Xin chào tất cả mọi người hôm nay mình sẽ chia sẻ một model baseline cho bài toán HIt-song prediction của cuộc thi Zalo AI challenge 2019.
Link cuộc thi tại đây.
Giới thiệu
Về cuộc thi
Trong cuộc thi Zalo AI challenge 2019 gồm có 3 bài toán: Hit Song Prediction, MotoBike Generation và Vietnamese WIki Question Answering. Tuy nhiên mình chỉ tham gia mỗi cuộc thi Hit Song Prediction với mục đích chính là học hỏi từ dữ liệu thật và bên cạnh đó mình muốn tìm hiểu nhiều hơn với dữ liệu dạng audio và cách extract feature từ kiểu dữ liệu này.
Về bài toán Hit Song Prediction
Mục đích của bài toán là dự đoán bài hát nào sẽ trở nên hot, hit trong khoảng thời gian nào đó dựa trên tập dữ liệu được cung cấp sẵn bởi cuộc thi ( được thu thập từ bảng xếp hạng của Zingmp3). Việc dự đoán Hit Song thực sự rất hữu ích cho ca sĩ, nhạc sĩ, hay nhà cung cấp nhạc góp phần nâng cao doanh thu và tăng sự nổi tiếng hơn cho họ, … .
Văn mình hơi ngắn nên không lan man nữa chúng ta cùng bắt đầu thôi nào.
Dữ Liệu và Phân Tích
Dữ Liệu
Được chia thành tập Train và Test:
- Tập train chứa 9078 bài hát.
- Tập test chứa 1118 bài hát cần được đánh rank.
**Mô tả chi tiết **:
- Train:
Ở đây ban tổ chức (BTC) cung cấp cho chúng ta 9078 bài hát Việt Nam được uploaded lên Zing MP3 năm 2017 và 2018, mỗi bài hát bao gồm:
- Một file audio dưới dạng ‘.mp3’
- Ở trong metadata (train_info.tsv) bao gồm(title, composer, singer, release-time)
- Được đánh rank từ 1 đến 10, dựa trên vị trí trên bảng xếp hạng của Zing MP3 trong thời gian sáu tháng sau ngày uploaded.
2. Test:
Tập test chứa 1118 bài hát cần được đánh rank. Và mỗi bài hát bao gồm:
- Một file audio dưới dạng ‘.mp3’
- Ở trong metadata(test_info.tsv) bao gồm(title, composer, singer, release-time).
Phân Tích
P.s: Ở đây mình chỉ dùng các trường có sẵn trong metadata để train và chưa sử dụng gì đến audio nên mình bỏ qua phần audio ở đây nhé. Nếu mọi người muốn sử dụng thêm audio data thì có thể đọc thêm ở đây nhé.
Cùng thử xem dữ liệu có những gì nha.
1 2 3 4 5 6 7 8 | import pandas as pd import numpy as np # read file train df_train = pd.read_csv("train_info.tsv", sep="t") print(df_train) |
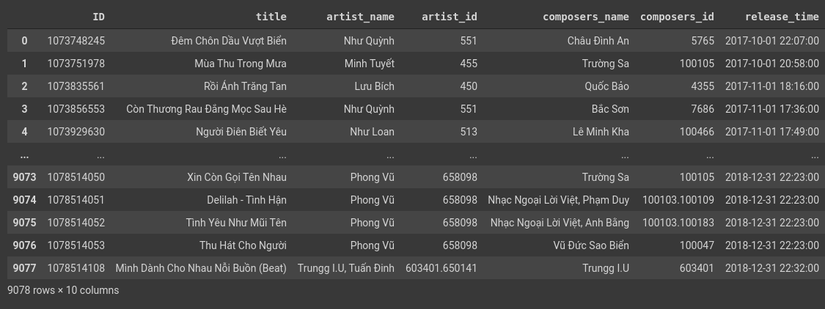
Hình 1: Train Data
1 2 3 | # artist name value_counts df_train['artist_name'].value_counts() |

Hình 2: Tính toán số lượng ca sĩ
Ở hình 2 chúng ta có thể thấy tổng số ca sĩ xuất hiện là 2397 (ở đây mình tính 2 ca sĩ hát một bài xem như 1 ca sĩ nha cả nhà). Và ca sĩ Hoàng Minh Thắng xuất hiện nhiều nhất tận 147 lần (lần đầu nghe tên ca sĩ này luôn @[email protected])
Tiếp theo chúng ta có thể xem xem số lượng composer như thế nào tương tự trên.
