Lý do khiến Uber phải chuyển từ Postgres sang MySQL
Introduction
Mới đầu, Uber sử dụng ứng dụng backend nguyên khối được viết bằng Python và sử dụng Postgres để nhất quán dữ liệu. Sau một thời gian, cấu trúc của Uber đã có sự thay đổi rõ rệt, sang mô hình microservices và các data platform mới. Đặc biệt, trong nhiều trường hợp dùng đến Postgres trước đây, hiện đã có thể giải quyết bằng Schemaless (database sharding layer mới cóng được xây dựng trên MySQL). Trong bài viết này, ta sẽ khám phá một vài khuyết điểm khi Uber vẫn còn dùng Postgres, và giải thích lý do vì sao phải xây dựng Schemaless và các dịch vụ backend khác trên nền MySQL.
Cấu trúc của Postgres
Những hạn chế của Postgres mà Uber gặp phải:
- Kiến trúc không hiệu quả cho các truy vấn ghi vào (write)
- Data replication không hiệu quả
- Các lỗi liên quan tới table corruption
- Hỗ trợ sao lưu MVCC nghèo nàn
- Khó cập nhật phiên bản mới
Ta sẽ tìm hiểu chi tiết những hạn chế này thông qua số liệu biểu hiện của Postgres được phân tích từ bảng dữ liệu (data table) và chỉ mục (index) trên ổ cứng, đặc biệt khi so sánh với cách MySQL thể hiện cùng loại data với InnoDB storage engine. Lưu ý, các số liệu ở đây chủ yếu dựa trên hoạt động của Uber với phiên bản Postgres 9.2 cũ.
On-Disk Format
Một relational database phải thực hiện được các công việc sau:
- Cho phép insert/update/delete
- Cho phép thay đổi schema
- Triển khai cơ chế multiversion concurrency control (MVCC – đồng kiểm soát đa phiên bản, để các kết nối khác nhau có transactional view của dữ liệu tương ứng.
Việc hình dung cách kết hợp của những tính năng này, là một phần cốt yếu khi phải thiết kế cách database thể hiện data trên ổ cứng.
Immutable row data (dữ liệu bất biến) cũng là một phương diện thiết kế cốt yếu của Postgres. Trong cách nói của Postgres, những hàng data bất biến này được gọi là “tuples”. Những tuples này được xác định độc nhất bởi ctid. Một ctidthế hiện vị trí đại khái on-disk (như physical disk offset) của một tuple. Nhiều ctids có thể mô tả một hàng duy nhất (như khi nhiều phiên bản của hàng, tồn tại cho mục đích MVCC; hoặc khi phiên bản cũ của hàng vẫn chưa được autovacuum process tiếp quản). Tập hợp tuples có xắp sếp, sẽ hình thành một table. Bản thân tables đều có index, được sắp xếp dưới dạng cấu trúc cây nhị phân (thường là B-trees) giúp map các trường index đến một ctidchứa toàn bộ data tương ứng của nó.
Thông thường, những citdsnày rất rõ ràng với người dùng. Khi đã biết được cách hoạt động của citd, ta có thể hiểu được cấu trúc on-disk của Postgres tables. Để thấy được ctid hiện có của hàng, bạn có thể thêm ctid vào column list (danh sách cột) trong mệnh đề WHERE:
1 2 3 4 5 6 7 | uber@[local] uber=> SELECT ctid, * FROM my_table LIMIT 1; -[ RECORD 1 ]--------+------------------------------ ctid | (0,1) ...other fields here... |
Để giải thích chi tiết, hãy xem thử ví dụ users table đơn giản sau. Với mỗi user, ta có auto-incrementing user ID primary key (key chính, user ID tự tăng khi insert), tên họ, năm sinh của user. Ta còn xác định compound secondary index (chỉ mục thứ cấp kép) dựa trên họ tên của user, và một secondary index khác dựa trên năm sinh của user. Sau đây là DDL (data definition language) để tạo một table như vậy:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | CREATE TABLE users ( id SERIAL, first TEXT, last TEXT, birth_year INTEGER, PRIMARY KEY (id) ); CREATE INDEX ix_users_first_last ON users (first, last); CREATE INDEX ix_users_birth_year ON users (birth_year); |
Chú ý ba index trong định nghĩa này gồm: primary key index cùng hai secondary index đã xác định.
