Prologue
Hello everyone, back to the “What I know about MongoDB” series of articles, a series about an extremely popular NoSQL DB, MongoDB.
In the previous section, I showed you how to install mongodb shard cluster on Linux servers. By manually installing each component and configuring sharding, configuring the replicas will give you a better understanding of the system.
In this article, I will show you how to install mongodb shard cluster on K8S using helm chart. With this installation, it requires you to understand the architecture and components of MongoDB, from which it is easy to customize the available configuration parameters provided by this helmchart.

Installing mongodb on k8s using helm chart is quite simple. Because most of the installation and configuration steps are already automated. My job is just to choose specific configuration for each component I want (mongos, configserver, shard), for example:
- Do you use sharding?
- How many shards to use
- Does each shard have a replicaset configuration?
- Does ConfigServer have a Replicaset configured..
Model deployment
I will install it on a cluster of K8S installed on EC2 servers as follows:
1 2 3 4 5 6 7 | NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-172-31-33-57 Ready control-plane 21d v1.26.3 172.31.33.57 <none> Ubuntu 20.04.6 LTS 5.15.0-1033-aws containerd://1.6.19 node-1 Ready <none> 17d v1.26.3 172.31.38.164 <none> Ubuntu 20.04.6 LTS 5.15.0-1033-aws containerd://1.6.19 node-2 Ready <none> 3d17h v1.26.3 172.31.41.7 <none> Ubuntu 20.04.6 LTS 5.15.0-1033-aws containerd://1.6.19 node-3 Ready <none> 3d17h v1.26.3 172.31.45.207 <none> Ubuntu 20.04.6 LTS 5.15.0-1033-aws containerd://1.6.19 node-4 Ready <none> 3d17h v1.26.3 172.31.40.59 <none> Ubuntu 20.04.6 LTS 5.15.0-1033-aws containerd://1.6.19 |
The mongodb cluster I will install follows the same model as the previous post, which is to install 3 shardsvc (each shardsvr has 3 replicas), configsvr has 3 replicas and 2 mongos services.
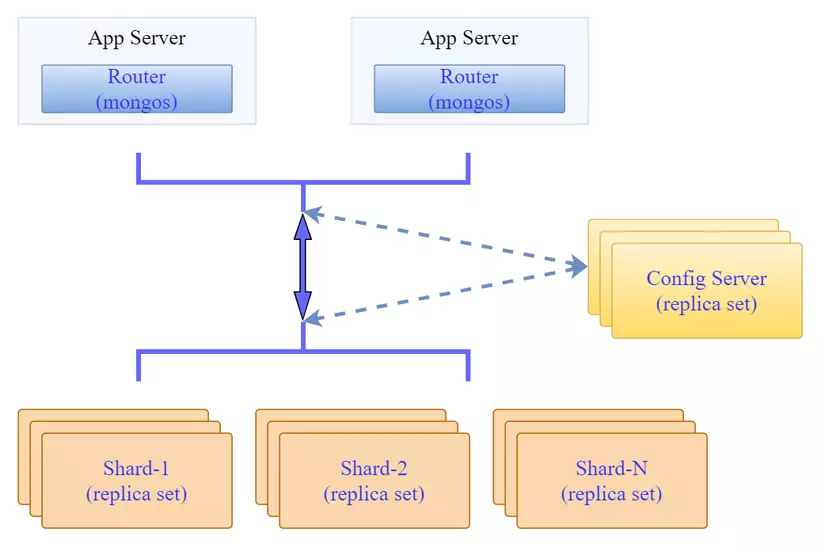
Objectives to be achieved:
- Make sure replicas of the same shardsvr will not be on the same node
- Make sure replicas of configsvr will not be on the same node
To store data for mongodb on k8s, I will use Persistent Volume (Always use AWS’s EBS Storage by creating a Storage Class for automatic PV allocation). If you use K8S Onprem, you can use NFS as a storage backend for k8s.
Deployment
A summary of the implementation steps is as follows:
- Prepare the environment: K8S, Storage Class
- Prepare helm-chart
- Customization of setting parameters
- Install helm-chart and check the results.
