In the era of technology 4.0 today, maybe you hear a lot about AI, big data Machine Learning or cloud computing … But all those technologies have to rely on that user’s resources, Big data. .
So, what is Big Data ? Big Data is a huge data set and is so complex that traditional tools and data processing techniques cannot afford it. While BIg data is one of the top priorities of technology companies worldwide, what modern technologies will help companies solve Big Data ‘s problems? And today I would like to introduce Hadoop , a framework most commonly used to solve Big Data problems .
1. What is Hadoop?
Hadoop is an open source Apache framework written in Java that enables the development of distributed applications of high data intensity for free. It is designed to scale from a single server to thousands of other computers with local computation and storage. Hadoop was developed based on ideas from Google’s announcement of the Map-Reduce model and the Google File System (GFS). And has provided us with a parallel environment to perform Map-Reduce tasks.
Thanks to the streaming mechanism, Hadoop can develop on distributed applications using both java and some other programming languages such as C ++, Pyhthon, Pearl, …
2. Hadoop architecture
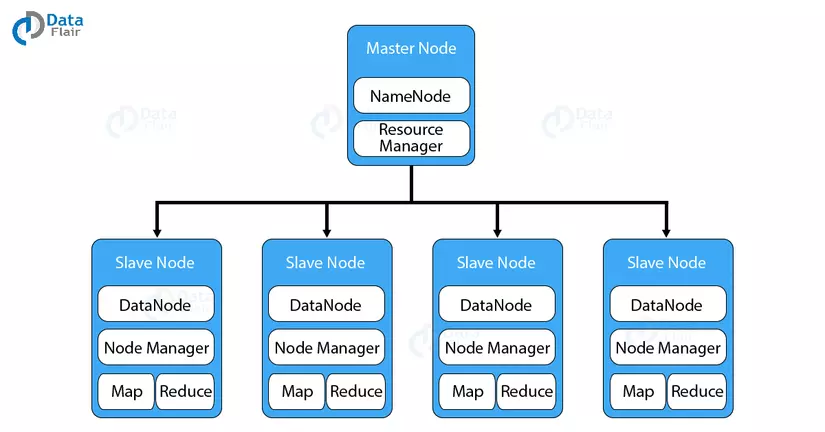
Hadoop has a master-slave topology. In this structure, we have one master node and many slave nodes. The master node’s function is to assign a task to different slave nodes and manage resources. The slave node is the actual computer may not be very powerful. The slave nodes store real data while on master we have metadata.
Hadoop architecture consists of three main classes that are
- HDFS (Hadoop Distributed File System)
- Map-Reduce
- Yarn
2.1 HDFS (Hadoop Distributed File System)
- It is a distributed file system that provides enormous data storage and features to optimize bandwidth usage between nodes. HDFS can be used to run on a large cluster with tens of thousands of nodes.
- Allows access to multiple drives as 1 drive. In other words, we can use a drive with almost no capacity limit. Want to increase the capacity just add nodes (computers) to the system.
- There is a Master-Slave architecture
- NameNode runs on the Master server, manages Namespace, and adjusts file access of the client
- DataNode runs on Slave nodes. It stores the actual business data
- A file in HDFS format is divided into blocks and these blocks are stored in a set of DataNodes
- The usual block size is 64MB, which can be changed by configuration
2.2 Map-Reduce
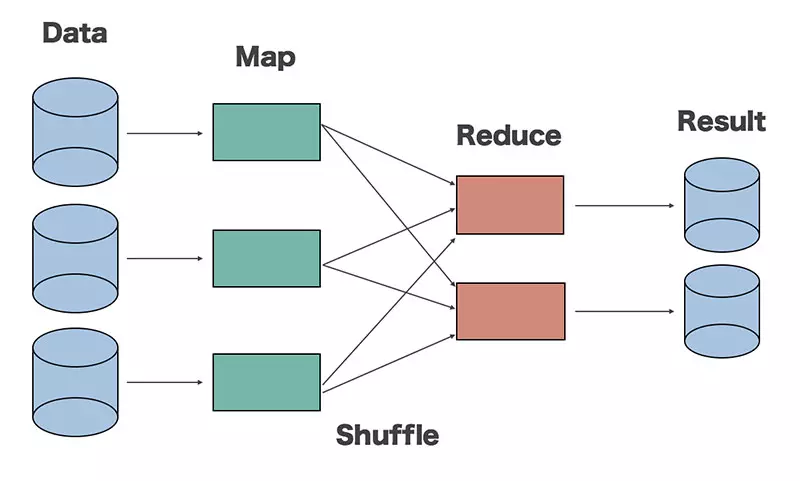
Map-Reduce is a framework used to write applications that process large amounts of fault-tolerant data in parallel across thousands of computer clusters.
