continue to rollback any data that appears on the WAL, but from the partially applied transaction (ie the transaction has never been done).
Postgres executes streaming backups by sending the WAL on the main database to backups. Every database backs up immediately as if it were in a crash recovery state, continuously applying WAL updates. The only difference between streaming backup and crash recovery is actually the "hot standby" mode, making read queries when applying streaming WAL. While Postgres, if indeed in crash recovery mode, often refuses to receive any queries until the database instance has completed the crash recovery process.
Because the WAL is in fact designed for crash recovery purposes, it contains low-level information about on-disk updates. The content of the WAL is at the level of showing the actual on-disk of row tuples and their disk offsets (eg row ctids). If you pause a main Postgres and copy, when the copy is completely finished, the actual on-disk content on the replica will exactly match the content on the original to each byte. Therefore, tools like rsync can fix a corrupted copy if the copy is out of date compared to the original.
Consequences from Postgres's design
Postgres's design is ineffective and causes a shortage of data for the data team at Uber .
Write Amplification
The first problem with Postgres's design is also called write amplification . Typically, write amplication refers to the problem with data written to SSD disks: small logical updates (only a few bytes) are suddenly heavier, more expensive when translated to the physical layer. Amplifier recorded in Postgres is no different. In the example before we edit the logical update to the al-Khwārizmī birth year, we must perform at least four physical updates:
- Write tuple for new rows in tablespace
- Update the primary key index to add records to the new tuple
- Update (first
,last) index to add records to the new tuple - Updating the index birth_year
deals more records into the new tuple
In fact, these updates only reflect the writes in the main tablespace, each of which needs to be reflected on the WAL, so the total write on the hard drive is even larger.
The point here is that updates 2 and 3. When we update the year of birth for al-Khwārizmī, we don't actually change his primary key, or change their last name. However, these parameters still need to be updated, with the creation of a new row tuple in the database for the row record. For tables with a large number of secondary indexes, these extra steps make the system more visible. For example, if we have a table with a unique index defined on it, updating (to the field only by an index) must be scaled up to 12 indexes to reflect the new ctidcho.
Replication
This recording amplification problem also automatically switches to the replication layer, because the backup process occurs at the level of on-disk changes. Instead of having to back up a small logical record, such as "Change the year of birth for the ctid D to 770, "instead, the database writes our WAL entries for all the four writes listed above, and these 4 WAL entries will replication to even bring the remaining net. Therefore, the recording amplification problem also turns into a problem of copy amplification, and the Postgres replication data stream will quickly become extremely massive, capable of taking up a large amount of bandwidth. .
In cases where backing up Postgres merely happens to a single data center, the bandwidth for backup will not matter. Modern network devices and switches can handle large amounts of bandwidth, and many hosting providers support low-cost intra-data center bandwidth. , even free. However, when the backup process has to take place between many different data centers, we'll be in big trouble. For example, Uber initially used physical servers at a rental location on the West Coast. To facilitate disaster recovery, Uber added more servers in the East Coast (also hired). Under this design, Uber has a main Postgres instance (plus duplicates) in the Western data center and a series of eastern replicas.
Backup in Cascading limits the inter-data center bandwidth requirement to the number of backups needed between only the master and a single copy, even if there are multiple copies in the data second center. However, the "bulk" of the backup protocol in Postgres can still create a large amount of data for the database to have too many indexes. The cost of high-bandwidth multinational links is extremely expensive, and even when money is abundant, it's hard to get a strong multinational link like a local network. Bandwidth problems also make it difficult to store WAL. Instead of having to send all WAL updates from West Coast to East Coast, Uber stores them on file hosting web services, both of which are aimed at ensuring data storage for disaster prevention, and for WALs. Stored can give many new copies from database snapshots. At the time of peak traffic, Uber's bandwidth to storage web service is not fast enough to meet the writing speed of WALs.
