Zalo is organizing a contest about Who for all ACE in “Industry”. One of the three problems is the Motorbike Generator and of course its requirement is the same as the Dog Generator post on Kaggle, each output is 128×128 and the Dog Generator is 64×64: v. And I also join in the fun with a spirit of 3H – Ham learn: v. This article I mention my experience in data observation, image processing, as well as model training … This is just my experience in the process of doing and learning, if any. Wrong place to expect people to kick gently  )
)
Request math problems
Understand simply to use 10000 that Zalo gives and generates 10000 images with PNG format from the given data set, the evaluation metric is FID. 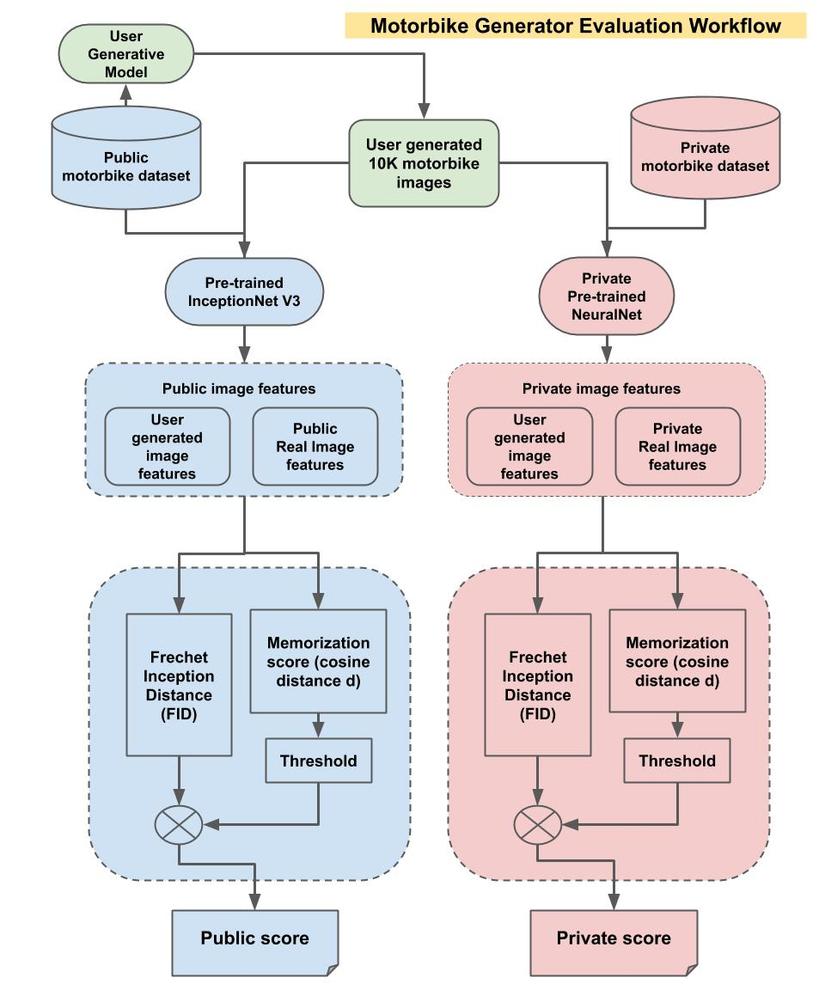
Theory
To read more about FID evalutation, please read here
I will use RaLSGAN for this problem. So what is RaLSGAN? TL: it is just a normal GAN network but with an optimal loss function
Loss Functions

A discriminator output can be a sigmoid or linear trigger function. If it’s a sigmoid we have a discrete probability distribution of an image that is actually Pr (real) . For linear we have C (x) = logit . Probability is within (0.1). And logit can be any number in the range (0,1). Positive numbers represent real images, while negative numbers represent fake images.
