
What is Elasticsearch?
Elasticsearch is a search engine with many simple REST APIs that can analyze and store all formatted data such as textextual, digital, geospatial, structured and unstructured quickly (near real-time).
Elasticsearch , launched in 2010, developed by Shay Banon in the Java language, is open source under the Apache 2.0 license and is distributed in real time, highly scalable and based on the Apache Lucene platform.
Elasticsearch can extend up to petabytes of structured and unstructured data. It can also be used instead of DBs that store document data such as MongoDB or RavenDB. Use non-standardity to improve search performance.
Elasticsearch is one of the very popular business search tools and is currently used by many large organizations such as Wikipedia, The Guardian, StackOverflow, GitHub, …

When to use Elasticsearch?
We should use Elasticsearch in the following cases:
- Searching for pure text (textual search): normal text search.
- Searching text and structured data (product search by name + properties): searching for text and structured data
- Data aggregation, security analytics, analysis of business data: aggregating data, analyzing security, analyzing business data, storing large amounts of data.
- Logging and log analytics: records the process of operation and analyzes it.
- Application performance monitoring: monitoring application performance.
- Infrastructure indicators and container monitoring.
- Geo Search: search by coordinates, analysis and visualization of geospatial data.
- JSON document storage: stores JSON data.
The basic concepts in Elasticsearch
1. Node
Is a single running instance (server) of Elasticsearch . Where to store data, participate in cluster indexing and perform searches.
Each node is identified by a unique name , which is randomly set by the Universally Unique IDentifier (UUID) to proceed when setting up or identifying itself. The node’s name is very important in determining which cluster this node belongs to in Elasticsearch.
2. Cluster
A collection of one or more nodes that work together, capable of searching and indexing all nodes for all data. Cluster’s main function is to decide which shards are allocated to which nodes and when to move the nodes to rebalance the cluster.
Each cluster is identified by a unique name, common to all nodes, so identifying clustered names will cause errors for the nodes.
Each cluster has a master node (master) that is automatically selected and replaceable when something goes wrong.
3. Document
It is the basic data unit in Elasticsearch – JSON object with some specific data. Each document belongs to a type and is in an index. Each document is associated with a unique identifier called a UID.
Elasticsearch uses an inverted index to index documents. Inverted index is an index based on the unit of từ to create link between words and documents containing the word.
4. Type
Used as an index index, allowing to store different types of data in the same index.
5. Index
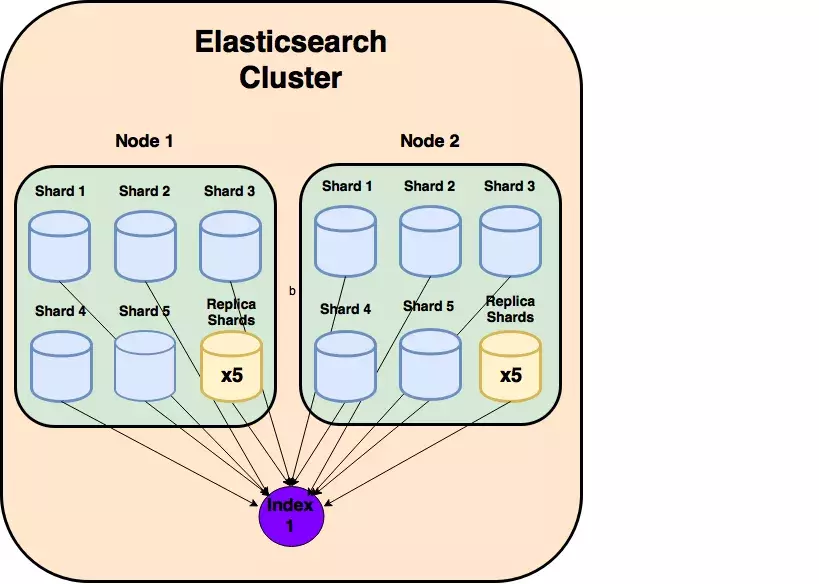
It is a collection of different types of documents and their properties, helping to store large amounts of data that can exceed the hardware limit of the node, slowing down the process of responding to requests from single nodes. Therefore, Index uses the concept of shards (segments) to subdivide them into sections to improve performance.
When creating the index, you can specify the number of shards you want.
The index is also identified by its name, which is used when performing indexing, searching, updating or deleting documents in the index.
6. Shard
Indexes are divided horizontally into shards, each shard containing all properties of the document but containing fewer JSON objects than the index. The horizontal split makes the shard an independent node, which can be stored in any node. Therefore, a node can have many Shards, so the Shard will be the smallest object, operating at the lowest level, serving as a data storage.
Shard is important because:
- Allow horizontal fragmentation to expand the log volume
- Allows dispersion and parallel operation on segments, thereby increasing work efficiency.
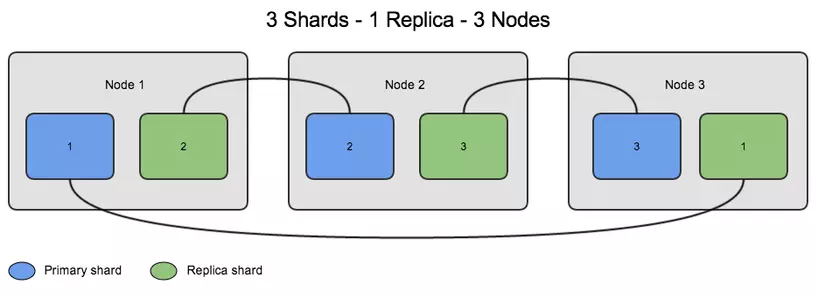
There are two types of shards used: Primary Shard and Replica Shard .