Data Corruption
During a periodic upgrade of the main database to increase capacity, Uber encountered an error on Postgres 9.2. Copies of timeline switches are not in the right direction , resulting in a number of copies that misuse the WAL records. Because of this error, some records that should have been marked by the versioning mechanism are marked as inactive, which is not the case.
The following query describes how this bug affects the example table we are considering:
1 | SELECT * FROM users WHERE id = 4; |
This query will return two records: the original al-Khwārizmī row (with 780 CE birth years), and the new al-Khwārizmī row (with 770CE birth year). If we add ctid to the where list, we will see the different ctid values for the two returned records.
This problem is extremely uncomfortable for many reasons, First, we cannot easily know how many rows this problem has affected. Duplicate results returned by the database cause application logic to fail in many cases. We have come up with more defensive programming statements to determine which tables will have problems. Because bugs affect all servers, corrupted rows will be different from replica instances (ie backup cases), which means that a copy of row X may still be good but the Y row is broken. In fact, Uber is also unsure of the number of copies with corrupted data, and whether the problem affects the original version.
However, Uber said, maybe the problem only happens with a few rows on the database. They are also concerned because the backup process takes place at the physical level, so the indexes in the database risk being completely destroyed. B-trees have an important characteristic, they must be continuously rebalanced (re-balancing), and these rebalancing operations can completely change the structure of the whole tree because of sub-trees. be transferred to the new on-disk location. If the data is not transferred correctly, most plants will become completely "waste".
In the end, Uber also traced out the cause of the bug, and determined that the main database has just been upgraded with no broken items. Uber fixes this problem on copies, by synchronizing all copies from the original snapshot, a tiring process; they only have enough resources to process a few copies at once.
Uber only encountered this bug only in Postgres 9.2 before being fully processed in future versions. However, they are still quite cautious, because this type of error consumes a lot of time and money. If the next release version appears again, plus the extra working style depends on this copy, the problem can completely spread to all databases.
Replica MVCC
Postgres does not really support MVCC backup. When copies apply WAL updates, they will have an on-disk copy that is the same as the original . Uber sees the problem here.
Postgres must maintain a copy of the old version of the version for MVCC. If a streaming backup has an open transaction, updates to the database will be blocked if they affect the rows held by the transaction. In this case, Pestgres pauses WAL application thread (the line responsible for applying the WAL) until the transaction ends. This will be a big problem if the transaction takes too much time, because the copy can lag behind the original very much. Therefore, Postgres applies timeouts in this case: if a transaction blocks the application of the WAL for a specified period of time , Postgres will cancel that transaction.
This design means that duplicates can often go back to the original for a few seconds, and so it's easy to write code that causes many transactions to be canceled. This problem may not be obvious to application developers (code coders have a beginning and end of a rather blind transaction). For example, suppose a programmer has a code with the task of emailing a receipt to the user. Based on the way of writing, the code may implicitly hold the database transaction kept open until after the email is sent. Leaving 'database-keeping code' open while executing 'irrelevant I / O' is always more harmful than good, but it seems that in fact most engineers are not databse experts so they don't know The problem, especially when using ORM, opens up low-level details like open transactions.
Postgres Upgrades
Since backup records work at the physical level, it is not possible to back up data between different Postgres versions. The main database running Postgres 9.3 cannot back up a copy running on Postgres 9.2, or vice versa.
Uber applies the following way to update this version of Postgres GA to another GA version:
- Shut down the main database.
- Run the pg_upgrade
command on the main database, update this master data. For large databases, this stage can take many hours and cannot handle traffic from the main database. - Open the main database again.
- Create a snapshot of the main database. This step completely copies all data from the main database, so it takes many hours for the large database.
- Wipe each copy and restore the new snapshot from the original to the copy.
- Bring each copy back to the backup system. Waiting for the copy to be completely responsive to the update from the original, has been restored.
Uber started with Postgress 9.1 and successfully completed the update process to switch to Postgres 9.2. However, the process takes too much time, plus company-scale development when Postgres 9.3 appears, the conversion time will be longer. For this reason, Uber's legacy Postgres instances are still running 9.2 so far, even though 9.5 Postgres GA is currently available.