Simple loss
We call x_r as a real image, and x_f is a fake image, we will have D (x) = Pr (Real) or C (x) = Logit will become 2 ouptput of a Discriminator when input is an image, Loss Function will as follows:
1 2 3 4 | # Take AVG over x_r and x_f in batch disc_loss = (1 - D(x_r)) + (D(x_f) - 0) gen_loss = (1 - D(x_f)) |
We want Discriminator D (x_r) = 1 and D (x_f) = 0 equivalent to real and fake labels, and after the training is complete, the Generator is as close to 1 as possible. In a nutshell, we use real photos as a training data set for Discriminator so that the network can distinguish between real and fake images, and from there Discriminator will give feedback to Generator so that it can improve itself based on feedback. That’s why D (x_r) = 1 and D (x_f) = 0. If you want to learn more about GAN, please read here.
DCGAN Loss
We clearly see Basic GAN and DCGAN using D (x):
1 2 3 4 | # Take AVG over x_r and x_f in batch disc_loss = -log (D(x_r)) - log (1-D(x_f)) gen_loss = -log (D(x_f)) |
RaLSGAN Loss
RaLSGAN uses C (x) = logit:
1 2 3 4 | # Take AVG over x_r and x_f in batch disc_loss = (C(x_r) - AVG(C(x_f)) - 1)^2 + (C(x_f) - AVG(C(x_r)) + 1)^2 gen_loss = (C(x_r) - AVG(C(x_f)) + 1)^2 + (C(x_f) - AVG(C(x_r)) - 1)^2 |
Code
We will use pytorch to code for this problem, the first is to change the activation function from sigmoid to logit (possibly fishy) on the last line:
1 2 3 | <span class="token comment">#x = torch.sigmoid(self.conv5(x))</span> x <span class="token operator">=</span> self <span class="token punctuation">.</span> conv5 <span class="token punctuation">(</span> x <span class="token punctuation">)</span> |
Next we will update the loss of G and D:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | <span class="token comment">############################</span> <span class="token comment"># (1) Update D network</span> <span class="token comment">###########################</span> netD <span class="token punctuation">.</span> zero_grad <span class="token punctuation">(</span> <span class="token punctuation">)</span> real_images <span class="token operator">=</span> real_images <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> batch_size <span class="token operator">=</span> real_images <span class="token punctuation">.</span> size <span class="token punctuation">(</span> <span class="token number">0</span> <span class="token punctuation">)</span> labels <span class="token operator">=</span> torch <span class="token punctuation">.</span> full <span class="token punctuation">(</span> <span class="token punctuation">(</span> batch_size <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> real_label <span class="token punctuation">,</span> device <span class="token operator">=</span> device <span class="token punctuation">)</span> outputR <span class="token operator">=</span> netD <span class="token punctuation">(</span> real_images <span class="token punctuation">)</span> noise <span class="token operator">=</span> torch <span class="token punctuation">.</span> randn <span class="token punctuation">(</span> batch_size <span class="token punctuation">,</span> nz <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> device <span class="token operator">=</span> device <span class="token punctuation">)</span> fake <span class="token operator">=</span> netG <span class="token punctuation">(</span> noise <span class="token punctuation">)</span> outputF <span class="token operator">=</span> netD <span class="token punctuation">(</span> fake <span class="token punctuation">.</span> detach <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> errD <span class="token operator">=</span> <span class="token punctuation">(</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">(</span> outputR <span class="token operator">-</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> outputF <span class="token punctuation">)</span> <span class="token operator">-</span> labels <span class="token punctuation">)</span> <span class="token operator">**</span> <span class="token number">2</span> <span class="token punctuation">)</span> <span class="token operator">+</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">(</span> outputF <span class="token operator">-</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> outputR <span class="token punctuation">)</span> <span class="token operator">+</span> labels <span class="token punctuation">)</span> <span class="token operator">**</span> <span class="token number">2</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token number">2</span> errD <span class="token punctuation">.</span> backward <span class="token punctuation">(</span> retain_graph <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> optimizerD <span class="token punctuation">.</span> step <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token comment">############################</span> <span class="token comment"># (2) Update G network</span> <span class="token comment">###########################</span> netG <span class="token punctuation">.</span> zero_grad <span class="token punctuation">(</span> <span class="token punctuation">)</span> outputF <span class="token operator">=</span> netD <span class="token punctuation">(</span> fake <span class="token punctuation">)</span> errG <span class="token operator">=</span> <span class="token punctuation">(</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">(</span> outputR <span class="token operator">-</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> outputF <span class="token punctuation">)</span> <span class="token operator">+</span> labels <span class="token punctuation">)</span> <span class="token operator">**</span> <span class="token number">2</span> <span class="token punctuation">)</span> <span class="token operator">+</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">(</span> outputF <span class="token operator">-</span> torch <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> outputR <span class="token punctuation">)</span> <span class="token operator">-</span> labels <span class="token punctuation">)</span> <span class="token operator">**</span> <span class="token number">2</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token number">2</span> errG <span class="token punctuation">.</span> backward <span class="token punctuation">(</span> <span class="token punctuation">)</span> optimizerG <span class="token punctuation">.</span> step <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
