The text format is a hugely popular format, either on HDFS or anywhere. The text file data is presented in lines, each line can be considered as a record and marked with the end ” n” (a newline character). The advantage of the text file is light, but it has the disadvantage of slow read and write and cannot split files.

Apache Parquet is a column storage format available for any project in the Hadoop ecosystem, regardless of the choice of a data processing framework, data model, or programming language. Instead of storing data in contiguous rows, parquet can store data by adjacent columns. So data is partitioned both horizontally and vertically. Apache parquet overcomes the disadvantages of text files, reduces I / O time, better compression due to column-organized data, …
See also :Free hosting, a lifetime domain, suitable for students
This article I will talk about reading data from a text file and recording the read data into a parquet file on hdfs using Spark. On hdfs, not the local disk, so before you do you have to start hdfs first.
Generally speaking, the other parts are long but all related to Spark is extremely simple and fast.
Read data from text file using Spark
First of all we have a data set with text file:sample_text , which is the .dat files in this directory. Data is represented on lines, each line represents the properties of an object separated by the character ” t”. To know in order what are the corresponding attributes, we should note that the log.txt file model is recorded as follows:
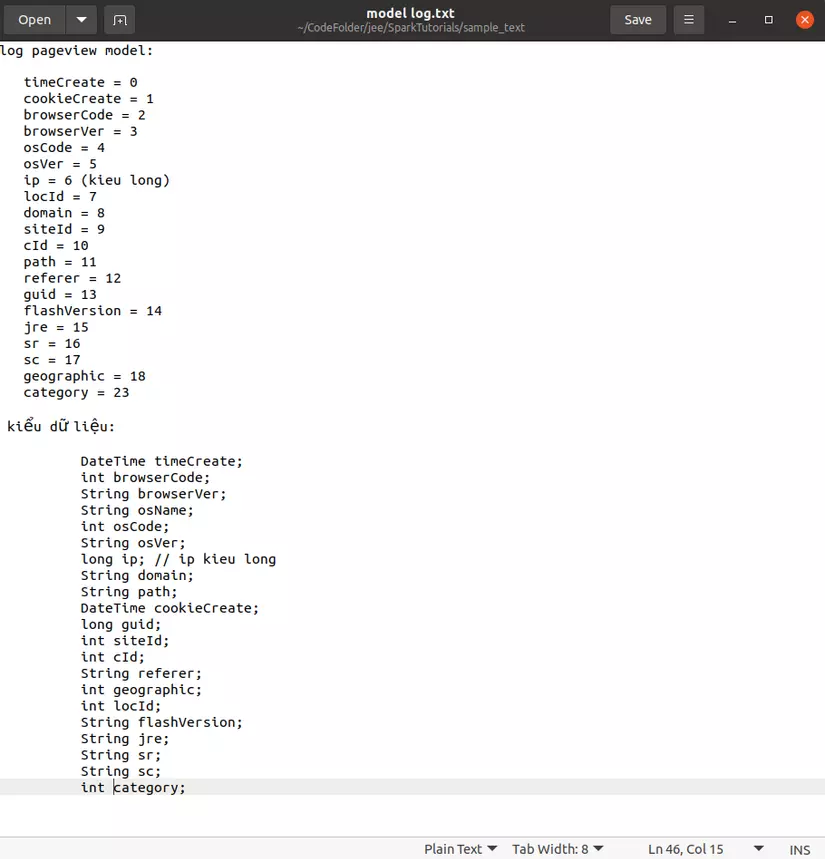
From this file we can see that the first attribute defined on each line is timeCreate , followed by cookieCreate , … and the data types of the attributes defined below (like timeCreate and cookieCreate will be). Date).
From this information we can immediately create a ModelLog object with the above properties to store data from these text files as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | private Date timeCreate; private int browserCode; private String browserVer; private String osName; private int osCode; private String osVer; private long ip; private String domain; private String path; private Date cookieCreate; private long guid; private int siteId; private int cId; private String referer; private int geographic; private int locId; private String flashVersion; private String jre; private String sr; private String sc; private String category; |
To read the data from the text file above, we will declare a JavaSparkContext and browse each line to spread the object and save it in a listModelLog as follows:
1 2 3 4 5 6 7 8 9 10 | SparkConf conf = new SparkConf().setAppName("Read file text from HDFS").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> lines = sc.textFile(pathFile); for(String line : lines.collect()) { ModelLog model = splitLine(line); listModelLog.add(model); } |
The splitLine function will strip properties of an object separated by the character ” t”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | String[] tokenizer = line.split("t"); Date timeCreate = new SimpleDateFormat("dd-MM-yyyy hh:mm:ss").parse(tokenizer[0]); Date cookieCreate = new SimpleDateFormat("dd-MM-yyyy hh:mm:ss").parse(tokenizer[1]); int browserCode = Integer.parseInt(tokenizer[2]); String browserVer = tokenizer[3]; int osCode = Integer.parseInt(tokenizer[4]); String osVer = tokenizer[5]; long ip = Long.parseLong(tokenizer[6]); int locId = Integer.parseInt(tokenizer[7]); String domain = tokenizer[8]; int siteId = Integer.parseInt(tokenizer[9]); int cId = Integer.parseInt(tokenizer[10]); String path = tokenizer[11]; String referer = tokenizer[12]; long guid = Long.parseLong(tokenizer[13]); String flashVersion = tokenizer[14]; String jre = tokenizer[15]; String sr = tokenizer[16]; String sc = tokenizer[17]; int geographic = Integer.parseInt(tokenizer[18]); String category = tokenizer[23]; String osName = tokenizer[5]; ModelLog tmpModelLog = new ModelLog(timeCreate, browserCode, browserVer, osName, osCode, osVer, ip, domain, path, cookieCreate, guid, siteId, cId, referer, geographic, locId, flashVersion, jre, sr, sc, category); return tmpModelLog; |
So after running, we have listModelLog get all the data in the text file. I also see that the article is a bit long but it leads to boring, so stop writing data to a parquet file using Spark, I will write another article in the next section. See the next section HERE
Reference: https://www.tailieubkhn.com/