If you are running Postgress 9.4 or lower, you can use pglogical , which adds the logical replication layer to Postgres. When using pglogical, you can back up data between different Postgres versions. In other words, you can upgrade from 9.4 to 9.5 without suffering from downtime for too long. This way of doing things is still a dead end because pglogical is not integrated into Postgres's mainline tree, and pglogical is not an option for Postgres users in the older version.
MySQL structure
Not only discussing Postgres limitations, Uber also explains the importance of MySQL for new Uber projects (like Schemaless). In many cases, Uber feels MySQL is more suitable. To see the difference, Uber studies the structure of MySQL and collects it with Postgress. More specifically, how MySQL interacts with the InnoDB storage engine .
InnoDB On-Disk Representation
Like Postgres, InnoDB supports advanced features like MVCC and mutable data. We won't talk about on-disk format, but about the basic differences with Postgres.
The most important structural difference is: Postgress directly maps index records to on-disk locations, while InnnoDB maintains the secondary structure. Instead of keeping the pointer to the on-disk row location (such as ctid in Postgres), the secondary indexo record will keep the pointer to the primary key value. Therefore, secondary indexes in MySQL will link index keys to primary keys:
| first | last | id (primary key) |
| Ada | Lovelace | 7 |
| Alan | Turing | 5 |
| Blaise | Pascal | first |
| Emmy | Noether | 3 |
| Gottfried | Leibniz | 2 |
| Henri | Poincaré | 8 |
| Muhammad | al-Khwārizmī | 4 |
| Srinivasa | Ramanujan | 6 |
To make index lookup up (first, last) index, we need to have two lookups. Lookup first scans in the table and finds the primary key index to find the on-disk location for the row.
As such, InnoDB is slightly less advantageous than Postgres when implementing the secondary lookup, since both indexes must be searched with InnoDB compared to just an index like Postgres. However, because the data is simplified, row updates only need to update the index records actually changed by the row update. In addition, InnoDB often performs row updates in place. If old transactions need to reference a row to serve MVCC, MySQL will copy the old row into a special area called a rollback segment .
Let's see what happens when we update al-Khwārizmī's birth year. If there is enough space, the year of birth in the row with id 4 will be updated in place (in fact, this update always takes place in place, since the birth year is an integer that occupies a specific amount of space) . Index year of birth is also updated in place to reflect the new day. The old row's data is copied to the rollback segment. The primary key index does not need to be updated, so is the name index. If we have a large number of indexes on this table, we only have to update the indexes that actually index on the birth_year field. So suppose we have indexes on fields like signup_date, last_login_time, ... We don't need to update these indexes, while Postgres needs to update.
This design also helps vacuuming and compaction more effectively. All items that are eligible for vacuum will be available directly in the rollback segment. By comparison, Postgres autovacuum process must perform a full table scan to identify deleted items.
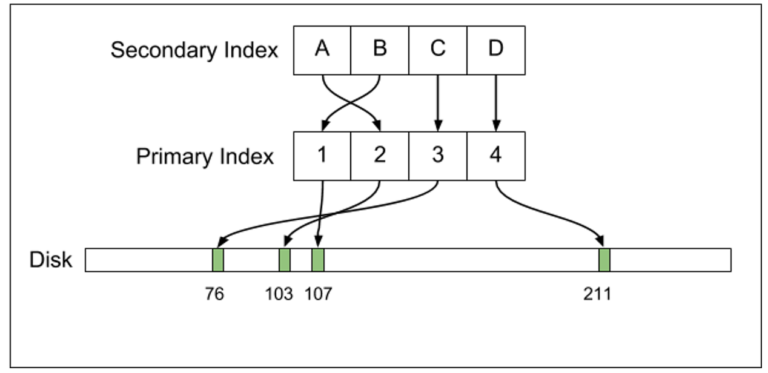
Replication
MySQL supports many different backup modes :
- Statement-based replication (backup copy-based) backup logical SQL statements (for example, immediate backup of text commands such as: UPDATE users SET birth_year = 770 WHERE id = 4
) - Row-based replication backs up the changed records
- Mixed replication combines the above two modes
These backup modes have different benefits and harms. Command-based replicas are often the most compact, but require copies to apply many expensive statements to update only small amounts of data. In other words, row-based backups, similar to WALL backups in Postgress, are often more cumbersome, but bring more efficient and predictable copy updates.