Data processing
In all DL problems, data is always the most important thing, and the first thing we have to do is to look at the data set and find the characteristics to handle on demand. And as we see our data set includes 10,000 images including:
- Different sizes and formats
- Many featured GIF images and errors
- Data is uneven
- Many vehicles or obstacles in a photo
- Most of the images have a horizontal rotation
- Many vehicles have normal and heterogeneous characteristics with the data set
Treatment:
- Eliminate leftover images and classify vehicles using yolov3 Here .
- After removing the leftovers and classifying the car, we will filter the data manually, because the data set includes a lot of diverse vehicles and incorrectly formatted images.
- Eliminate vehicles with redundant details and few in the data set, generally referred to as non-diverse vehicles with “heterogeneous” characteristics
- Remove images that have a background that is too colorful
Preprocessing
After finishing the above process to come up with a good data set, all we need to do is to bring the image to the size of 128×128 to put on the network. There are 2 options for this:
- Padding images: add space inside the image, this space will be added to the width or height of the image without image distortion.
- Resize images: Bring the image to size 128×128 always and stretch the image by width or height But the problem is that when I finished training and tried both cases and FID evaluation, found padding images for better results, which means more effective learning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | <span class="token keyword">def</span> <span class="token function">padding_image</span> <span class="token punctuation">(</span> img <span class="token punctuation">)</span> <span class="token punctuation">:</span> im <span class="token operator">=</span> mpimg <span class="token punctuation">.</span> imread <span class="token punctuation">(</span> img <span class="token punctuation">)</span> old_size <span class="token operator">=</span> im <span class="token punctuation">.</span> shape <span class="token punctuation">[</span> <span class="token punctuation">:</span> <span class="token number">2</span> <span class="token punctuation">]</span> <span class="token comment"># old_size is in (height, width) format</span> ratio <span class="token operator">=</span> <span class="token builtin">float</span> <span class="token punctuation">(</span> desired_size <span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> old_size <span class="token punctuation">)</span> new_size <span class="token operator">=</span> <span class="token builtin">tuple</span> <span class="token punctuation">(</span> <span class="token punctuation">[</span> <span class="token builtin">int</span> <span class="token punctuation">(</span> x <span class="token operator">*</span> ratio <span class="token punctuation">)</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> old_size <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token comment"># new_size should be in (width, height) format</span> im <span class="token operator">=</span> cv2 <span class="token punctuation">.</span> resize <span class="token punctuation">(</span> im <span class="token punctuation">,</span> <span class="token punctuation">(</span> new_size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> new_size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> delta_w <span class="token operator">=</span> desired_size <span class="token operator">-</span> new_size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> delta_h <span class="token operator">=</span> desired_size <span class="token operator">-</span> new_size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> top <span class="token punctuation">,</span> bottom <span class="token operator">=</span> delta_h <span class="token operator">//</span> <span class="token number">2</span> <span class="token punctuation">,</span> delta_h <span class="token operator">-</span> <span class="token punctuation">(</span> delta_h <span class="token operator">//</span> <span class="token number">2</span> <span class="token punctuation">)</span> left <span class="token punctuation">,</span> right <span class="token operator">=</span> delta_w <span class="token operator">//</span> <span class="token number">2</span> <span class="token punctuation">,</span> delta_w <span class="token operator">-</span> <span class="token punctuation">(</span> delta_w <span class="token operator">//</span> <span class="token number">2</span> <span class="token punctuation">)</span> color <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">]</span> new_im <span class="token operator">=</span> cv2 <span class="token punctuation">.</span> copyMakeBorder <span class="token punctuation">(</span> im <span class="token punctuation">,</span> top <span class="token punctuation">,</span> bottom <span class="token punctuation">,</span> left <span class="token punctuation">,</span> right <span class="token punctuation">,</span> cv2 <span class="token punctuation">.</span> BORDER_CONSTANT <span class="token punctuation">,</span> value <span class="token operator">=</span> color <span class="token punctuation">)</span> new_im <span class="token operator">=</span> <span class="token punctuation">(</span> new_im <span class="token operator">-</span> <span class="token number">127.5</span> <span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token number">127.5</span> <span class="token keyword">return</span> new_im |
