Text data processing and model Fine-tuning
- Tram Ho
Hello everyone, today I will learn with you how to process text data as well as fine-tune model with text classification task.
More libraries for data processing
1 2 3 4 5 6 7 8 9 10 11 12 | import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np from collections import defaultdict from collections import Counter from nltk.corpus import stopwords import string plt.style.use('ggplot') import re from tqdm import tqdm |
Exploratory Data Analysis
The data set I used for this task is a disaster tweet on kaggle, you can download it via this link: https://www.kaggle.com/c/nlp-getting-started/data
1 2 3 | train = pd.read_csv('train.csv') train.head(5) |

1 2 3 | print('There are {} rows and {} columns in train'.format(train.shape[0],train.shape[1])) print('There are {} rows and {} columns in test'.format(test.shape[0],test.shape[1])) |
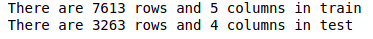
Class distribution
1 2 3 4 5 | x = train.target.value_counts() sns.barplot(x.index, x) plt.gca().set_ylabel('samples') plt.show() |
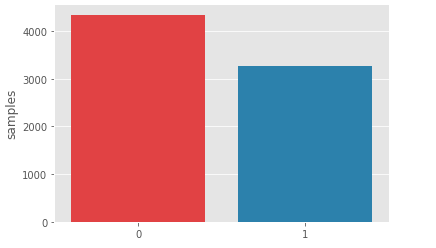
We can see that the distribution of the training set is slightly skewed towards the non-disaster tweets portion. But it’s okay, it’s just a bit off
Average word length in a tweet
1 2 3 4 5 6 7 8 9 | fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5)) word = train[train['target']==1]['text'].str.split().map(lambda x: [len(i) for i in x]) sns.distplot(word.map(lambda x: np.mean(x)), ax=ax1, color='red') ax1.set_title('Disaster tweets') word = train[train['target']==0]['text'].str.split().map(lambda x: [len(i) for i in x]) sns.distplot(word.map(lambda x: np.mean(x)), ax=ax2, color='blue') ax2.set_title('Not Disaster tweets') plt.show() |
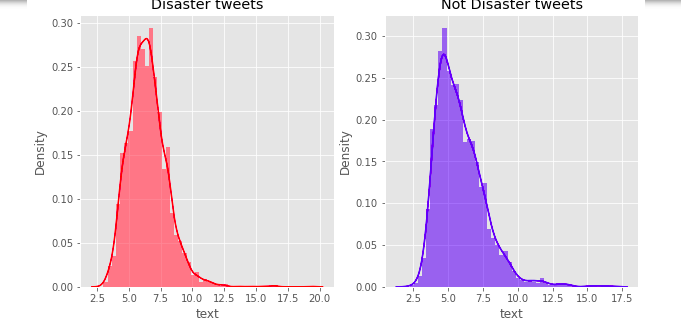
We can see that on the disaster tweets side there are more words used for each word (probably due to emphasis).
Consider the amount of stopwords in the samples
Create a separate corpus constructor for each target for easy comparison
1 2 3 4 5 6 7 8 9 | def create_corpus(target): corpus = [] for x in train[train['target']==target]['text'].str.split(): for i in x: corpus.append(i) return corpus |
Let’s try to see which stopwords are used the most
1 2 3 4 5 6 7 8 9 10 11 | stop = set(stopwords.words('english')) corpus = create_corpus(0) dic = defaultdict(int) for word in corpus: if word in stop: dic[word] += 1 top = sorted(dic.items(), key=lambda x:x[1], reverse=True)[:10] x, y = zip(*top) sns.barplot(list(x), list(y)) plt.show() |
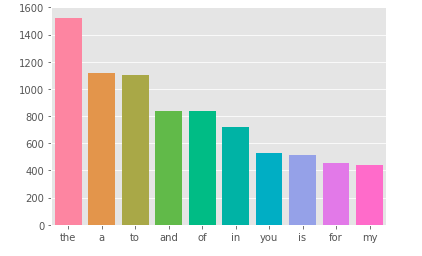
Similar to target = 1 we have:
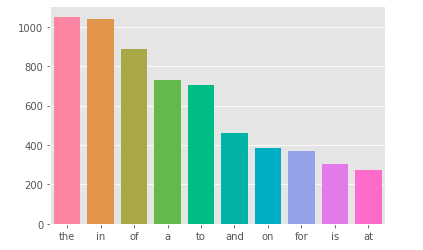
In the text classification task, stopwords play a not too important role, we can consider removing them to help reduce the sentence length.
