
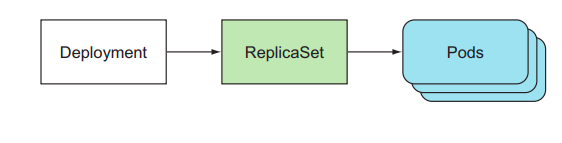
1. ReplicaSets
In Part 1, we discussed the concept of ReplicationControllers as a component of the Kubernetes system that helps manage the status of available Pods and nodes.
ReplicaSets in Kubernetes has a similar role to ReplicationControllers , more precisely, ReplicaSets was introduced to replace ReplicationControllers .
Compare the correlation between ReplicaSets and ReplicationControllers
- ReplicationControllers can only be created directly by configuring the
yamlfile or using the command line withkubectl. With ReplicaSets , in addition to the normal way of initializing like ReplicationControllers , it can be created automatically when we initialize a Deployment object (we will learn Deployment later). - ReplicaSets can be configured to apply to multiple labels values in the same field. ReplicationControllers can only be applied to Pods with a value for each labels field. For example, ReplicaSets can apply to Pods with labels
env=production,env=development, etc. ReplicationControllers only applies to Pods with labelsenv=development.
2. Volumes
As we all know, the Kubermetes system will create new Pods to replace when a Pods fails, dies or crashes. So where does the data stored in the old Pods go? Will new Pods get back the data of old Pods that have been lost to continue using? The concept of Voulumes will help solve these problems.
Volumes are components of Pods. Volumes are defined in the yaml file configuration when creating pods. The container can mount data inside the container to volume objects belonging to the same Pods.
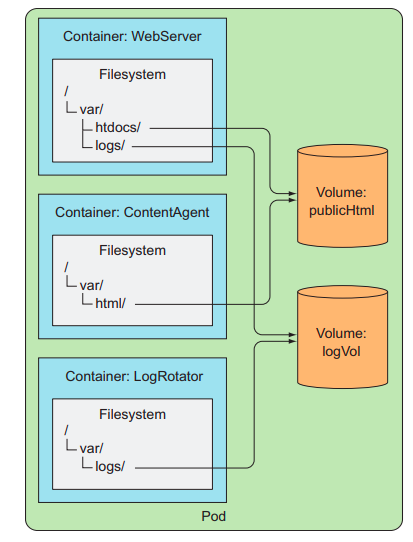
Containers in Pods mount up to 2 voumes to share data with each other
Types of volumes
- emptyDir
- hostPath
- gitRepo
- nfs
- Cloud volumes: gcePersistentDisk (Google Compute Engine Persistent Disk), awsElasticBlockStore (Amazon Web Services Elastic Block Store Volume), azureDisk (Microsoft Azure Disk Volume).
- cinder, cephfs, iscsi, flocker, glusterfs, quobyte, rbd, flexVolume, vsphereVolume, photonPersistentDisk, scaleIO:
- configMap, secret, downwardAPI:
- persistentVolumeClaim:
As seen, there are many different types of volumes, within the scope of the article, it is not allowed to explore all types of volumes. We will look at a few types of volumes.
EmptyDir Volumes
is the simplest volume type. Initially just an empty folder, containers can use emptyDir volumes to read, write and share to other containers and Pods. When Pods crash or are deleted, emptyDir volumes also lose with the data in it.