Read the path of the image:
1 2 3 4 5 6 7 8 | PATH <span class="token operator">=</span> <span class="token string">'../dataset'</span> OUTPUT_PATH <span class="token operator">=</span> <span class="token string">'../padding_image_last'</span> files <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token comment"># r=root, d=directories, f = files</span> <span class="token keyword">for</span> r <span class="token punctuation">,</span> d <span class="token punctuation">,</span> f <span class="token keyword">in</span> os <span class="token punctuation">.</span> walk <span class="token punctuation">(</span> PATH <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> <span class="token builtin">file</span> <span class="token keyword">in</span> f <span class="token punctuation">:</span> files <span class="token punctuation">.</span> append <span class="token punctuation">(</span> os <span class="token punctuation">.</span> path <span class="token punctuation">.</span> join <span class="token punctuation">(</span> r <span class="token punctuation">,</span> <span class="token builtin">file</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> |
Create a loop and call the function to padding Images:
1 2 3 4 | <span class="token keyword">for</span> i <span class="token keyword">in</span> tqdm <span class="token punctuation">(</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> <span class="token number">0</span> <span class="token punctuation">,</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> files <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> img <span class="token operator">=</span> padding_image <span class="token punctuation">(</span> files <span class="token punctuation">[</span> i <span class="token punctuation">]</span> <span class="token punctuation">)</span> matplotlib <span class="token punctuation">.</span> image <span class="token punctuation">.</span> imsave <span class="token punctuation">(</span> os <span class="token punctuation">.</span> path <span class="token punctuation">.</span> join <span class="token punctuation">(</span> OUTPUT_PATH <span class="token punctuation">,</span> f <span class="token string">'image_{i:05d}.jpg'</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> img <span class="token punctuation">)</span> |
After padding images is finished, we images augmentation. I used image capture and image capture techniques, I had previously increased the contrast but the results were quite poor
1 2 3 4 5 6 7 8 9 10 11 | transform1 <span class="token operator">=</span> transforms <span class="token punctuation">.</span> Compose <span class="token punctuation">(</span> <span class="token punctuation">[</span> transforms <span class="token punctuation">.</span> Resize <span class="token punctuation">(</span> <span class="token punctuation">(</span> <span class="token number">128</span> <span class="token punctuation">,</span> <span class="token number">128</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token comment"># Data augmentation and converting to tensors</span> random_transforms <span class="token operator">=</span> <span class="token punctuation">[</span> transforms <span class="token punctuation">.</span> RandomRotation <span class="token punctuation">(</span> degrees <span class="token operator">=</span> <span class="token number">5</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> transform2 <span class="token operator">=</span> transforms <span class="token punctuation">.</span> Compose <span class="token punctuation">(</span> <span class="token punctuation">[</span> transforms <span class="token punctuation">.</span> RandomHorizontalFlip <span class="token punctuation">(</span> p <span class="token operator">=</span> <span class="token number">0.5</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> transforms <span class="token punctuation">.</span> RandomApply <span class="token punctuation">(</span> random_transforms <span class="token punctuation">,</span> p <span class="token operator">=</span> <span class="token number">0.3</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token comment"># transforms.RandomApply([transforms.ColorJitter(brightness=0.2, contrast=(0.9, 1.2), saturation=0.3, hue=0.01)], p=0.5),</span> transforms <span class="token punctuation">.</span> ToTensor <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> transforms <span class="token punctuation">.</span> Normalize <span class="token punctuation">(</span> <span class="token punctuation">(</span> <span class="token number">0.5</span> <span class="token punctuation">,</span> <span class="token number">0.5</span> <span class="token punctuation">,</span> <span class="token number">0.5</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token punctuation">(</span> <span class="token number">0.5</span> <span class="token punctuation">,</span> <span class="token number">0.5</span> <span class="token punctuation">,</span> <span class="token number">0.5</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> |
Training model
As I said above RaLSGan is a normal GAN network it can be DCGAN, or SGAN … but with a better loss function.