In MySQL, only the primary index has a pointer to the on-disk offset of the row. This causes quite important consequences to the copy. The MySQL replication stream (MySQL replication stream) only contains information about logical update to the row. Replica updates are for the variety "Change the X timestamp from T_1 to T_2. ”Based on the results of these statements, the copies automatically conclude that any changes in the index need to be performed.
In contrast, Postgres replication stream contains physical changes, such as "at disk offset 8,382,491, writing bytes XYZ." With Postgres, every physical change made to the hard drive needs to be included. into the WAL stream. Minor logic changes (such as updating a timestamp) further increase the importance of on-disk changes: Postgres must import new tubes and update all indexes to point to that tuple. Therefore, many changes will be placed into the WAL stream. This different design point means that the MySQL replica binary log will be somewhat more compact than PostgreSQL WAL stream.
The operation of each backup stream also has a serious effect on how MVCC works with duplicates. Because the Postgres backup stream has logical updates, replicas can have MVCC semantics; Therefore read queries on replicas will not block backup streams. In contrast, the Postgres WAL stream contains on-disk physical changes, so Postgres replicas cannot apply replication updates that conflict with read queries, so they cannot deploy MVCC.
With MySQL's backup structure, if the bug causes table corruption, the problem will often cause serious errors. The backup process usually takes place at the logical layer, so some operations such as using B-tree will not cause the index to fail. The ignored statement (or applied twice) is a typical MySQL backup issue. This may cause data to be lost or invalid, but will not cause database loss.
Finally, MySQL's backup structure is not so important to back up between different MySQL versions. MySQL points to the version if the backup format changes; between MySQL versions, this is quite unusual. MySQL's logical backup format also indicates that on-disk changes in the storage engine layer do not affect the backup format. Cách thường dùng để nâng cấp MySQL là: áp dụng bản update đến từng bản sao lưu một, và khi đã up hết tất cả sao lưu, bạn hãy thăng cấp một bản sao bất kỳ lên làm bản chính. Cách này vừa giúp nâng caoas MySQL thật đơn giản, vừa không mất downtime.
Một số thế mạnh khác của MySQL
Đến đây, ta đã tập trung vào cấu trúc on-disk của Postgres và MySQL. Bên cạnh đó, MySQL vẫn còn một số thế mạnh khác so với Postgres
Buffer Pool
Trước hết, ở hai database này, caching làm việc rất khác. Postgres cấp phát một phần bộ nhớ cho internal cache, nhưng những cache này thường rất nhỏ khi so sánh với tổng lượng bộ nhớ của bộ máy. Để tăng hiệu năng, Postgres cho phép kernel tự động cache disk data đã truy cập gần đây, thông qua page cache . Ví dụ như, các bản sao Postgres lớn nhất có 768 GB bộ nhớ, nhưng thực sự chỉ có 25GB bộ nhớ đó là RSS memory bị các Postgres process gây lỗi. Như vậy, ta còn đến hơn 700 GB bộ nhớ dành cho Linux page cache.
Vấn đề với thiết kế này là: truy cập data qua page cache lại tốn kém hơn truy cập bộ nhớ RSS. Để tra cứu data từ ổ cứng, Postgres process sẽ phát các system call lseek(2) và read(2) để cấp phát data. Mỗi system call sẽ phải chịu một context switch, context switch này thường đắt đỏ hơn việc truy cập data từ main memory. Trong thực tế, Postgres cũng không hoàn toàn quá tối ưu về mặt này: Postgres không tận dụng system call pread(2) , kết hợp hai thao tác seek + read` thành một system call duy nhất.