1 2 3 | # artist name value_counts df_train['composers_name'].value_counts() |
Hình 3: Tính toán số lượng composer
Ở đây chúng ta có thể thấy có 2048 composer cho 9078 bài hát  . Đa số là Nhạc Ngoại Lời Việt có 178 lần. Nhiều nhạc sĩ 168 lần, Thanh Sơn 161 lần.
. Đa số là Nhạc Ngoại Lời Việt có 178 lần. Nhiều nhạc sĩ 168 lần, Thanh Sơn 161 lần.
Với tập test tương tự nha cả nhà.
1 2 3 4 | # read file rank df_rank = pd.read_csv('train_rank.csv') df_rank.head() |
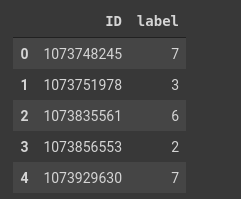
Hình 4: Bảng đánh rank của tập train
Cùng bắt tay vào train model thôi cả nhà =)).
Model RandomForest Regression
Ở đây mình sẽ bắt tay vào trainning luôn và không nhắc lại lý thuyết RandomForest nữa nha mn. Nếu muốn các bạn có thể đọc tại đây
Trước tiên mình sẽ encode “artist_id” và “composer_id” sử dụng LabelEncoder()
1 2 3 4 5 6 | from sklearn.preprocessing import OneHotEncoder, LabelEncoder le = LabelEncoder() df_train['artist_id_'] = le.fit_transform(df['artist_id'].astype('str')) df_train['composers_id_'] = le.fit_transform(df['composers_id']).astype('int') |
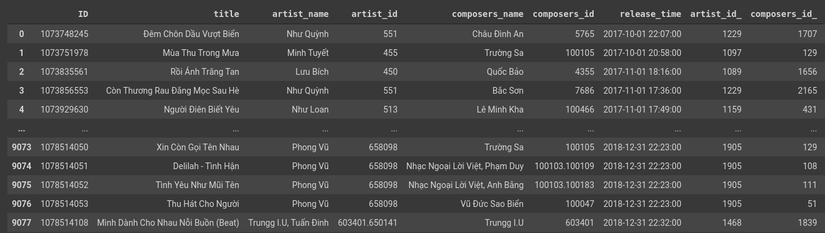
Hình 5: Kết qủa sau khi encode ở tập train
Các bạn làm tương tự với tập test nhé!
1 2 3 4 | df_test = pd.read_csv('test_info.tsv', sep='t') df_test['composers_id_'] = le.fit_transform(df_test['composers_id']).astype('int') df_test['artist_id_'] = le.fit_transform(df_test['artist_id'].astype('str')) |
Chia tập train và validation nha.
1 2 3 4 5 | from sklearn.model_selection import train_test_split train = df_merged[['ID', 'artist_id_', 'composers_id_']] lable = df_rank['label'] X_train, X_val, y_train, y_val = train_test_split(train, Y, test_size=0.2, random_state=7) |
Bước tiếp theo: Training model
1 2 3 4 5 6 | from sklearn.ensemble import RandomForestRegressor rf_regression = RandomForestRegressor(n_estimators=2, min_samples_split= 2, random_state=0 ) rf_regression.fit(X_train, y_train) accuracy = rf_regression.score(X_val, y_val) print(accuracy) |
Prediction
1 2 3 4 | test = df_test[['ID', 'artist_id_', 'composers_id_']] y_pred = rf_regression.predict(test) y_pred |
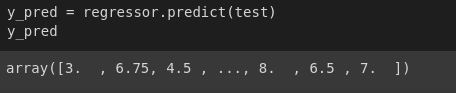
Hình 6: Kết quả dự đoán
Ok xong rồi mọi người xuất ra file submission và nộp thôi =)). Nộp tại đây nha
Kết Luận
Ở bài này mình chủ yếu dùng metadata và chưa dùng đến audio data nên kết quả chưa được tốt, tuy nhiên để kết quả tốt hơn mọi người nên sử dụng thêm cả audio data nữa nhé.
Mong mọi người cùng thảo luận và góp ý để chúng ta đều có kết quả tốt nhất ở cuộc thi này nha =))))))))))))).
Reference
https://towardsdatascience.com/understanding-random-forest-58381e0602d2