Đến phần ví dụ trong bài viết, ta có table sau, gồm các data tổng hợp các nhà toán học nổi tiếng trọng lịch sử:
| id | first | last | birth_year |
| 1 | Blaise | Pascal | 1623 |
| 2 | Gottfried | Leibniz | 1646 |
| 3 | Emmy | Noether | 1882 |
| 4 | Muhammad | al-Khwārizmī | 780 |
| 5 | Alan | Turing | 1912 |
| 6 | Srinivasa | Ramanujan | 1887 |
| 7 | Ada | Lovelace | 1815 |
| 8 | Henri | Poincaré | 1854 |
Như đã được đề cập, mỗi hàng ẩn chứa một ctid độc lập. Bởi vậy, ta có thể nhìn lại bảng trên theo cách sau:
| ctid | id | first | last | birth_year |
| A | 1 | Blaise | Pascal | 1623 |
| B | 2 | Gottfried | Leibniz | 1646 |
| C | 3 | Emmy | Noether | 1882 |
| D | 4 | Muhammad | al-Khwārizmī | 780 |
| E | 5 | Alan | Turing | 1912 |
| F | 6 | Srinivasa | Ramanujan | 1887 |
| G | 7 | Ada | Lovelace | 1815 |
| H | 8 | Henri | Poincaré | 1854 |
Primary key index giúp map ids đến ctids, được xác định như sau:
| id | ctid |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
B-tree được xác định trên trường id, và mỗi node trong B-tree chứa giá trị ctid. Để ý, trong trường hợp này, thứ tự sắp xếp của các trường trong B-tree lại tự nhiên giống với thứ tự trong bảng, đó là do ta sử dụng id tự gia tăng.
Hai secondary indexes trông cũng tương tự; điểm khác biệt chính là các trường này được lưu trữ theo thứ tự khác hẳn, vì B-tree phải được sắp xếp theo lexicographical order (một dạng của thứ tự bảng chữ cái Alphabet). Index (first, last) bắt đầu với phần tên (first) ở đầu bảng chữ cái đổ xuống:
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | H |
| Muhammad | al-Khwārizmī | D |
| Srinivasa | Ramanujan | F |
Tương tự, index birth_year được xếp theo thứ tự giảm dần:
| birth_year | ctid |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
Như bạn thấy, trong cả hai trường hợp, trường ctid ở secondary index tương ứng không tăng theo thứ tự Alphabet, khác với trường hợp tự gia tăng ở primary key.
Giả dụ, ta cần cập nhật một record trong table này. Chẳng hạn như cập nhật trường năm sinh cho một năm sinh ước đoán khác của al-Khwārizmī, năm 770 sau công nguyên. Và như ta đã nói, tuples là bất biến. Bởi vậy, để cập nhật record, chúng ta phải thêm tuple mới vào table. Tuple này lại có một ctid ẩn mới, ta sẽ tạm gọi là I. Postgres cần phải phân biệt được tuple I mới và tuple D cũ. Postgres chứa trong mỗi tuple một version field và pointer đến tuple trước đó (nếu có). Như vậy, cấu trúc mới của table như sau:
| ctid | prev | id | first | last | birth_year |
| A | null | 1 | Blaise | Pascal | 1623 |
| B | null | 2 | Gottfried | Leibniz | 1646 |
| C | null | 3 | Emmy | Noether | 1882 |
| D | null | 4 | Muhammad | al-Khwārizmī | 780 |
| E | null | 5 | Alan | Turing | 1912 |
| F | null | 6 | Srinivasa | Ramanujan | 1887 |
| G | null | 7 | Ada | Lovelace | 1815 |
| H | null | 8 | Henri | Poincaré | 1854 |
| I | D | 4 | Muhammad | al-Khwārizmī | 770 |
Miễn có hai phiên bản của hàng al-Khwārizmī, thì các index phải chứa entry cho cả hai hàng. Để đảm bảo ngắn gọn, chúng ta sẽ loại bỏ primary key index và chỉ hiển thị secondary index ở đây, như sau:
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | H |
| Muhammad | al-Khwārizmī | D |
| Muhammad | al-Khwārizmī | I |
| Srinivasa | Ramanujan | F |
| birth_year | ctid |
| 770 | I |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
Ta đã thể hiện phiên bản cũ màu đỏ và phiên bản mới màu xanh lá cây. Sự thật là, Postgres sử dụng một trường khác để giữ phiên bản của hàng, nhằm xác định tuple nào là mới nhất. Trường thêm vào này giúp database xác định tuple của hàng nào sẽ tham gia vào quá trình giao dịch (có thể không được phép thấy phiên bản của hàng mới nhất).
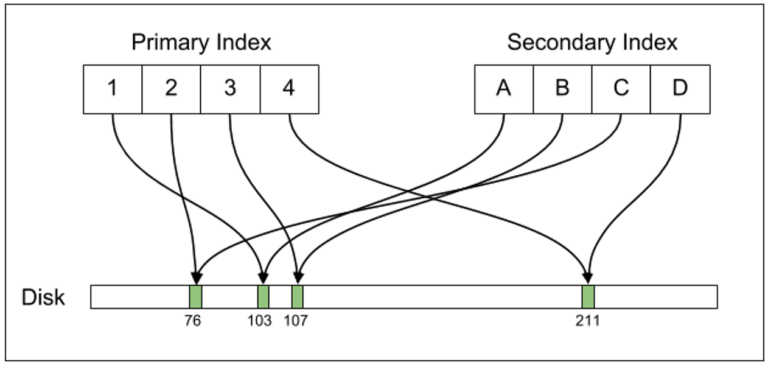
Replication
Khi ta nhập một hàng mới vào table, Postgress cần phải sao lưu hàng, nếu sao lưu streaming (streaming replication) đang mở. Để đảm bảo tính phục hồi dữ liệu khi crash, database của Uber đã duy trì một write-ahead log (WAL) và sử dụng WAL để thực thi two-phase commit (commit hai giai đoạn). Database phải duy trì WAL này ngay cả khi không mở sao lưu streaming, vì WAL cần thiết cho tính an toàn và độ bền của ACID.