Map-Reduce performs two main functions, Map and Reduce
- Map : Will perform first, load and analyze input data and be converted into a data set by key / value pairs
- Reduce : Will receive the output from the Map task, combining data together into a smaller dataset
To make it easier to understand, let’s take a look at the following WordCount example. WordCount is a problem of counting the frequency of words appearing in a paragraph. And we will describe the process of solving this problem by Map-Redue
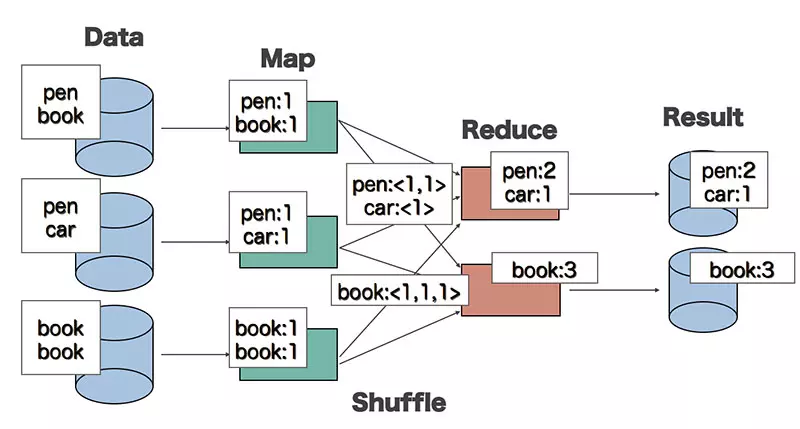
For the Map function:
- Input is a piece of text
- Output are pairs of <word, 1>
The Map function is implemented in parallel to handle different data sets.
For Reduce function:
- The input has the form <word, [list]>, where list is the set of counted values of each word
- Output: <word, the total number of occurrences of the word>
Reduce function is also run in parallel to handle different keyword sets.
Between Map and Reduce functions there is an intermediate processing stage called the Shuffle function. This function is responsible for arranging words and summing input data for Reduce from the outputs of the Map function.
2.3 Yarn
YARN (Yet-Another-Resource-Negotiator) is a framework that supports distributed application development YARN provides the daemons and APIs necessary for developing distributed applications, and processing and scheduling the use of computing resources. math (CPU or memory) and monitor the execution of those applications.
Inside YARN, we have two ResourceManager and NodeManage managers
- ResourceManager: Manage all computing resources of the cluster.
- NodeManger: Monitor container resource usage and report to ResourceManger. The resources here are CPU, memory, disk, network, …
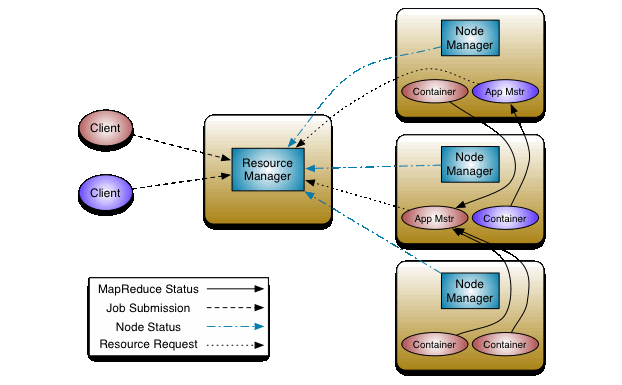
The process of an application running on YARN is described by the diagram above through the following steps:
- Client assigns a task to Resource Manager
- Resource Manager calculates the required resources according to the application’s requirements and creates an App Master (App Mstr). The Application Master is moved to run a computational node. The Application Master will contact the NodeManager at other nodes to issue a job request for this node.
- Node Manager receives requests and runs tasks on containers
- Status information instead of being sent to JobTracker will be sent to App Master.
ResourceManger has two important components that are Scheduler and ApplicationManager
The scheduler is responsible for allocating resources for different applications. This is a pure scheduler because it does not perform state tracking for the application. It also does not rearrange corrupted tasks due to hardware or software failures. The scheduler allocates resources based on application requirements
ApplicationManager has the following function:
- Accept the job submission.
- Negotiate first container to implement ApplicationMaster. A container containing elements such as CPU, memory, disk and network.
- Restart the ApplicationMaster container when it fails.
We can extend YARN beyond a few thousand nodes through the YARN Federation feature. This feature allows us to tie multiple YARN clusters into one large cluster. This allows the use of independent, clustered clusters for a very large job
Refer
http://hadoop.apache.org/docs/current/index.html