Prepare the Kubernetes environment
K8S has been built, including 4 worker nodes (to set the model to install 3 shards, you should have at least 3 nodes). Now I will install the storage class using AWS EBS.
To do this you need to do:
- Authorize EC2s to have read and write access to EBS
- Install EBS CSI Driver on K8S
- Install Storage Class on K8S
The above content is mainly related to AWS, I will not talk about it in depth. As a result, I have a Storage Class to generate PV automatically and the name of this Storage Class will be used for configs when installing mongo using helm chart.
1 2 3 4 | ubuntu@base-node:~$ k get storageclasses.storage.k8s.io NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE ebs-sc ebs.csi.aws.com Delete WaitForFirstConsumer false 17h |
Download mongodb helmchart
Create mongodb helmchart install and download directory:
1 2 3 4 5 6 7 8 | ubuntu@base-node:~$ mkdir mongodb-installation ubuntu@base-node:~$ cd mongodb-installation/ ubuntu@base-node:~/mongodb-installation$ helm repo add bitnami https://charts.bitnami.com/bitnami ubuntu@base-node:~/mongodb-installation$ helm search repo mongodb NAME CHART VERSION APP VERSION DESCRIPTION bitnami/mongodb 13.9.4 6.0.5 MongoDB(R) is a relational open source NoSQL da... bitnami/mongodb-sharded 6.3.3 6.0.5 MongoDB(R) is an open source NoSQL database tha... |
I will use helmchart bitnami/mongodb-sharded to install. Before the name is to download helmchart to save it on your computer to customize and use:
1 2 3 4 5 6 7 8 9 10 | ubuntu@base-node:~/mongodb-installation$ helm pull bitnami/mongodb-sharded --version=6.3.3 ubuntu@base-node:~/mongodb-installation$ ls -lrt total 52 -rw-r--r-- 1 ubuntu ubuntu 49908 Apr 21 08:15 mongodb-sharded-6.3.3.tgz ubuntu@base-node:~/mongodb-installation$ tar -xzf mongodb-sharded-6.3.3.tgz ubuntu@base-node:~/mongodb-installation$ ls -lrt total 56 -rw-r--r-- 1 ubuntu ubuntu 49908 Apr 21 08:15 mongodb-sharded-6.3.3.tgz drwxrwxr-x 4 ubuntu ubuntu 4096 Apr 21 08:15 mongodb-sharded |
At this point we will have a mongodb-sharded directory containing helmchart to install mongodb. It contains a values.yaml file that stores parameters for customization when installing this helmchart. I will copy it out to customize the parameters to suit my needs. Now the directory containing the installation file will look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 | ubuntu@base-node:~/mongodb-installation$ cp mongodb-sharded/values.yaml custom-mongo-val.yaml ubuntu@base-node:~/mongodb-installation$ tree . -L 2 . ├── custom-mongo-val.yaml ├── mongodb-sharded │ ├── Chart.lock │ ├── Chart.yaml │ ├── README.md │ ├── charts │ ├── templates │ └── values.yaml └── mongodb-sharded-6.3.3.tgz |
Customization of setting parameters
This will be the most important part when installing a software from helmchart and also requires the most experience. Because a parameter file (helm-value file) will usually be very long, sometimes up to several thousand lines. So before configuring the parameters, I need to know what I will install, and what parameters I need to customize.
My initial problem was to install mongo shard cluster with the following goals:
- There are 3 shards, each shard 3 replicas
- Configsvr has 3 replicas
- Mongos has 2 replicas
- Mongo will be used for applications in k8s so there is no need to expose it to the outside (will only need a ClusterIP service). In case you need to expose it to the outside, you can use NodePort.
- Enable Metrics so you can monitor it later on Prometheus and Grafana
Basically, the parameters of the helm-value file will allow us to customize the main objects mongos , configsvr , shardsvr and the metric section for application monitoring.
I will check and explain some of the most basic parameters to customize each of the components above.