Khi nghiên cứu các sự kiện diễn ra khi database crash bất ngờ (như khi mất điện đột ngột), ta có thể hiểu thêm được về WAL. WAL giống như “sổ hộ” ghi chép những thay đổi mà database dự định thực hiện trên on-disk content của table và index. Khi service Postgres khời động, process sẽ so sánh dữ liệu trong sổ hộ này với data thực có trên ổ cứng. Nếu sổ hộ chứa dữ liệu không được phản ánh trên ổ cứng, database sẽ sửa lại mọi tuple hoặc index data để phản ánh data do WAL chỉ ra. Sau đó, database sẽ tiếp tục rollback bất cứ data nào xuất hiện trên WAL, nhưng là từ transaction được áp dụng một phần (nghĩa là giao dịch chưa bao giờ được thực hiện).
Postgres thực thi sao lưu streaming bằng cách gửi WAL trên database chính đến các bản sao lưu. Mỗi database sao lưu ngay lập tức phản hồi như thể đang trong trạng thái crash recovery, liên tục áp dụng WAL updates. Điểm khác biệt duy nhất giữa sao lưu streaming và crash recovery thực tế là bản sao ở chế độ “hot standby”, thực hiện cái read queries khi áp dụng streaming WAL. Trong khi Postgres nếu thực sự ở chế độ crash recovery mode thường từ chối nhận bất cứ queries nào cho đến khi database instance đã hoàn thành quy trình crash recovery.
Vì WAL trong thực tế được thiết kế cho mục đích crash recovery, nó có chứa thông tin bậc thấp (low-level) về on-disk updates. Nội dung của WAL hiện ở mức độ thể hiện on-disk thực sự của row tuples và disk offsets của chúng (ví dụ như row ctids). Nếu bạn tạm dừng một Postgres chính và bản sao, khi bản sao đã hoàn toàn chạy xong, on-disk content thực tế trên bản sao sẽ khớp chính xác với content trên bản chính đến từng byte một. Bởi vậy, các công cụ như rsync có thể fix bản sao hỏng nếu bản sao bị lỗi thời (out of date) so với bản chính.
Hậu quả từ thiết kế của Postgres
Thiết kế của Postgres thiếu hiệu quả và gây kho khăn cho đội ngũ data tại Uber.
Write Amplification
Vấn đề đầu tiên với thiết kế của Postgres còn được gọi là write amplification (ghi khuếch đại). Thông thường, write amplication ám chỉ vấn đề với data được viết vào đĩa SSD: logical update nhỏ (chỉ vài bytes) bỗng nhiên nặng hơn, tốn kém hơn khi được dịch sang physical layer. Khuếch đại ghi trong Postgres cũng không khác gì như thế. Trong ví dụ trước khi ta chỉnh logical update sang năm sinh của al-Khwārizmī, chúng ta phải thực hiện ít nhất bốn physical updates:
- Viết tuple cho hàng mới trong tablespace
- Cập nhật primary key index để thêm record vào tuple mới
- Cập nhật (
first,last) index để thêm record vào tuple mới - Cập nhật index
birth_yearđề thêm record vào tuple mới
Trong thực tế, những cập nhật này chỉ phản ánh các writes trong tablespace chính, mỗi write này cần được phản ánh trên WAL nữa, vậy tổng số write trên ổ cứng thậm chí còn lớn hơn.
Điểm đáng chú ý ở đây là update 2 và 3. Khi ta cập nhật năm sinh cho al-Khwārizmī, chúng ta không thực sự thay đổi primary key của ông, hay thay đổi tên họ. Tuy nhiên, những thông số này vẫn cần phải được cập nhật, với việc tạo tuple hàng mới trong database cho record của hàng. Với những tables có một lượng lớn secondary index, những bước dư thừa này làm tạo áp lực thấy rõ lên hệ thống. Ví dụ như, nếu chúng ta có một table với một index duy nhất được xác định trên đó, cập nhật (đến trường chỉ do một index xử lý) phải được nhân rộng đến 12 index để phản ánh ctidcho hàng mới.