Create an EmptyDir volumes (In the configuration file of Pods) *
fortune-pod.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | <span class="token key atrule">apiVersion</span> <span class="token punctuation">:</span> v1 <span class="token key atrule">kind</span> <span class="token punctuation">:</span> Pod <span class="token key atrule">metadata</span> <span class="token punctuation">:</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> fortune <span class="token key atrule">spec</span> <span class="token punctuation">:</span> <span class="token key atrule">containers</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> luksa/fortune <span class="token key atrule">name</span> <span class="token punctuation">:</span> html <span class="token punctuation">-</span> generator <span class="token key atrule">volumeMounts</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> html <span class="token key atrule">mountPath</span> <span class="token punctuation">:</span> /var/htdocs <span class="token punctuation">-</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> nginx <span class="token punctuation">:</span> alpine <span class="token key atrule">name</span> <span class="token punctuation">:</span> web <span class="token punctuation">-</span> server <span class="token key atrule">volumeMounts</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> html <span class="token key atrule">mountPath</span> <span class="token punctuation">:</span> /usr/share/nginx/html <span class="token key atrule">readOnly</span> <span class="token punctuation">:</span> <span class="token boolean important">true</span> <span class="token key atrule">ports</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">containerPort</span> <span class="token punctuation">:</span> <span class="token number">80</span> <span class="token key atrule">protocol</span> <span class="token punctuation">:</span> TCP <span class="token key atrule">volumes</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> html <span class="token key atrule">emptyDir</span> <span class="token punctuation">:</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> |
Looking at the configuration file above, we cos:
- Pods include 2 containers:
html-generator,web-server. - The directory of the
html-generatorcontainer is mounted with volumes of/var/htdocs - Container directory
web-serverto be mounted with volumes is/usr/share/nginx/htmlat CE levelreadOnly(read-only data from the volumes in the container).
In this example, the html-generator container will change the index.html file in the /var/htdocs folder /var/htdocs 10 seconds. When the new html file is created, it will be updated in volumes and the web-server container can read them. When a user sends a request, for example, to the nginx web-server container, the data returned is the latest index.html file.
- The last 3 lines contain information about the volumes name and the volumes type is
emptyDir. By default,emptyDirwill use theworker nodes‘ hard drive resources for storage. We can have another option of usingworker nodes‘ RAM as follows:
1 2 3 4 5 | <span class="token key atrule">volumes</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> html <span class="token key atrule">emptyDir</span> <span class="token punctuation">:</span> <span class="token key atrule">medium</span> <span class="token punctuation">:</span> Memory |
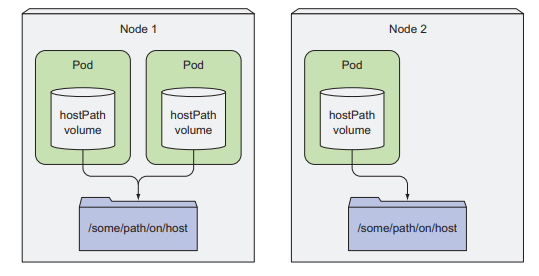
hostPath volume
As we all know, with empty volume , data will be lost when Pods fail, delete or crash because empty volume is a part of Pods. With the hosPath volume, data stored in volumes will not be lost when the Pods fail because it is outside the Pods (in the worker node’s file system). When new Pods are created to replace the old Pods, it will mount to the hostPath volume to continue working with the data on the old Pods.
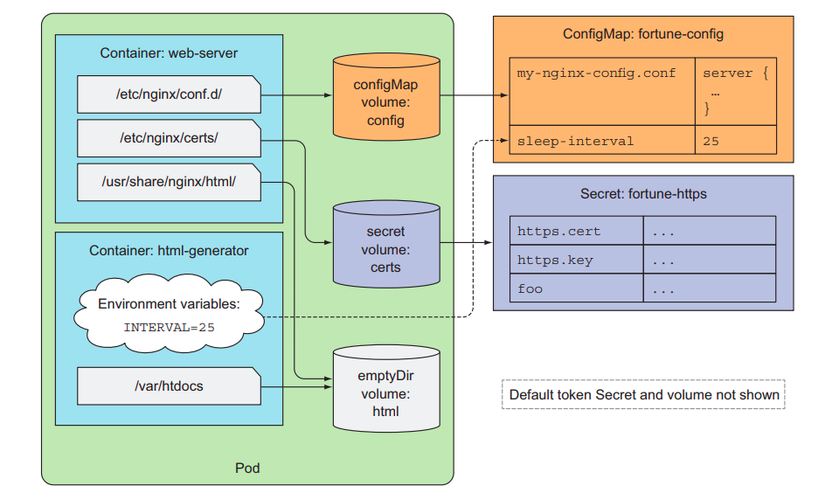
ConfigMap and Secret
Normally when programming applications, we put important variables (such as DB url password, secret key, DB name, etc.) into .env files as environment variables to ensure confidentiality. In the Kubernetes system, Config Map and Secret are the two types of volumes that help to store environment variables for use by containers of different Pods. Config Map will be used with environment variables that do not contain sensitive information. Secret , as its name implies, will be used to store sensitive and important environment variables. Unlike other volume types, Config Map and Secret will be defined separately from yaml files instead of the configuration in yaml files that initialize Pods.
