Hello everyone today I will share a baseline model for the HIt-song prediction problem of Zalo AI challenge 2019 . Link contest here .
Introduce
About the contest
In the Zalo AI challenge 2019, there are 3 problems: Hit Song Prediction, MotoBike Generation and Vietnamese WIki Question Answering. However, I only participated in the Hit Song Prediction contest with the main purpose of learning from real data and besides, I want to learn more with audio data and how to extract feature from this data type.
About the Hit Song Prediction problem
The purpose of the problem is to predict which songs will become hot, hit within a certain period of time based on the data set provided by the competition (collected from the rankings of Zingmp3). The Hit Song prediction is really useful for singers, musicians, or music providers to contribute to increasing sales and increasing their popularity, ….
Civilization is a bit short so let’s not ramble anymore let’s get started.
Data and Analysis
Data
Divided into episodes Train and Test :
- Train set contains 9078 songs.
- The test set contains 1118 songs that need to be ranked.
** Detailed description **:
- Train: Here the organizers (BTC) provide us with 9078 Vietnamese songs uploaded to Zing MP3 in 2017 and 2018, each song includes:
- An audio file as ‘.mp3’
- In metadata (train_info.tsv) include (title, composer, singer, release-time)
- Ranking from 1 to 10, based on the position on the ranking of Zing MP3 within six months after uploaded date. 2. Test:
The test set contains 1118 songs that need to be ranked. And each song includes:
- An audio file as ‘.mp3’
- In metadata (test_info.tsv) include (title, composer, singer, release-time).
Analysis
Ps: Here I only use the fields available in the metadata to train and have not used any audio, so I will skip the audio here. If you want to use more audio data, you can read more here . Let’s try and see what the data has.
1 2 3 4 5 6 7 8 | import pandas as pd import numpy as np # read file train df_train = pd.read_csv("train_info.tsv", sep="t") print(df_train) |
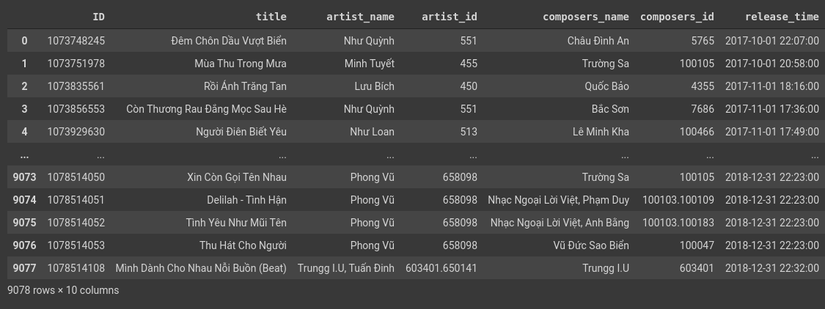 Figure 1: Train Data
Figure 1: Train Data
1 2 3 | # artist name value_counts df_train['artist_name'].value_counts() |
 Figure 2: Calculating the number of singers
Figure 2: Calculating the number of singers
In Figure 2 we can see the total number of singers appearing is 2397 (here I count 2 singers singing a song as 1 dental singer in the whole family). And singer Hoang Minh Thang appears 147 times at most (the first time I hear this singer’s name @ [email protected] ) Next we can see how many composer numbers are similar.
1 2 3 | # artist name value_counts df_train['composers_name'].value_counts() |
Figure 3: Calculating the number of composers
Here we can see there are 2048 composers for 9078 songs  . The majority is Vietnamese Foreign Music has 178 times. Many musicians 168 times, Thanh Son 161 times. With similar test set the whole family.
. The majority is Vietnamese Foreign Music has 178 times. Many musicians 168 times, Thanh Son 161 times. With similar test set the whole family.
1 2 3 4 | # read file rank df_rank = pd.read_csv('train_rank.csv') df_rank.head() |
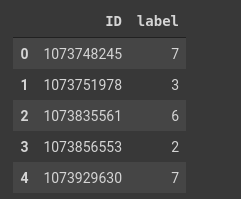
Figure 4: Ranking table of the training set
Let’s embark on train model all over the house =)).
Model RandomForest Regression
Here I will embark on trainning always and do not repeat the RandomForest theory again. If you want you can read here First I will encode “artist_id” and “composer_id” using LabelEncoder ()
1 2 3 4 5 6 | from sklearn.preprocessing import OneHotEncoder, LabelEncoder le = LabelEncoder() df_train['artist_id_'] = le.fit_transform(df['artist_id'].astype('str')) df_train['composers_id_'] = le.fit_transform(df['composers_id']).astype('int') |
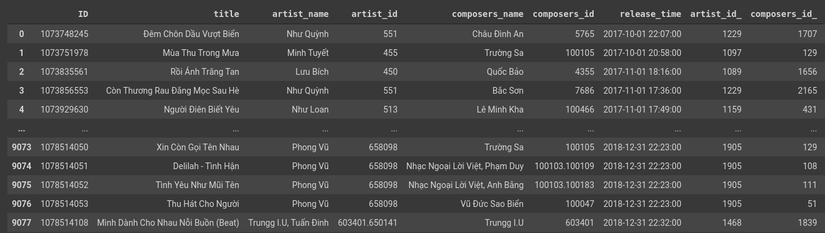 Figure 5: Results after encode in the train set
Figure 5: Results after encode in the train set
You do the same with the test offline!
1 2 3 4 | df_test = pd.read_csv('test_info.tsv', sep='t') df_test['composers_id_'] = le.fit_transform(df_test['composers_id']).astype('int') df_test['artist_id_'] = le.fit_transform(df_test['artist_id'].astype('str')) |
Share train training and validation.
1 2 3 4 5 | from sklearn.model_selection import train_test_split train = df_merged[['ID', 'artist_id_', 'composers_id_']] lable = df_rank['label'] X_train, X_val, y_train, y_val = train_test_split(train, Y, test_size=0.2, random_state=7) |
Next step: Training model
1 2 3 4 5 6 | from sklearn.ensemble import RandomForestRegressor rf_regression = RandomForestRegressor(n_estimators=2, min_samples_split= 2, random_state=0 ) rf_regression.fit(X_train, y_train) accuracy = rf_regression.score(X_val, y_val) print(accuracy) |
Prediction
1 2 3 4 | test = df_test[['ID', 'artist_id_', 'composers_id_']] y_pred = rf_regression.predict(test) y_pred |
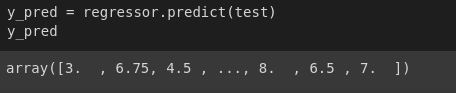 Figure 6: Predicted results
Figure 6: Predicted results
Ok, then everyone will output to the file submission and submit =)). Submit here
Conclude
In this article I mainly use metadata and have not used audio data so the results are not good, but for better results, people should use audio data as well. Hope everyone to discuss and comment so that we can have the best results in this contest =)))))))))))).
Reference
https://towardsdatascience.com/understanding-random-forest-58381e0602d2