Replication
Vấn đề khuếch đại ghi này cũng tự động chuyển vào replication layer (lớp sao lưu), vì quá trình sao lưu xảy ra ở cấp độ của các thay đổi on-disk. Thay vì phải sao lưu một logical record nhỏ, như “Đổi năm sinh cho ctid D sang 770,” thay vào đó, database sẽ viết WAL entries của ta cho cả 4 writes đã nói trên, và cả 4 WAL entries này sẽ nhân rộng đến cả mang lưới còn lại. Vì vậy, vấn đề khuếch đại ghi còn biến thành vấn đề về khuếch đại bản sao, và Postgres replication data stream (dòng dữ liệu sao lưu Postgres) sẽ nhanh chóng trở nên cực kỳ khổng lồ, có khả năng chiếm lượng lớn băng thông.
Trong những trường hợp mà sao lưu Postgres chỉ đơn thuần xảy đến với một data center duy nhất, băng thông dành cho sao lưu sẽ không thành vấn đề. Những thiết bị mạng hiện đại và bộ chuyển mạch (switches) có thể xử lý lượng lớn băng thông, và nhiều nhà cung cấp (hosting) có hỗ trợ intra–data center bandwidth (băng thông cho trung tâm nội dữ liệu) giá thấp, thậm chí miễn phí. Tuy nhiên, khi quá trình sao lưu phải diễn ra giữa nhiều data centers khác nhau, ta sẽ gặp rắc rối lớn. Ví dụ, Uber mới đầu sử dụng physical servers tại một địa điểm thuê mướn ở West Coast. Để thuận lợi cho công tác phục hồi sau thảm họa, Uber thêm nhiều server nữa ở East Coast (cũng là thuê mướn). Theo thiết kế này, Uber có một Postgres instance chính (cộng với các bản sao) ở data center phía Tây và một loạt bản sao ở phía Đông.
Sao lưu trong Cascading giới hạn yêu cầu inter–data center bandwidth (băng thông cho trung tâm đa dữ liệu) xuống số lượng sao lưu cần thiết giữa chỉ bản chính và một bản sao duy nhất, ngay cả khi có nhiều bản sao ở data center thứ hai. Tuy nhiên, sự “đồ sộ” của giao thức sao lưu trong Postgres vẫn có thể tạo một lượng lớn dữ liệu cho database có quá nhiều index. Chi phí cho các liên kết đa quốc gia có băng thông cao vô cùng đắt đỏ, và thậm chí khi tiền bạc dư dả, ta cũng khó có thể kiếm được một liên kết đa quốc gia mạnh mẽ như mạng cục bộ. Vấn đề băng thông còn gây nhiều khó khăn khi lưu trữ WAL. Thay vì phải gửi tất cả cập nhật WAL từ West Coast sang East Coast, Uber lưu trữ lên dịch vụ web lưu trữ file, cả hai cách đều hướng đến mục đích đảm bảo lưu trữ dữ liệu để đề phòng thảm họa, và để WALs được lưu trữ có thể cho ra nhiều bản sao mới từ database snapshots. Trong thời điểm peak traffic, băng thông của Uber đến storage web service không đủ nhanh để đáp ứng với tốc độ viết của WALs.
Data Corruption
Trong một lần nâng cấp định kỳ database chính để tăng dung lượng, Uber chạm phải một lỗi trên Postgres 9.2. Các bản sao đi theo timeline switches không đúng hướng, dẫn đến đến một số bản sao áp dụng sai WAL records. Vì lỗi này, một số record đáng lẽ phải được versioning mechanism (cơ chế đánh số phiên bản) đánh dấu là inactive, lại không đúng như vậy.
Query sau mô tả cách bug này ảnh hưởng đến table ví dụ ta đang xét đến:
1 | SELECT * FROM users WHERE id = 4; |
Query này sẽ trả lại hai records: hàng al-Khwārizmī ban đầu (có năm sinh 780 CE), và hàng al-Khwārizmī mới (có năm sinh 770CE). Nếu chúng ta thêm ctid vào danh sách where, ta sẽ thấy các giá trị ctidkhác nhau cho hai record được trả về.
Vấn đề này cực kỳ khó chịu vì nhiều lý do, Thứ nhất, chúng ta không thể dễ dàng biết được vấn đề này đã ảnh hưởng bao nhiêu hàng. Các kết quả trùng lặp do database trả về gây application logic thất bại trong nhiều trường hợp. Chúng ta đến cùng phải thêm defensive programming statements (lệnh lập trình phòng thủ) để xác định tables sẽ gặp sự cố trong trường hợp nào. Vì bug ảnh hưởng đến tất cả server, các hàng bị hỏng sẽ khác với những replica instances (trường hợp sao lưu) khác nhau, có nghĩa là một bản sao của hàng X có thể vẫn còn tốt nhưng hàng Y lại bị hỏng. Trong thực tế, Uber cũng không chắc chắn về số lượng bản sao có dữ liệu bị hỏng, và liệu vấn đề có ảnh hưởng đến bản chính luôn hay không.