1 2 3 4 5 6 7 8 9 10 11 12 13 | apiVersion <span class="token punctuation">:</span> v1 kind <span class="token punctuation">:</span> ConfigMap metadata <span class="token punctuation">:</span> creationTimestamp <span class="token punctuation">:</span> <span class="token number">2017</span> <span class="token operator">-</span> <span class="token number">12</span> <span class="token operator">-</span> <span class="token number">27</span> T18 <span class="token punctuation">:</span> <span class="token number">36</span> <span class="token punctuation">:</span> <span class="token number">28</span> Z name <span class="token punctuation">:</span> game <span class="token operator">-</span> config <span class="token operator">-</span> env <span class="token operator">-</span> file namespace <span class="token punctuation">:</span> <span class="token keyword">default</span> resourceVersion <span class="token punctuation">:</span> <span class="token string">"809965"</span> uid <span class="token punctuation">:</span> d9d1ca5b <span class="token operator">-</span> eb34 <span class="token operator">-</span> <span class="token number">11e7</span> <span class="token operator">-</span> <span class="token number">887</span> b <span class="token operator">-</span> <span class="token number">42010</span> a8002b8 data <span class="token punctuation">:</span> allowed <span class="token punctuation">:</span> <span class="token string">'"true"'</span> enemies <span class="token punctuation">:</span> aliens lives <span class="token punctuation">:</span> <span class="token string">"3"</span> |
1 2 3 4 5 6 7 8 9 | apiVersion <span class="token punctuation">:</span> v1 kind <span class="token punctuation">:</span> Secret metadata <span class="token punctuation">:</span> name <span class="token punctuation">:</span> mysecret type <span class="token punctuation">:</span> Opaque data <span class="token punctuation">:</span> username <span class="token punctuation">:</span> YWRtaW4 <span class="token operator">=</span> password <span class="token punctuation">:</span> MWYyZDFlMmU2N2Rm |
3. Deployments
So far, the first component that needs to be initialized in a Kubernetes system is no other than Pods . And as we all know, to manage the status of Pods , it is necessary to create more Replication Controllers to manage those Pods, which is quite cumbersome operation. And imagine that in a large to very large system with hundreds, thousands or tens of thousands of Pods, it would be a pain to create more Replication Controllers to manage Pods or Pods group according to those labels?
Kubernetes has introduced the concept of Deployments to help simplify the process above. With Deployments , we will just need to define the configuration and create a Deployments , the system will automatically create one or more corresponding Pods and ReplicaSet to manage the status of those Pods. In addition, Deployments also has a mechanism to help system administrators easily update, rollback the version of the application (the container version runs in Pods).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | apiVersion <span class="token punctuation">:</span> apps <span class="token operator">/</span> v1beta1 kind <span class="token punctuation">:</span> Deployment metadata <span class="token punctuation">:</span> name <span class="token punctuation">:</span> kubia spec <span class="token punctuation">:</span> replicas <span class="token punctuation">:</span> <span class="token number">3</span> template <span class="token punctuation">:</span> metadata <span class="token punctuation">:</span> name <span class="token punctuation">:</span> kubia labels <span class="token punctuation">:</span> app <span class="token punctuation">:</span> kubia spec <span class="token punctuation">:</span> containers <span class="token punctuation">:</span> <span class="token operator">-</span> image <span class="token punctuation">:</span> luksa <span class="token operator">/</span> kubia <span class="token punctuation">:</span> v1 name <span class="token punctuation">:</span> nodejs |
In the above yaml file, we defined a deployment called kubia. The configuration for Replicas always maintains 3 Pods, running Pods will have labels app=kubia and containers running in Pods will be built from image luksa/kubia:v1