General parameters
1 2 3 4 5 6 7 8 9 10 11 12 | global: imageRegistry: "" imagePullSecrets: [] storageClass: "" image: registry: docker.io repository: bitnami/mongodb-sharded tag: 6.0.5-debian-11-r4 digest: "" pullPolicy: IfNotPresent pullSecrets: [] |
In this part, I will need to care about image information. I often have a habit of tagging public images about the private registry, so I have to edit the image information according to the private registry in this section. Another note is that when using the private registry, you need to create a secret to use for pulling images from this private registry.
Customize the value of helm-value
Basically the default parameters of this helm chart are already very good, basically I just need to change very little. Some key parameters need to change depending on the configuration you want to deploy.
Authentication configuration, here I do not configure passwords for replicasets.
1 2 3 4 5 | auth: enabled: true rootUser: root rootPassword: "Admin_123" |
Configure the number of Shardsvr in the cluster, I set it to 3 according to the original model:
1 2 | shards: 3 |
The service configuration is by default ClusterIP and port 27017, basically I don’t have to update anything here but still mention it so that if needed I can change it to NodePort to expose it to the outside, for example:
1 2 3 4 5 6 7 8 9 | service: type: ClusterIP externalTrafficPolicy: Cluster ports: mongodb: 27017 clusterIP: "" nodePorts: mongodb: "" |
Customizing the configuration of configsvr: Then I will set parameters to create 3 replicas for configsvr and configure a persistent volume for it including storageClass information and required storage:
1 2 3 4 5 6 7 8 | configsvr: replicaCount: 3 podAntiAffinityPreset: soft persistence: enabled: true storageClass: "ebs-sc" size: 8Gi |
Customize the configuration of mongos: Simply set 2 replicas. The podAntiAffinityPreset parameter automatically generates a podAntiAffinity rule with the goal of trying to allocate this application’s Pods across different nodes:
1 2 3 4 | mongos: replicaCount: 2 podAntiAffinityPreset: soft |
Customize the configuration of shardsvr: Similar to setting 3 replicas for each shard, configure podAntiAffinityPreset: soft so that the Pods of the shardsvr will prioritize not running on the same node.
1 2 3 4 5 6 7 8 9 | shardsvr: dataNode: replicaCount: 3 podAntiAffinityPreset: soft persistence: enabled: true storageClass: "ebs-sc" size: 8Gi |
Note that we should only set the PodAntiAffinity parameter to soft, corresponding to the
preferredDuringSchedulingIgnoredDuringExecutionconfiguration. This will avoid the case that the Pod cannot find a node that meets the antiAffinity condition and is in the Pending state.
In summary, I will have a custom-mongo-val.yaml file containing the following custom parameters:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | auth: enabled: true rootUser: root rootPassword: "Admin_123" shards: 3 service: type: ClusterIP externalTrafficPolicy: Cluster ports: mongodb: 27017 clusterIP: "" nodePorts: mongodb: "" configsvr: replicaCount: 3 podAntiAffinityPreset: soft persistence: enabled: true storageClass: "ebs-sc" size: 8Gi mongos: replicaCount: 2 podAntiAffinityPreset: soft shardsvr: dataNode: replicaCount: 3 podAntiAffinityPreset: soft persistence: enabled: true storageClass: "ebs-sc" size: 8Gi |
Setting
Before installing, I can review a configuration that will actually be deployed before applying to the system. I will use the helm template command to check that with the above custom configuration, this helmchart will generate ntn resources:
1 2 | ubuntu@base-node:~/mongodb-installation$ helm template mongodb -f custom-mongo-val.yaml ./mongodb-sharded > out.yaml |
With the default affinity configuration as above, the helmchart set has created us the affinity rule as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | affinity: podAffinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchLabels: app.kubernetes.io/name: mongodb-sharded app.kubernetes.io/instance: mongodb app.kubernetes.io/component: configsvr topologyKey: kubernetes.io/hostname weight: 1 |
For each component there will be a label app.kubernetes.io/component corresponding to mongos , configsvr or shardsvr and that will be the main factor to implement the PodAntiAffinity rule.
Simply put, the system will prioritize not creating Pods of configsvr when that node already has a Pod with label app.kubernetes.io/component=configsvr running on it. And from there it helps to “allocate” Pods of the same function across different nodes.