Tuy vậy, Uber cho biết, có thể vấn đề chỉ xảy ra với một vài hàng trên database thôi. Họ cũng rất lo ngại vì quá trình sao lưu diễn ra ở physical level (cấp độ vật lý), nên các index trong database có nguy cơ bị hủy hoàn toàn. B-trees có một đặc tính quan trọng, chúng phải liên tục được rebalanced (tái cân bằng), và những thao tác tái cân bằng này có thể hoàn toàn thay đổi cấu trúc của cả cây vì các sub-trees (cây phụ) được chuyển đến vị trí on-disk mới. Nếu duy chuyển không đúng data, phần lớn cây sẽ trở nên hoàn toàn biến thành “phế liệu”.
Đến cùng, Uber cũng lần ra nguyên do gây bug, và đã xác định database chính vừa nâng cấp không có hàng nào bị hỏng cả. Uber liền sửa được sự cố này ở các bản sao, bằng cách đồng bộ tất cả bản sao từ snapshot của bản chính, một quá trình mệt mỏi; họ chỉ đủ tài nguyên xử lý một vài bản sao một lúc.
Uber chỉ bắt gặp bug này duy nhất nhất ở Postgres 9.2 trước khi được xử lý hoàn toàn ở các phiên bản sau này. Tuy nhiên, họ vẫn khá dè chừng, vì kiểu lỗi này ngốn rất nhiều thời gian và tiền bạc. Nhỡ đâu những phiên bản release tiếp theo lại xuất hiện thì sao, cộng thêm lối làm việc quá phụ thuộc vào bản sao này, sự cố hoàn toàn có thể lan ra tất cả database.
Replica MVCC
Postgres không thực sự hỗ trợ sao lưu MVCC. Khi các bản sao áp dụng WAL updates, chúng sẽ có một bản copy on-disk giống y với bản chính. Uber nhận thấy vấn đề nằm ở đây.
Postgres vần phải duy trì một bản sao của phiên bản của hàng cũ cho MVCC. Nếu một sao lưu streaming có giao dịch mở, updates đến database sẽ bị chặn nếu chúng ảnh hưởng đến các hàng được giao dịch giữ mở. Trong trường hợp này, Pestgres tạm ngưng WAL application thread (dòng đảm nhiệm áp dụng WAL) cho đến khi giao dịch kết thúc. Đây sẽ là vấn đề lớn nếu giao dịch mất quá nhiều thời gian, vì bản sao có thể tụt sau bản chính rất nhiều. Bởi vậy, Postgres áp dụng timeout trong trường hợp này: nếu một giao dịch chặn việc áp dụng WAL trong một khoảng thời gian xác định, Postgres sẽ triệt tiêu giao dịch đó.
Cách thiết kế này đồng nghĩa với việc các bản sao thường có thể đi sau bản chính vài giây, và bởi vậy rất dễ viết code cho ra nhiều giao dịch bị hủy. Vấn đề này có thể không rõ ràng với application developers (những lập trình viên viết code có điểm bắt đầu và kết thức của giao dịch khá mù mịt). Ví dụ như, giả sử một lập trình viên có đoạn code với nhiệm vụ email biên lai cho người dùng. Dựa trên cách viết, đoạn code có thể ngầm chứa giao dịch database được giữ mở cho đến sau khi email gửi xong. Để ‘code giữ giao dịch database’ mở trong khi thực hiện ‘block I/O không liên quan’ luôn hại nhiều hơn lợi, nhưng có vẻ như trong thực tế đa số kỹ sư không phải là chuyên gia về databse nên không biết đến vấn đề, đặc biệt khi sử dụng ORM làm lu mở các chi tiết cấp thấp như giao dịch mở.
Postgres Upgrades
Vì các record sao lưu làm việc ở mức độ vật lý, nên ta không thể sao lưu dữ liệu giữa các phiên bản Postgres khác nhau. Database chính chạy Postgres 9.3 không thể sao lưu được bản sao chạy trên Postgres 9.2, hay ngược lại.
Uber áp dụng cách sau để cập nhật từ phiên bản Postgres GA này sang phiên bản GA khác:
- Shut down database chính.
- Chạy lệnh
pg_upgradelên database chính, cập nhật master data này. Với các database lớn, khâu này có thể mất nhiều tiếng đồng hồ và không thể thực hiện xử lý traffic từ database chính. - Mở database chính trở lại.
- Tạo snapshot cho database chính. Bước này hoàn toàn copy tất cả data dừ database chính, nên cũng phải mất nhiều tiếng nữa với database lớn.
- Xóa sạch mỗi bản sao và phục hồi snapshot mới từ bản chính sang bản sao.
- Mang mỗi bản sao trở lại hệ thống sao lưu. Đợi bản sao vừa hoàn toàn đáp ứng được với cập nhật từ bản chính, vừa được phục hồi.
Uber bắt đầu với Postgress 9.1 và hoành thành thành công quá trình cập nhật để chuyển sang Postgres 9.2. Tuy nhiên, quá trình trên mất quá nhiều thời gian, cộng thêm sự phát triển quy mô công ty khi Postgres 9.3 xuất hiện, thời gian chuyển đổi sẽ càng lâu hơn. Vì lý do này, các legacy Postgres instances của Uber vẫn dang chạy 9.2 cho đến nay, ngay cả khi hiện 9.5 Postgres GA đã ra mắt.