The generator will look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | <span class="token keyword">class</span> <span class="token class-name">Generator</span> <span class="token punctuation">(</span> nn <span class="token punctuation">.</span> Module <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">__init__</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> nz <span class="token operator">=</span> <span class="token number">128</span> <span class="token punctuation">,</span> channels <span class="token operator">=</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token builtin">super</span> <span class="token punctuation">(</span> Generator <span class="token punctuation">,</span> self <span class="token punctuation">)</span> <span class="token punctuation">.</span> __init__ <span class="token punctuation">(</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> nz <span class="token operator">=</span> nz self <span class="token punctuation">.</span> channels <span class="token operator">=</span> channels <span class="token keyword">def</span> <span class="token function">convlayer</span> <span class="token punctuation">(</span> n_input <span class="token punctuation">,</span> n_output <span class="token punctuation">,</span> k_size <span class="token operator">=</span> <span class="token number">4</span> <span class="token punctuation">,</span> stride <span class="token operator">=</span> <span class="token number">2</span> <span class="token punctuation">,</span> padding <span class="token operator">=</span> <span class="token number">0</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> block <span class="token operator">=</span> <span class="token punctuation">[</span> nn <span class="token punctuation">.</span> ConvTranspose2d <span class="token punctuation">(</span> n_input <span class="token punctuation">,</span> n_output <span class="token punctuation">,</span> kernel_size <span class="token operator">=</span> k_size <span class="token punctuation">,</span> stride <span class="token operator">=</span> stride <span class="token punctuation">,</span> padding <span class="token operator">=</span> padding <span class="token punctuation">,</span> bias <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> nn <span class="token punctuation">.</span> BatchNorm2d <span class="token punctuation">(</span> n_output <span class="token punctuation">)</span> <span class="token punctuation">,</span> nn <span class="token punctuation">.</span> ReLU <span class="token punctuation">(</span> inplace <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token punctuation">]</span> <span class="token keyword">return</span> block self <span class="token punctuation">.</span> model <span class="token operator">=</span> nn <span class="token punctuation">.</span> Sequential <span class="token punctuation">(</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> self <span class="token punctuation">.</span> nz <span class="token punctuation">,</span> <span class="token number">1024</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token comment"># Fully connected layer via convolution.</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">1024</span> <span class="token punctuation">,</span> <span class="token number">512</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">512</span> <span class="token punctuation">,</span> <span class="token number">256</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">256</span> <span class="token punctuation">,</span> <span class="token number">128</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">128</span> <span class="token punctuation">,</span> <span class="token number">64</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">64</span> <span class="token punctuation">,</span> <span class="token number">32</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> nn <span class="token punctuation">.</span> ConvTranspose2d <span class="token punctuation">(</span> <span class="token number">32</span> <span class="token punctuation">,</span> self <span class="token punctuation">.