Here we can perform the installation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | ubuntu@base-node:~/mongodb-installation$ helm install mongodb -f custom-mongo-val.yaml ./mongodb-sharded NAME: mongodb LAST DEPLOYED: Fri Apr 21 10:21:55 2023 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: CHART NAME: mongodb-sharded CHART VERSION: 6.3.3 APP VERSION: 6.0.5 ** Please be patient while the chart is being deployed ** The MongoDB&reg; Sharded cluster can be accessed via the Mongos instances in port 27017 on the following DNS name from within your cluster: mongodb-mongodb-sharded.default.svc.cluster.local To get the root password run: export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace default mongodb-mongodb-sharded -o jsonpath="{.data.mongodb-root-password}" | base64 -d) To connect to your database run the following command: kubectl run --namespace default mongodb-mongodb-sharded-client --rm --tty -i --restart='Never' --image docker.io/bitnami/mongodb-sharded:6.0.5-debian-11-r4 --command -- mongosh admin --host mongodb-mongodb-sharded --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORD To connect to your database from outside the cluster execute the following commands: kubectl port-forward --namespace default svc/mongodb-mongodb-sharded 27017:27017 & mongosh --host 127.0.0.1 --authenticationDatabase admin -p $MONGODB_ROOT_PASSWORD |
Check the result:
1 2 3 4 5 6 7 8 9 10 11 | ubuntu@base-node:~/mongodb-installation$ k get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mongodb-mongodb-sharded-configsvr-0 2/2 Running 0 2m35s 192.168.247.33 node-2 <none> <none> mongodb-mongodb-sharded-configsvr-1 2/2 Running 0 104s 192.168.139.77 node-3 <none> <none> mongodb-mongodb-sharded-configsvr-2 2/2 Running 0 66s 192.168.84.139 node-1 <none> <none> mongodb-mongodb-sharded-mongos-6778d6c6c8-jjtlt 2/2 Running 0 2m35s 192.168.247.31 node-2 <none> <none> mongodb-mongodb-sharded-mongos-6778d6c6c8-xs295 2/2 Running 0 2m35s 192.168.139.75 node-3 <none> <none> mongodb-mongodb-sharded-shard0-data-0 2/2 Running 0 2m35s 192.168.84.140 node-1 <none> <none> mongodb-mongodb-sharded-shard1-data-0 2/2 Running 0 2m35s 192.168.139.76 node-3 <none> <none> mongodb-mongodb-sharded-shard2-data-0 2/2 Running 0 2m35s 192.168.247.32 node-2 <none> <none> |
Thus we can see:
- 2 Pods of
mongosrunning on 2 nodes arenode-2andnode-3 - 3 Pods of
configsvrrunning on 3 different nodes arenode-1,node-2andnode-3 - First 3 Pods of shardsvr running on 3 different nodes
The essence here when we create 3 shards, this helmchart will create us 3 statefulset corresponding to 3 shardsvr:
1 2 3 4 5 6 7 | ubuntu@base-node:~/mongodb-installation$ k get statefulsets.apps NAME READY AGE mongodb-mongodb-sharded-configsvr 3/3 5m2s mongodb-mongodb-sharded-shard0-data 3/3 5m2s mongodb-mongodb-sharded-shard1-data 3/3 5m2s mongodb-mongodb-sharded-shard2-data 3/3 5m2s |
And according to the characteristics of the statefulset, its Pods will be generated sequentially, so the first 3 Pods of each Statefulset will be created first, when this Pod is created ok, continue to create the 2nd, 3rd Pod.