Nếu đang chạy Postgress 9.4 hoặc thấp hơn, bạn có thế sử dụng pglogical, giúp bổ sung logical replication layer (lớp sao lưu logic) cho Postgres. Khi dùng pglogical, bạn có thể sao lưu data giữa các phiên bản Postgres khác nhau. Nói cách khác, các bạn có thể nâng từ 9.4 lên 9.5 mà không phải chịu downtime quá lâu. Cách làm này hiển nhiên vẫn tồn đọng khuyêt điểm vì pglogical không được tích hợp vào mainline tree của Postgres, và pglogical không phải là lựa chọn cho những người dùng Postgres ở phiên bản cũ hơn.
Cấu trúc MySQL
Không chỉ bàn về hạn chế của Postgres, Uber còn giải thích tầm quan trọng của MySQL cho các project mới của Uber (như Schemaless). Trong nhiều trường hợp, Uber cảm thấy MySQL lại phù hợp hơn. Để thấy được sự khác biệt, Uber nghiên cứu cấu trúc của MySQL và đối chiếu Với Postgress. Cụ thể hơn, cách MySQL tương tác với InnoDB storage engine.
InnoDB On-Disk Representation
Giống Postgres, InnoDB hỗ trợ các tính năng nâng cao như MVCC và mutable data. Cúng ta sẽ không bàn về on-disk format, mà về những điểm khác biệt cơ bản với Postgres.
Khác biệt cấu trúc quan trọng nhất là: Postgress trực tiếp map index records đến các vị trí on-disk, còn InnnoDB duy trì cấu trúc thứ cấp. Thay vì giữ pointer đến vị trí hàng on-disk (như ctid trong Postgres), InnoDB secondary index records sẽ giữ pointer đến primary key value. Vì thế, secondary index trong MySQL sẽ liên kết index keys với primary keys:
| first | last | id (primary key) |
| Ada | Lovelace | 7 |
| Alan | Turing | 5 |
| Blaise | Pascal | 1 |
| Emmy | Noether | 3 |
| Gottfried | Leibniz | 2 |
| Henri | Poincaré | 8 |
| Muhammad | al-Khwārizmī | 4 |
| Srinivasa | Ramanujan | 6 |
Để thực hiện index lookup lên (first, last) index, chúng ta cần có hai lookups. Lookup đầu tiên quét trong table và tìm primary key index để tìm vị trí on-disk cho hàng.
Như vậy, InnoDB có hơi kém lợi thế so với Postgres khi thực hiện secondary lookup, vì cả hai index phải được tìm với InnoDB so với chỉ một index như ở Postgres. Tuy nhiên, vì dữ liệu được đơn giản hóa, row updates chỉ cần phải update những index record thực sự được row update thay đổi. Thêm vào đó, InnoDB thường thực hiện row update tại chỗ. Nếu các giao dịch cũ cần phải tham chiếu một hàng để phục vụ MVCC, MySQL sẽ copy hàng cũ vào khu vực đặc biệt gọi là rollback segment.
Hãy xem thử điều gì sẽ xảy ra khi ta update năm sinh của al-Khwārizmī. Nếu có đủ không gian, trường năm sinh ở hàng có id 4 sẽ được update tại chỗ (trong thực tế, cập nhật này luôn diễn ra tại chỗ, vì năm sinh là một số nguyên chiếm giữ lượng không gian cụ thể). Index năm sinh cũng được cập nhật tại chỗ để phản ánh ngày mới. Data của hàng cũ được sao chép đến phân đoạn rollback. Primary key index không nhất thiết phải cập nhật, (first, last) name index cũng vậy. nếu ta có lượng lớn index trên table này, chúng ta chỉ phải update các index thực sự index trên trường birth_year. Vậy giả sử ta có các index trên các trường như signup_date, last_login_time,… Chúng ta không cần phải update những index này, trong khi Postgres lại cần phải update.
Thiết kế này còn giúp vacuuming và compaction được hiệu quả hơn. Tất cả hàng có đủ điều kiện vacuum sẽ trực tiếp có sẵn trong rollback segment. Theo so sánh, quá trình autovacuum trong Postgres phải thực hiện full table scan để xác định các hàng đã bị xóa bỏ.