</span> channels <span class="token punctuation">,</span> <span class="token number">3</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> nn <span class="token punctuation">.</span> Tanh <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">forward</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> z <span class="token punctuation">)</span> <span class="token punctuation">:</span> z <span class="token operator">=</span> z <span class="token punctuation">.</span> view <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> self <span class="token punctuation">.</span> nz <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> img <span class="token operator">=</span> self <span class="token punctuation">.</span> model <span class="token punctuation">(</span> z <span class="token punctuation">)</span> <span class="token keyword">return</span> img |
As we can see, the output of G is 128×128 with more than 13 million parameters
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ ConvTranspose2d-1 [-1, 1024, 4, 4] 2,097,152 BatchNorm2d-2 [-1, 1024, 4, 4] 2,048 ReLU-3 [-1, 1024, 4, 4] 0 ConvTranspose2d-4 [-1, 512, 8, 8] 8,388,608 BatchNorm2d-5 [-1, 512, 8, 8] 1,024 ReLU-6 [-1, 512, 8, 8] 0 ConvTranspose2d-7 [-1, 256, 16, 16] 2,097,152 BatchNorm2d-8 [-1, 256, 16, 16] 512 ReLU-9 [-1, 256, 16, 16] 0 ConvTranspose2d-10 [-1, 128, 32, 32] 524,288 BatchNorm2d-11 [-1, 128, 32, 32] 256 ReLU-12 [-1, 128, 32, 32] 0 ConvTranspose2d-13 [-1, 64, 64, 64] 131,072 BatchNorm2d-14 [-1, 64, 64, 64] 128 ReLU-15 [-1, 64, 64, 64] 0 ConvTranspose2d-16 [-1, 32, 128, 128] 32,768 BatchNorm2d-17 [-1, 32, 128, 128] 64 ReLU-18 [-1, 32, 128, 128] 0 ConvTranspose2d-19 [-1, 3, 128, 128] 867 Tanh-20 [-1, 3, 128, 128] 0 ================================================================ Total params: 13,275,939 Trainable params: 13,275,939 Non-trainable params: 0 ---------------------------------------------------------------- |
Discriminator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | <span class="token keyword">class</span> <span class="token class-name">Discriminator</span> <span class="token punctuation">(</span> nn <span class="token punctuation">.</span> Module <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">__init__</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> channels <span class="token operator">=</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token builtin">super</span> <span class="token punctuation">(</span> Discriminator <span class="token punctuation">,</span> self <span class="token punctuation">)</span> <span class="token punctuation">.</span> __init__ <span class="token punctuation">(</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> channels <span class="token operator">=</span> channels <span class="token keyword">def</span> <span class="token function">convlayer</span> <span class="token punctuation">(</span> n_input <span class="token punctuation">,</span> n_output <span class="token punctuation">,</span> k_size <span class="token operator">=</span> <span class="token number">4</span> <span class="token punctuation">,</span> stride <span class="token operator">=</span> <span class="token number">2</span> <span class="token punctuation">,</span> padding <span class="token operator">=</span> <span class="token number">0</span> <span class="token punctuation">,</span> bn <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> block <span class="token operator">=</span> <span class="token punctuation">[</span> nn <span class="token punctuation">.</span> Conv2d <span class="token punctuation">(</span> n_input <span class="token punctuation">,</span> n_output <span class="token punctuation">,</span> kernel_size <span class="token operator">=</span> k_size <span class="token punctuation">,</span> stride <span class="token operator">=</span> stride <span class="token punctuation">,</span> padding <span class="token operator">=</span> padding <span class="token punctuation">,</span> bias <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token keyword">if</span> bn <span class="token punctuation">:</span> block <span class="token punctuation">.