Consider the amount of punctuation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | plt.figure(figsize=(10, 5)) corpus = create_corpus(1) dic = defaultdict(int) import string special = string.punctuation for word in corpus: if word in special: dic[word] += 1 top = sorted(dic.items(), key= lambda x: x[1], reverse=True) x, y = zip(*top) sns.barplot(list(x), list(y)) plt.show() |
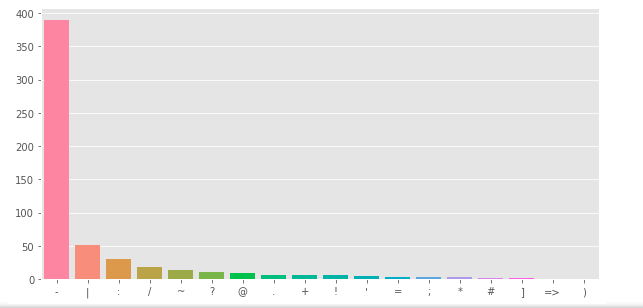
Same with target = 0
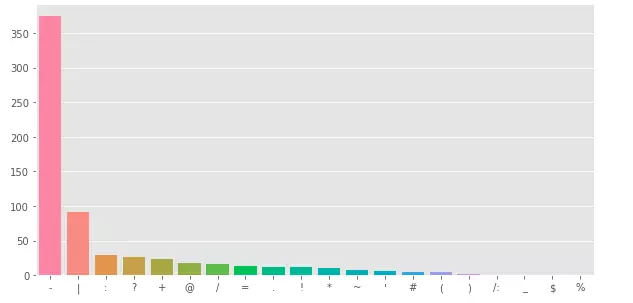
Data Cleaning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | def remove_URL(text): url = re.compile(r'http\S+|www\S+') return url.sub(r'', text) def remove_html(text): html = re.compile(r'<.*?>') return html.sub(r'', text) def remove_emoji(text): emoji_pattern = re.compile("[" u"\U0001F600-\U0001F64F" # emoticons u"\U0001F300-\U0001F5FF" # symbols & pictographs u"\U0001F680-\U0001F6FF" # transport & map symbols u"\U0001F1E0-\U0001F1FF" # flags (iOS) u"\U00002702-\U000027B0" u"\U000024C2-\U0001F251" "]+", flags=re.UNICODE) return emoji_pattern.sub(r'', text) def remove_punct(text): table = str.maketrans('', '', string.punctuation) return text.translate(table) def remove_tag(text): tag = re.compile(r'@\S+') return tag.sub(r'', text) def remove_stw(text): for x in text.split(): if x.lower() in stop: text = text.replace(x, "", 1) return text def remove_number(text): num = re.compile(r'[-+]?[.\d]*[\d]+[:,.\d]*') return num.sub(r' NUMBER', text) |
Since I find that deleting stopwords reduces the model performance a bit and my RAM is still to process, I will not delete stopwords, but everyone can try
1 2 3 4 5 6 7 8 9 10 11 | def clean_tweet(text): text = remove_URL(text) text = remove_html(text) text = remove_emoji(text) text = remove_punct(text) text = remove_tag(text) text = remove_number(text) # text = remove_stw(text) ở đây thì mình thấy xóa stopwords làm giảm hiệu xuất model của mình, các bạn có thể thử return text |
1 2 | df['text'] = df['text'].map(lambda x: clean_tweet(x)) |
Here we will change some abbreviated words into complete words, making the tokenizer work effectively (I refer to this link: https://www.kaggle.com/ghaiyur/ensemble-models-versiong)
1 2 3 4 | def word_abbrev(word): return abbreviations[word.lower()] if word.lower() in abbreviations.keys() else word df['text'] = df['text'].str.split().map(lambda x: [word_abbrev(i) for i in x]).map(lambda x: ' '.join(x)) |
Split train-test set
I will divide the train-test in a ratio of 0.7:0.3 due to the relatively small amount of data. (I refer to Andrew Ng’s video.: https://www.youtube.com/watch?v=1waHlpKiNyY)
1 2 3 4 | from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(list(df['text']), list(df['target']), test_size=0.3) |
Model
Here I use PyTorch and use the transformers library of Hugging Face to use pretrained Roberta. There are two approaches, fine-tuning and feature-based. Here I will fine-tuning so that the Roberta model can be learned.