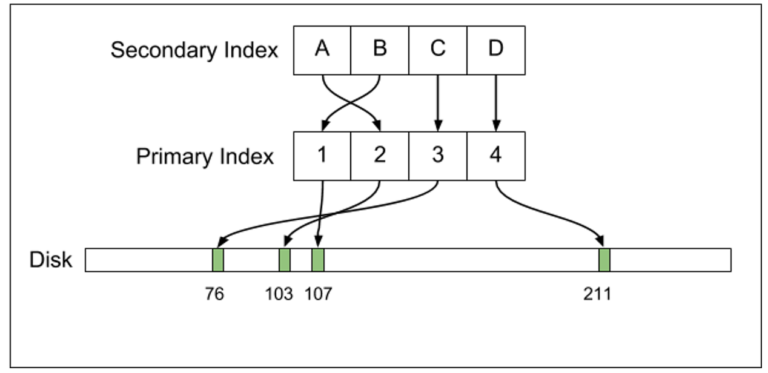
Replication
MySQL hỗ trợ nhiều chế độ sao lưu khác nhau:
- Statement-based replication (bản sao dựa trên câu lệnh) sao lưu logical SQL statements (ví dụ như, sự sao lưu ngay lập tức của các câu lệnh chữ như:
UPDATE users SET birth_year=770 WHERE id = 4) - Row-based replication (Sao lưu theo hàng) sao lưu các records hàng đã thay đổi
- Mixed replication (Sao lưu hỗn hợp) phối hợp hai chế độ trên
Các chế độ sao lưu này đều có lợi và hại khác nhau. Bản sao dựa trên câu lệnh thường gọn nhẹ nhất nhưng yêu cầu các bản sao phải áp dụng nhiều câu lệnh tốn kém để update chỉ lượng nhỏ data. Nói cách khác, sao lưu theo hàng, tương tự với sao lưu WALL trong Postgress, thường rườm rà hơn, nhưng mang lại kết quả cập nhật bản sao hiệu quả và dễ dự đoán hơn.
Trong MySQL, chỉ primary index có pointer đến các offset on-disk của hàng. Điều này gây hậu quả khá quan trọng đến bản sao. MySQL replication stream (dòng sao chép MySQL) chỉ cần chứa thông tin về logical update đến hàng. Các update đến bản sao là của variety “Đổi timestamp hàng X từ T_1 sang T_2.” Dựa theo kết quả của các câu lệnh này, các bản sao tự động kết luận bất cứ bất thay đổi nào trong index cần thực hiện.
Ngược lại, Postgres replication stream (dòng sao lưu Postgres) lại chứa các thay đổi vật lý, như “tại disk offset 8,382,491, viết bytes XYZ.” Với Postgres, mỗi thay đổi vật lý được thực hiện đến ổ cứng cần phải được gộp vào WAL stream. Các thay đổi logic nhỏ lẻ (như việc update một timestamp) càng tăng thêm độ quan trọng của thay đổi on-disk: Postgres phải nhập tube mới và update tất cả index để chỉ đến tuple đó. Vì thế, nhiều thay đổi sẽ được đặt vào WAL stream. Điểm thiết kế khác biệt này đồng nghĩa với việc binary log của bản sao MySQL sẽ phần nào gọn nhẹ hơn PostgreSQL WAL stream.
Cách vận hành của mỗi dòng sao lưu cũng có ảnh hưởng nghiêm trọng lên cách MVCC làm việc với các bản sao. Vì dòng sao lưu Postgres có logical updates, các bản sao có thể có ngữ nghĩa MVCC; do đó read queries trên replicas sẽ không block dòng sao lưu. Ngược lại, Postgres WAL stream chứa các thay đổi vật lý on-disk, nên các bản sao Postgres không thể áp dụng lên các update bản sao mâu thuẫn với read queries, vì vậy chúng không thể triển khai MVCC.
Với cấu trúc sao lưu của MySQL, nếu bug gây ra table corruption, vấn đề thường sẽ gây lỗi quá nghiêm trọng. Quá trình sao lưu thường diễn ra tại logical layer, nên một số thao tác như: cần bằng B-tree sẽ không cách nào làm index bị lỗi. Câu lệnh bị bỏ qua (hoặc áp dụng đến hai lần), là một sự cố sao lưu MySQL điển hình. Việc này có thể khiến data bị mất hoặc vô hiệu lực, nhưng sẽ không làm thất thoát database.
Cuối cùng, cấu trúc sao lưu của MySQL không quá quan trọng việc sao lưu giữa các phiên bản MySQL khác nhau. MySQL chỉ lên phiên bản nếu định dạng sao lưu thay đổi; giữa các phiên bản MySQL, điều này khá bất thường. Định dạng sao lưu logic của MySQL còn chỉ ra rằng, các thay đổi on-disk trong storage engine layer (lớp công cụ lưu trữ) không ảnh hướng đến dịnh dạng sao lưu. Cách thường dùng để nâng cấp MySQL là: áp dụng bản update đến từng bản sao lưu một, và khi đã up hết tất cả sao lưu, bạn hãy thăng cấp một bản sao bất kỳ lên làm bản chính. Cách này vừa giúp nâng caoas MySQL thật đơn giản, vừa không mất downtime.