Primary Shard
- The Primary Shard is the horizontal horizontal root of an index and then these primary shards are copied into Replicas Shards.
- Primary Shard will store the data and index it. After hitting the data will be transported to the Replica Shard.
- The default of Elasticsearch is that each index will have 5 Primary Shards and each Primary Shard will have 1 Replica Shard.
Replica Shard
- Primary Shard replica data storage, high availability, replace Primary Shard in the event of an error. That is also why the Replica Shard is not distributed on the same node as the Primary Shard but only copied from it.
- Ensure the integrity of data when Primary Shard has problems such as being hidden or disappearing.
- Enhance the search speed because you can set up more Replica Shard than
Elasticsearchdefault or perform parallel searches in these copies.
How Elasticsearch works
Elasticsearch is built to act as a separate server according to RESTful mechanism for searching data.
First, raw data into Elasticsearch from multiple sources such as logs, system indicators and webapps will be analyzed, processed, normalized and enriched during the import process ( Data ingestion) before being indexed and pushed to Server Elasticsearch in step 2 (how to index yourself will have a more detailed article, not mentioned in this).
Finally, after the data is indexed, users can create complex queries from this data and use aggregations to retrieve complex summaries of the data or in short. is to retrieve data returned from the Elasticsearch server. 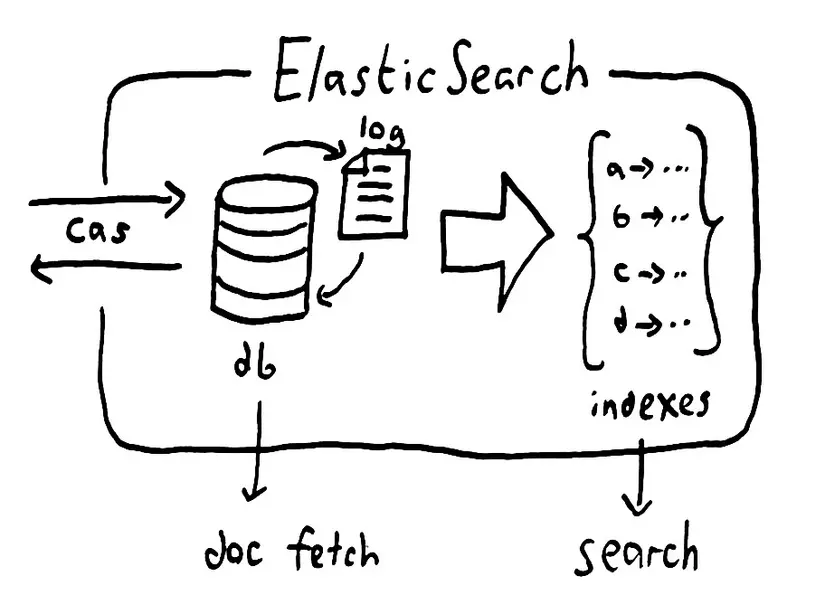
Pros and cons of Elasticsearch
1. Advantages
- Elasticsearch allows finding data quickly with high performance almost real-time (near-realtime searching) because Elasticsearch is designed based on Apache Lucene capable of excel in full-text research.
- Support fuzzy search, which means that the search keyword may have misspellings or incorrect syntax but Elasticsearch can still return the correct results.
- Elasticsearch supports almost all data types, except those that do not support text display.
- The latency between document indexing time and searching it is very short (about 1s), so Elasticsearch is very suitable for urgent use cases such as security analysis or infrastructure monitoring ( security analyzes and infrastructure monitoring).
- Full-text data storage and index lifecycle management, allowing users to access and analyze, synthesize huge amounts of data at high speed and more efficiently.
- Elasticsearch is a natural distributed system, easy to expand and integrate strongly. Documents stored in Elasticsearch are distributed in different containers called partitions, which are duplicated to integrate with duplicate data copies in the event of a hardware failure. The distributed nature of Elasticsearch allows it to expand hundreds (thousands) of servers and manage petabytes of data.
- Easily restore data with full backups created by gateway concepts in Elasticsearch.
- Elasticsearch works like a cloud server, the response format is JSON and is written by Java, so it can work on many different platforms, and interact and support many programming languages such as Java, JavaScript, Node.js. , Go, .NET (C #), PHP, Perl, Python, Ruby. Therefore is also a weakness when the security is not high.
2. Cons
- Elasticsearch does not provide any authentication or authorization features that make ElasticSearch less secure than current database management systems.
- Elasticsearch is designed for search purposes so it is usually not used as the main database. Elasticsearch is not strong in CRUD operations, so it is often used in the same main DB as SQL, MySQL, MongoDB, …
- Another reason not to use Elasticsearch as a DB is that Elasticsearch does not support transactions (database transactions), it will not guarantee data integrity during
insert,update,deleteoperations, which can lead to data loss. - Not suitable for systems that regularly update data because it will be very expensive to index the data.
- Elasticsearch does not support handling requests and responses in many formats (JSON only) compared to another Lucene-based search engine like Apache Solr (supports JSON, CSV, XML).
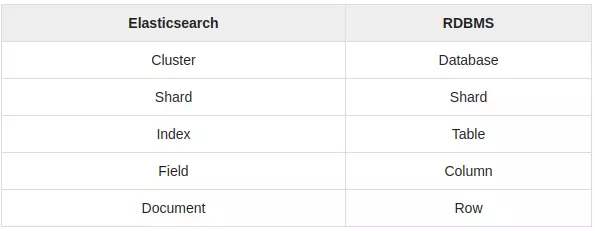
Elasticsearch vs RDBMS
Conclude
This article summarizes some basic issues in Elasticsearch, I hope to be able to help people better understand Elasticsearch. Many thanks for following the article. Good luck 