1 2 3 4 5 6 7 8 | from transformers import RobertaTokenizer, RobertaModel import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim DEVICE = torch.device('cuda:1') tokenizer = RobertaTokenizer.from_pretrained('roberta-base') |
Here I use bidirectional LSTM for downstream task (text classification) and Embedding has been pre-trained by Roberta and extracted to layer 12 by Roberta.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | class Classifier(nn.Module): def __init__(self, input_size, hidden_size, num_layers, dropout): super(Classifier, self).__init__() self.embedding = RobertaModel.from_pretrained('roberta-base') self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout, bidirectional=True) self.out = nn.Linear(hidden_size*2, 2) self.num_layers = num_layers self.hidden_size = hidden_size def forward(self, X, init): embedded = self.embedding(X).last_hidden_state out, _ = self.lstm(embedded, init) output = self.out(out[:, -1, :]) return output def initialize(self, bsz): return (torch.zeros(2 * self.num_layers, bsz, self.hidden_size, device=DEVICE), torch.zeros(2 * self.num_layers, bsz, self.hidden_size, device=DEVICE)) |
Model initialization
1 2 3 4 5 6 7 8 9 10 | from transformers import AdamW from torch.optim.lr_scheduler import StepLR batch_size = 32 model = Classifier(768, 256, 2, 0.1).to(DEVICE) criterion = nn.CrossEntropyLoss() optimizer = AdamW(model.parameters(), lr=5e-5, eps=1e-8) train_iter = [i for i in zip(X_train, y_train)] test_iter = [i for i in zip(X_test, y_test)] scheduler = StepLR(optimizer, step_size=15, gamma=0.1) |
Create a train function according to epoch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | from torch.utils.data import DataLoader def train_epoch(model, optimizer): model.train() losses = 0 train_dataloader = DataLoader(train_iter, batch_size=batch_size, shuffle=True) correct = 0 total = 0 for X, y in tqdm(train_dataloader, colour='green'): tokens = tokenizer(X, return_tensors='pt', padding=True)['input_ids'].to(DEVICE) init = model.initialize(tokens.size(0)) y = y.to(DEVICE) output = model(tokens, init) _, predicted = torch.max(output.data, 1) total += y.size(0) correct += (predicted == y).sum().item() optimizer.zero_grad() loss = criterion(output, y) loss.backward() optimizer.step() losses += loss.item() print('Accuracy: ', 100 * correct / total, "%" ) return losses / len(train_dataloader) |
Create function test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def test(model): model.eval() correct = 0 total = 0 test_dataloader = DataLoader(test_iter, batch_size=32, shuffle=False) for X, y in tqdm(test_dataloader, colour='green'): tokens = tokenizer(X, return_tensors='pt', padding=True)['input_ids'].to(DEVICE) init = model.initialize(tokens.size(0)) y = y.to(DEVICE) output = model(tokens, init) _, predicted = torch.max(output.data, 1) total += y.size(0) correct += (predicted == y).sum().item() print('Accuracy: ', 100 * correct / total, "%" ) |
Training
1 2 3 4 5 6 7 8 9 10 11 12 | from timeit import default_timer as timer NUM_EPOCHS = 100 for epoch in range(1, NUM_EPOCHS+1): start_time = timer() train_loss = train_epoch(model, optimizer) scheduler.step() end_time = timer() print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s")) test(model) |
Summary
So, I have learned with everyone how to process text data and fine-tune a pretrained models. Hope this post is useful to everyone.
References
https://www.kaggle.com/gunesevitan/nlp-with-disaster-tweets-eda-cleaning-and-bert
https://www.kaggle.com/shahules/basic-eda-cleaning-and-glove