</span> append <span class="token punctuation">(</span> nn <span class="token punctuation">.</span> BatchNorm2d <span class="token punctuation">(</span> n_output <span class="token punctuation">)</span> <span class="token punctuation">)</span> block <span class="token punctuation">.</span> append <span class="token punctuation">(</span> nn <span class="token punctuation">.</span> LeakyReLU <span class="token punctuation">(</span> <span class="token number">0.2</span> <span class="token punctuation">,</span> inplace <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> block self <span class="token punctuation">.</span> model <span class="token operator">=</span> nn <span class="token punctuation">.</span> Sequential <span class="token punctuation">(</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> self <span class="token punctuation">.</span> channels <span class="token punctuation">,</span> <span class="token number">32</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">32</span> <span class="token punctuation">,</span> <span class="token number">64</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">64</span> <span class="token punctuation">,</span> <span class="token number">128</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> bn <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">128</span> <span class="token punctuation">,</span> <span class="token number">256</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> bn <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token operator">*</span> convlayer <span class="token punctuation">(</span> <span class="token number">256</span> <span class="token punctuation">,</span> <span class="token number">512</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> bn <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> nn <span class="token punctuation">.</span> Conv2d <span class="token punctuation">(</span> <span class="token number">512</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">4</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> bias <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token comment"># FC with Conv.</span> <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">forward</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> imgs <span class="token punctuation">)</span> <span class="token punctuation">:</span> out <span class="token operator">=</span> self <span class="token punctuation">.</span> model <span class="token punctuation">(</span> imgs <span class="token punctuation">)</span> <span class="token keyword">return</span> out <span class="token punctuation">.</span> view <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 64, 64] 1,536 LeakyReLU-2 [-1, 32, 64, 64] 0 Conv2d-3 [-1, 64, 32, 32] 32,768 LeakyReLU-4 [-1, 64, 32, 32] 0 Conv2d-5 [-1, 128, 16, 16] 131,072 BatchNorm2d-6 [-1, 128, 16, 16] 256 LeakyReLU-7 [-1, 128, 16, 16] 0 Conv2d-8 [-1, 256, 8, 8] 524,288 BatchNorm2d-9 [-1, 256, 8, 8] 512 LeakyReLU-10 [-1, 256, 8, 8] 0 Conv2d-11 [-1, 512, 4, 4] 2,097,152 BatchNorm2d-12 [-1, 512, 4, 4] 1,024 LeakyReLU-13 [-1, 512, 4, 4] 0 Conv2d-14 [-1, 1, 1, 1] 8,192 ================================================================ Total params: 2,796,800 Trainable params: 2,796,800 Non-trainable params: 0 ---------------------------------------------------------------- |
Output
I have tried a lot of cases to get the best results, so it should be put in the range of 550 – 750 epochs is a pretty good FID result from 80 -> 62
1 2 3 4 5 6 7 | batch_size <span class="token operator">=</span> <span class="token number">64</span> LR_G <span class="token operator">=</span> <span class="token number">0.0008</span> LR_D <span class="token operator">=</span> <span class="token number">0.0008</span> epochs <span class="token operator">=</span> <span class="token number">750</span> real_label <span class="token operator">=</span> <span class="token number">0.8</span> fake_label <span class="token operator">=</span> <span class="token number">0</span> |
Some results: 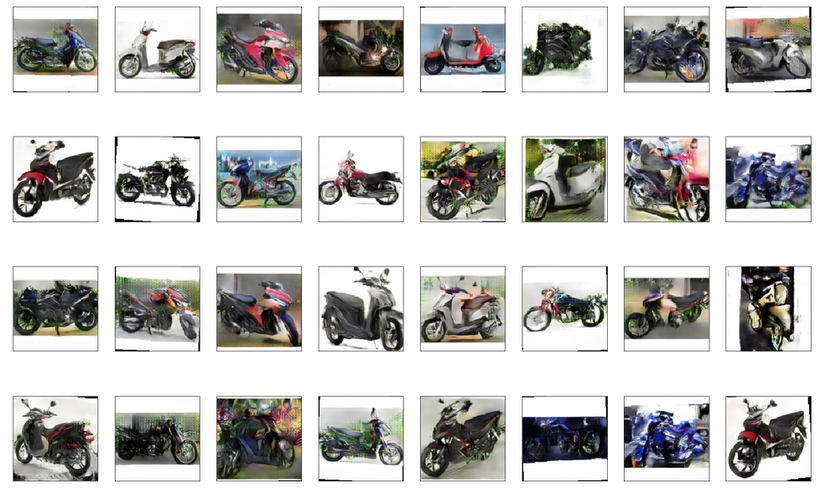
Reference source
https://www.kaggle.com/c/generative-dog-images/discussion/99485