What is analytics?
Analysis is the process of converting text into tokens or terms that are added to the inverted index to search. The analysis performed by the analyzer can be either an integrated or custom analyzer defined for each index.
Explain the Analyzing process
When we index the documents for Elaticsearch, the process is as follows: 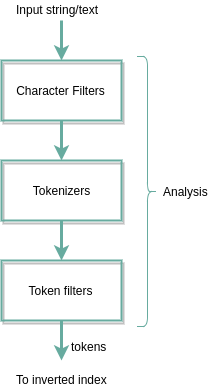
Now I will explain through each stage before creating the inverted index
Character filters
Character filters have the ability to perform additional, delete or replace actions on the provided input text. To get a better idea, if the input string contains a repeated misspelled word and we need to replace it with the correct one, we can use character filters. One of the most common uses for character filters is removing html tags from the input text.
Let’s take a look at Character filters’ operations using the Analyze API of Elaticsearch. Here we will remove html tags from a text with character filters named htmlstrip . The curl request for that is:
1 2 3 4 5 6 7 8 | curl -XPOST 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d '{ "tokenizer": "standard", "char_filter": [ "html_strip" ], "text": "The <b> Auto-generation </b> is a success" }' |
The result has the following tokens:
“The”,”Auto”,”generation”,”is”,”a”,”success”
Here we can see no html tags in the tokens. Similarly, try the above curl without char_filter “char_filter”:[“html_strip”] and see the difference.
Tokenizer
The input text after converting from the Character filter is passed to the tokeniser. Tokeniser will divide this input text into individual tokens (or terms) at specific characters. The default token used in elaticsearch is the standard tokeniser , which uses a grammar-based token technique, which can be extended not only to English but also to many other languages.
Standard tokeniser example:
1 2 3 4 5 | curl -XPOST ‘localhost:9200/_analyze?pretty’ -H ‘Content-Type: application/json’ -d '{ “tokenizer”: “standard”, “text”: “The Auto-generation is a success” }' |
In the response, you can see the text divided into tokens below:
“The”,”Auto”,”generation”,”is”,”a”,”success”
Here words are divided whenever there are spaces and hyphens
Note: There are different types of tokens for different purposes. In some use cases, we may not need to separate special characters, as in the case of email id or url, so to serve token needs like UAX URL Email Tokenizer have available for us to handle. The list of tokens provided by Elaticsearch can be found here
Token filter
After the input text is broken into tokens / terms it is transferred to the final stage of analysis, token filtering. Token filters can work on tokens created from tokenizers and modify, add or delete them. Let us try the token filter with the example below. The token filter we will try here is the lowercase token filter, which will typically write all tokens into it. Ask the following curl to use the Analyze API to demonstrate:
1 2 3 4 5 6 7 8 | curl -XPOST 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d'{ "tokenizer": "standard", "filter": [ "lowercase" ], "text": "The Auto-generation is a success" }' |
The result will produce the following tokens:
“the”,”auto”,”generation”,”is”,”a”,”success”
Note that all tokens are now in lower case. This is what the lowercase token filter does with tokens.
For a list of token filters, visit the link here
Analyzers
The process of analyzing the content of the fields in Elaticsearch’s documents was explained in the previous section. As mentioned in the section above, there are several types of character filters, tokenizers and set of token filters available and we have to choose them wisely according to the use case we are experiencing. The combination of these three components (character filters, tokenizers and token filters) is called Analyzers. There are several types of analysers available in Elaticsearch to handle the most common use cases. For example, Standard Analyzer is Elasticsearch’s default analyzer which consists of a standard tokenizer and 2 token filters (standard token filter, lowercase and stop token filter). Similarly, many types of analyzers may depend on a combination of char filters, tokenizers and token filters.
The general structure of analyzer is shown below:
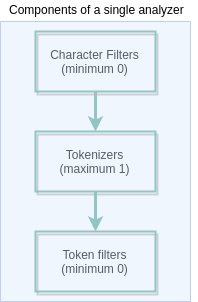
We can also create custom analyzers by selecting the necessary filters and tokenizer.
Analysis Phases
Now that we have a clear picture of what analysis and analyzers are, let’s move on to the two analysis stages that occur in Elaticsearch, index time analysis, and search time analysis.
Index time analysis
We consider the following documents for indexing
1 2 3 4 | curl -XPOST localhost:9200/testindex-0203/testtype/1 -d '{ "text": "My name is Arun" }' |
Since we do not apply analyzers, Elaticsearch applies the default analyzer Standard analyzer. We see the last tokens of the above document when applying Standard Analyzer with the help of Standard Analyzer
1 2 3 4 5 | curl -XPOST 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d'{ "analyzer": "standard", "text": "My name is Arun" }' |
Tokens created to store in an inverted index are:
“my”,”name”,”is”,”arun”
The inverted index will look like the following table:
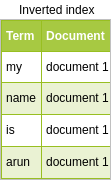
This entire process takes place during index time and is therefore called index time analysis.
Search time analysis
Search time analysis as the name suggests will occur at the time of the search. But one difference is that this analysis occurs on the query depending on which query is used.
Term query – Case 1
Consider the following query:
1 2 3 4 5 6 7 8 | curl -XPOST localhost:9200/testindex-0203/testtype/_search -d '{ “query”: { “term”: { “text”: “name” } } }' |
If we run this query on testindex-0203 index, it will return the indexed document as a result. The “name” token is included in the inverted index and is remapped to document 1. So when we find the term “name”, it will look for the inverted index and because the term is found there, the corresponding document is fetch as results
Term query – Case 2
Now consider another case with the same “term” query, as shown below:
1 2 3 4 5 6 7 8 | curl -XPOST localhost:9200/testindex-0203/testtype/_search -d '{ “query”: { “term”: { “text”: “Name” } } }' |
Similar to the term query case 1, the only difference is that the search keyword is “Name” instead of “name”. Now that something alternating happens, this search won’t give us any documents. The reason for this strange behavior is because “Name” does not exist in the inverted index and therefore there is no document to display.
Therefore, with “term” query no analysis is allowed on the search keyword.
This is the case of a “term” query in elasticsearch. Let’s try another query called match query and check the output.
Match query
Here, when we use the “relationship” query of the user relationship in case 2, it gives no response. But with match queries, any analysis applied to the queryed field (text) at the time of indexing, analysis will also be performed on the search keyword (“Name”). This causes the keyword search to go through “standard analysis” and the “Name” search keyword changes to “name” (Due to the lowercase token filter in the standard analyzer). The new keyword “name” exists in the inverted index so it will return results.
So, depending on the type of query the search keywords were analyzed in the search time or not. This is called search time analysis.
Conclude
Above I have introduced the very basic components of Analyzers and the types of analysis that occur in Elaticsearch. For better understanding, please refer to the attached document below