Sau khi đối chiếu, InnoDB storage engine (công cụ lưu trữ InnoDB) sẽ tự thực thi LRU của nó trong InnoDB buffer pool . Khá giống với Linux page cache nhưng được thực thi trong userspace. InnoDB buffer pool, tuy phức tạp hơn thiết kế của Postgres, nhưng lại có nhiều thế mạnh lớn:
- Có thể tích hợp custom LRU design, như: ta có thể xác định các pathological access patterns (mô hình truy cập bệnh lý) có khả năng thổi bay LRU, và hạn chế thiệt hại xuống thấp nhất.
- Ít dính đến context switch hơn. Data được truy cập thông qua InnoDB buffer pool không yêu cầu bất cứ user/kernel context switch nào. Trường hợp phản ứng tệ nhất là sự xuất hiện của TLB miss , khá rẻ và có thể được giảm thiểu với huge pages .
Connection Handling
Thông qua việc spawn thread-per-connection, MySQL có thể thực hiện các concurrent connection (kết nối đồng thời). Cách này ít overhead hơn; mỗi thread sẽ dành một phần memory overhead cho stack place, cộng thêm một số bộ nhớ được cấp phát trên heap cho connection-specific buffers (buffer riêng cho connection). Cũng không quá bất ngờ khi MySQL đạt quy mô đến 10.000 concurrent connection. Bản thần nhiều MySQL instance của Uber cũng đã gần đạt đến con số này.
Tuy nhiên, Postgres lại dùng thiết kế process-per-connection, tốn kém hơn thread-per-connection nhiều. Việc fork một process (mới) chiếm dụng nhiều bộ nhớ hơn là spawn thread mới. Hơn nữa, IPC giữa các process cũng tốn kém hơn giữa thread nhiều. Postgres 9.2 sử dụng các primitive System V IPC cho IPC, thay vì futexes gọn nhẹ với thread. Futexes cũng nhanh hơn System V IPC vì trong trường hợp futex không được thỏa mãn, ta thường sẽ không cần phải tạo context switch nữa.
Bên cạch các vấn đề về bộ nhớ và IPc overhead, Postgres nhìn chung hỗ trợ rất kém trong việc xử lý lượng lớn kết nối, ngay cả khi vẫn còn đủ bộ nhớ. Uber cũng đã rất chật vật khi phải mở rộng quá trăm kết nối với Postgres. Tài liệu rất khuyến khích sử dụng cơ chế pooling kết nối out-of-process, để xử lý lượng lớn kết nối trong Postgres, nhưng lại không đưa ra lý do tại sao lại làm vậy. Theo đó, Uber cũng đạt được kha khá thành công khi sử dụng pgbouncer để thực hiện connection pooling trong Postgres. Tuy nhiên, họ vẫn thi thoảng gặp phải application bugs trong các dịch vụ backend, khiến các dịch vụ này phải mở thêm active connections (tường là kết nối “idle in transaction”) hơn mức cần thiết; từ đó khiến downtime càng lâu hơn.
Epilogue
Trong giai đoạn đầu của Uber, Postgres đã hoàn thành xuất sắc nhiệm vụ của mình, nhưng lại tỏ ra không phù hợp khi công ty mở rộng quy mô. Hiện nay, tuy Uber vẫn còn một vài legacy Postgres instance, nhưng phần lớn database đã chuyển sang MySQL (kết hợp với Schemaless layer), hoặc các database NoSQL (như Cassandra) trong các trường hợp đặc biệt. Nhìn chung, Uber hiện đang “ăn nằm” rất tốt với MySQL.
Hy vọng thông qua bài viết, các bạn đã phần nào biết được các set up cho một business có quy mô lớn như Uber, hẹn gặp lại các bạn trong các bài viết chuyên sâu tiếp theo.
ITZone via Uber