
1. Introduction
In the previous article about Scrapy , I learned the basics of Scrapy and made a small demo to crawl data from thegioididong website. You may find that with Scrapy we can crawl any website, I used to think so and tried with famous e-commerce sites like Shopee, Lazada, … but paid data back to nothing Thus, the limitation of Scrapy is that the web pages use javascript to render, but nowadays, JS users, JS users know how to do saoo.
Now, let’s continue to find a solution to see why =))
2. Check the site using javascript to render
As I mentioned above, Scrapy’s disadvantage is that it is not possible to crawl web pages that use js render. So, every time you have a mindset that you want to crawl a website with Scrapy, check this right before you plug your face into the code and make the effort to pour the river.
To know if this page renders with js content, you just need to Ctrl + U and see if there is html content as shown, or just a body tag and js inserted later. Or use Chrome Extension Quick Javascript Switcher , this tool allows to enable or disable Javascript of web pages very simply with 1 click.
After a while of learning, I found that Scrapy can be used with a headless browser like Splash to wait for the website to render the content and cookies, and then send the generated HTML back to the crawler to disassemble as usual, which is costly. add a little extra time to wait but still faster than the other Scrapy options.
Here are some of the functions that Splash gives us:
process multiple webpages in parallel;
get HTML results and / or take screenshots;
turn OFF images or use Adblock Plus rules to make rendering faster;
execute custom JavaScript in page context;
write Lua browsing scripts;
develop Splash Lua scripts in Splash-Jupyter Notebooks.
get detailed rendering info in HAR format.
Not only that, there is also a scrapy-splash lib for Scrapy too. So there are swords in hand, let’s go conquer the web using JS =)))
3. Practice
3.1. Create project and spider
I will use the last project to perform this demo, if you do not know how to create, you can follow that article to create a project.
This time Shopee will be my conquest target, using Quick Javascript Switcher to see it is true that it uses real JS, it crawl_shopee legs, itchy feet, I immediately created a crawl_shopee Spider to crawl all products of any one shop above. Shopee, for a simple demo, here I choose to temporarily shop the Apple Flagship Store because there is only 1 product page, creating a spider with the following command:
1 2 | scrapy genspider shopee_crawl https://shopee.vn/shop/88201679/search |
I just walked to the door of the shop, but couldn’t come inside, now I remember that I forgot the sword at home, hurry back to get it: v
3.2. Splash settings and scrapy-splash
To install Splash , you must first have Docker . Once you have Docker , you just need to run the following 2 commands:
1 2 | $ sudo docker pull scrapinghub/splash |
1 2 | $ sudo docker run -p 8050:8050 scrapinghub/splash |
Currently only swords only, want to use more swords, then continue to use the following command to install scrapy-splash :
1 2 | $ pip install scrapy scrapy-splash |
Add a little config in the settings.py file as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # ... SPLASH_URL = 'http://localhost:8050' DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' COOKIES_ENABLED = True # Nếu cần dùng Cookie SPLASH_COOKIES_DEBUG = False SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 400, } DOWNLOAD_DELAY = 10 # ... |
Okayyy, so Splash and scrapy-splash is fully installed, you have enough swords, let’s go =)))
3.3. Identify the target data you want to crawl
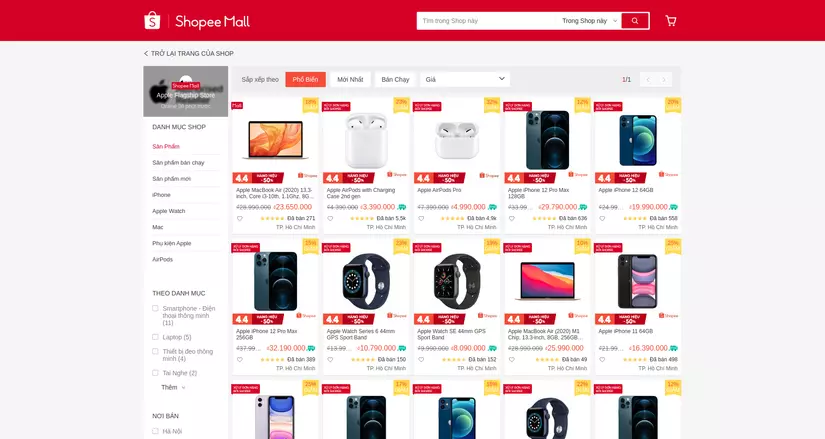
Enter the Apple Flagship Store to see what information you can get on this page. Observing and I can get important information such as product name, original price, promotional price, how much has been sold. Turn on inspect and analyze the website structure to be able to select the elements in the DOM correctly =))
Next, create a new class ProductItem to define the data you want to get in the items.py file as follows:
1 2 3 4 5 6 | class ProductItem(scrapy.Item): name = scrapy.Field() price = scrapy.Field() price_sale = scrapy.Field() sold = scrapy.Field() |
Now, go back to ShopeeCrawlSpider to crawl this shop, I will show the code and explain below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | import scrapy from scrapy_splash import SplashRequest from demo_scrapy.items import ProductItem class ShopeeCrawlSpider(scrapy.Spider): name = 'shopee_crawl' allowed_domains = ['shopee.vn'] start_urls = ['https://shopee.vn/shop/88201679/search'] render_script = """ function main(splash) local url = splash.args.url assert(splash:go(url)) assert(splash:wait(5)) return { html = splash:html(), url = splash:url(), } end """ def start_requests(self): for url in self.start_urls: yield SplashRequest( url, self.parse, endpoint='render.html', args={ 'wait': 5, 'lua_source': self.render_script, } ) def parse(self, response): item = ProductItem() for product in response.css("div.shop-search-result-view__item"): item["name"] = product.css("div._36CEnF ::text").extract_first() item["price"] = product.css("div._3_-SiN ::text").extract_first() item["price_sale"] = product.css("span._29R_un ::text").extract_first() item["sold"] = product.css("div.go5yPW ::text").extract_first() yield item |
Now I will explain what the above code did:
- About the
name,domainandstart_urlsI explained in the previous post so I won’t repeat it here. - Normally, Scrapy will
parsedirectly from the urls in thestart_urlslist, but because there is a first step using JS, we can’t do it, we have to go through thestart_requestsfunction, useSplashRequestwait 5s and returnhtml,urlis rendered for the upcoming request using therender_scriptfragment written in the script as shown above. There is a little suggestion that after you open port 8050 for Splash , you can go to0.0.0.0:8050to see the examples that Splash has built in for us or can go to the docs API. Lua’s script if you need to write more complex scripts. - After the
htmlandurlhave been rendered, the request is sent directly to the parse, at this time the response of the parse will be the rendered web page with theurlcorresponding to the aboveSplashRequesturl. - Now the
responsehas been fully rendered inhtml, go back to selecting the correct selector to get the data you want, if it’s too difficult, just turn on inspect and copy the selector, remember to analyze it carefully. before that select: v
3.4. Proceed to crawl the data
Okayyy, having taken the time to carry the sword to the shop, now see the results obtained after conquering this shop with the following command:
1 2 | scrapy crawl shopee_crawl -o product.json |
Remember to add User-Agent in DEFAULT_REQUEST_HEADERS or the local variable USER_AGENT in the settings.py file to prevent bot crawling. Now, open the product.json file to see if the data that I got is really the same with the shop or not:
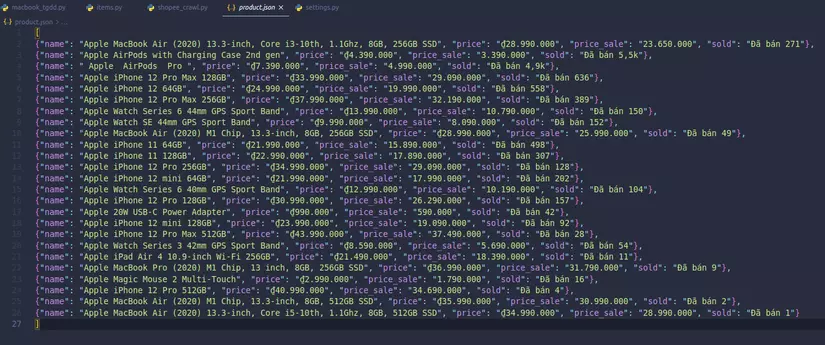
Check a little, and see that the number of products and crawled information are matched, successful =))
4. Conclusion
So I completed a small demo to introduce the basics of the combination of Scrapy and Splash . Actually, this is a highly appreciated combination compared to other solutions I can read such as using Requests-HTML (only for Python> 3.6) or Selenium (Consume more system resources when make lots of requests while crawling => overload).
As I noted in the previous post , my post can only be crawled during the time I write, you need to keep track of shopee interface updates to see if they have changed the HTML or not to adjust the selector accordingly. , avoid HTML changes that lead to the wrong selector not being able to correctly crawl the data.
Maybe in the next post, I will perform a detailed crawl of information contained in each product and take into account that the website has product pagination.
Thank you for taking the time to read your article, if there is anything missing, you can leave a comment below the article to study and improve. (bow)
5. References
https://medium.com/@doanhtu/scrapy-and-splash- marriage-couples-quite-viet-c7745dc9ab56