Một số thế mạnh khác của MySQL
Đến đây, ta đã tập trung vào cấu trúc on-disk của Postgres và MySQL. Bên cạnh đó, MySQL vẫn còn một số thế mạnh khác so với Postgres
Buffer Pool
Trước hết, ở hai database này, caching làm việc rất khác. Postgres cấp phát một phần bộ nhớ cho internal cache, nhưng những cache này thường rất nhỏ khi so sánh với tổng lượng bộ nhớ của bộ máy. Để tăng hiệu năng, Postgres cho phép kernel tự động cache disk data đã truy cập gần đây, thông qua page cache. Ví dụ như, các bản sao Postgres lớn nhất có 768 GB bộ nhớ, nhưng thực sự chỉ có 25GB bộ nhớ đó là RSS memory bị các Postgres process gây lỗi. Như vậy, ta còn đến hơn 700 GB bộ nhớ dành cho Linux page cache.
Vấn đề với thiết kế này là: truy cập data qua page cache lại tốn kém hơn truy cập bộ nhớ RSS. Để tra cứu data từ ổ cứng, Postgres process sẽ phát các system call lseek(2) và read(2) để cấp phát data. Mỗi system call sẽ phải chịu một context switch, context switch này thường đắt đỏ hơn việc truy cập data từ main memory. Trong thực tế, Postgres cũng không hoàn toàn quá tối ưu về mặt này: Postgres không tận dụng system call pread(2), kết hợp hai thao tác seek + read thành một system call duy nhất.
Sau khi đối chiếu, InnoDB storage engine (công cụ lưu trữ InnoDB) sẽ tự thực thi LRU của nó trong InnoDB buffer pool. Khá giống với Linux page cache nhưng được thực thi trong userspace. InnoDB buffer pool, tuy phức tạp hơn thiết kế của Postgres, nhưng lại có nhiều thế mạnh lớn:
- Có thể tích hợp custom LRU design, như: ta có thể xác định các pathological access patterns (mô hình truy cập bệnh lý) có khả năng thổi bay LRU, và hạn chế thiệt hại xuống thấp nhất.
- Ít dính đến context switch hơn. Data được truy cập thông qua InnoDB buffer pool không yêu cầu bất cứ user/kernel context switch nào. Trường hợp phản ứng tệ nhất là sự xuất hiện của TLB miss, khá rẻ và có thể được giảm thiểu với huge pages.
Connection Handling
Thông qua việc spawn thread-per-connection, MySQL có thể thực hiện các concurrent connection (kết nối đồng thời). Cách này ít overhead hơn; mỗi thread sẽ dành một phần memory overhead cho stack place, cộng thêm một số bộ nhớ được cấp phát trên heap cho connection-specific buffers (buffer riêng cho connection). Cũng không quá bất ngờ khi MySQL đạt quy mô đến 10.000 concurrent connection. Bản thần nhiều MySQL instance của Uber cũng đã gần đạt đến con số này.
Tuy nhiên, Postgres lại dùng thiết kế process-per-connection, tốn kém hơn thread-per-connection nhiều. Việc fork một process (mới) chiếm dụng nhiều bộ nhớ hơn là spawn thread mới. Hơn nữa, IPC giữa các process cũng tốn kém hơn giữa thread nhiều. Postgres 9.2 sử dụng các primitive System V IPC cho IPC, thay vì futexes gọn nhẹ với thread. Futexes cũng nhanh hơn System V IPC vì trong trường hợp futex không được thỏa mãn, ta thường sẽ không cần phải tạo context switch nữa.
Bên cạch các vấn đề về bộ nhớ và IPc overhead, Postgres nhìn chung hỗ trợ rất kém trong việc xử lý lượng lớn kết nối, ngay cả khi vẫn còn đủ bộ nhớ. Uber cũng đã rất chật vật khi phải mở rộng quá trăm kết nối với Postgres. Tài liệu rất khuyến khích sử dụng cơ chế pooling kết nối out-of-process, để xử lý lượng lớn kết nối trong Postgres, nhưng lại không đưa ra lý do tại sao lại làm vậy. Theo đó, Uber cũng đạt được kha khá thành công khi sử dụng pgbouncer để thực hiện connection pooling trong Postgres. Tuy nhiên, họ vẫn thi thoảng gặp phải application bugs trong các dịch vụ backend, khiến các dịch vụ này phải mở thêm active connections (tường là kết nối “idle in transaction”) hơn mức cần thiết; từ đó khiến downtime càng lâu hơn.
Lời kết
Trong giai đoạn đầu của Uber, Postgres đã hoàn thành xuất sắc nhiệm vụ của mình, nhưng lại tỏ ra không phù hợp khi công ty mở rộng quy mô. Hiện nay, tuy Uber vẫn còn một vài legacy Postgres instance, nhưng phần lớn database đã chuyển sang MySQL (kết hợp với Schemaless layer), hoặc các database NoSQL (như Cassandra) trong các trường hợp đặc biệt. Nhìn chung, Uber hiện đang “ăn nằm” rất tốt với MySQL.
Hy vọng thông qua bài viết, các bạn đã phần nào biết được các set up cho một business có quy mô lớn như Uber, hẹn gặp lại các bạn trong các bài viết chuyên sâu tiếp theo.
ITZone via Uber