And the final result when the installation is done:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | ubuntu@base-node:~/mongodb-installation$ k get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mongodb-mongodb-sharded-configsvr-0 2/2 Running 0 7m6s 192.168.247.33 node-2 <none> <none> mongodb-mongodb-sharded-configsvr-1 2/2 Running 0 6m15s 192.168.139.77 node-3 <none> <none> mongodb-mongodb-sharded-configsvr-2 2/2 Running 0 5m37s 192.168.84.139 node-1 <none> <none> mongodb-mongodb-sharded-mongos-6778d6c6c8-jjtlt 2/2 Running 0 7m6s 192.168.247.31 node-2 <none> <none> mongodb-mongodb-sharded-mongos-6778d6c6c8-xs295 2/2 Running 0 7m6s 192.168.139.75 node-3 <none> <none> mongodb-mongodb-sharded-shard0-data-0 2/2 Running 0 7m6s 192.168.84.140 node-1 <none> <none> mongodb-mongodb-sharded-shard0-data-1 2/2 Running 0 5m15s 192.168.247.34 node-2 <none> <none> mongodb-mongodb-sharded-shard0-data-2 2/2 Running 0 4m29s 192.168.247.35 node-2 <none> <none> mongodb-mongodb-sharded-shard1-data-0 2/2 Running 0 7m6s 192.168.139.76 node-3 <none> <none> mongodb-mongodb-sharded-shard1-data-1 2/2 Running 0 5m22s 192.168.139.78 node-3 <none> <none> mongodb-mongodb-sharded-shard1-data-2 2/2 Running 0 4m31s 192.168.139.79 node-3 <none> <none> mongodb-mongodb-sharded-shard2-data-0 2/2 Running 0 7m6s 192.168.247.32 node-2 <none> <none> mongodb-mongodb-sharded-shard2-data-1 2/2 Running 0 5m32s 192.168.217.68 node-4 <none> <none> mongodb-mongodb-sharded-shard2-data-2 2/2 Running 0 4m37s 192.168.84.137 node-1 <none> <none> |
And for each Pod of the statefulset, we will have 1 PVC, PV respectively:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | ubuntu@base-node:~/mongodb-installation$ k get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE datadir-mongodb-mongodb-sharded-configsvr-0 Bound pvc-3a5ad952-47cb-4003-a454-33eb53529e6e 8Gi RWO ebs-sc 8m35s datadir-mongodb-mongodb-sharded-configsvr-1 Bound pvc-8c7d94da-cb53-40c1-bfec-8b9a539901d6 8Gi RWO ebs-sc 7m44s datadir-mongodb-mongodb-sharded-configsvr-2 Bound pvc-2d4a8f7d-7211-429c-906a-6b62db3c7a67 8Gi RWO ebs-sc 7m6s datadir-mongodb-mongodb-sharded-shard0-data-0 Bound pvc-2c580f47-aa51-4f7d-9311-b664a74f30a3 8Gi RWO ebs-sc 8m35s datadir-mongodb-mongodb-sharded-shard0-data-1 Bound pvc-c0494f6a-33d0-4ffb-8cb0-24d82f32a7fa 8Gi RWO ebs-sc 6m44s datadir-mongodb-mongodb-sharded-shard0-data-2 Bound pvc-1e7c8c76-981f-4616-bb32-3c9edc807a82 8Gi RWO ebs-sc 5m58s datadir-mongodb-mongodb-sharded-shard1-data-0 Bound pvc-9a5b91c9-f098-4232-8129-b422f2638103 8Gi RWO ebs-sc 8m35s datadir-mongodb-mongodb-sharded-shard1-data-1 Bound pvc-a55185a8-c576-4e4e-81ca-ea41bfeb04a9 8Gi RWO ebs-sc 6m51s datadir-mongodb-mongodb-sharded-shard1-data-2 Bound pvc-dc401669-803d-4598-abff-7e99cb22a0ba 8Gi RWO ebs-sc 6m datadir-mongodb-mongodb-sharded-shard2-data-0 Bound pvc-90cd4027-174e-4d60-9e43-ab242ec686f3 8Gi RWO ebs-sc 8m35s datadir-mongodb-mongodb-sharded-shard2-data-1 Bound pvc-107214c4-24d4-4232-8042-30c467574821 8Gi RWO ebs-sc 7m1s datadir-mongodb-mongodb-sharded-shard2-data-2 Bound pvc-c26f4a29-6021-4e8a-8121-1626db39372d 8Gi RWO ebs-sc 6m6s |
Check connection to DB
When the installation is complete with helmchart, it will give us instructions to connect to the db. I create a Pod with mongodb client to connect to the cluster just installed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | buntu@base-node:~/mongodb-installation$ export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace default mongodb-mongodb-sharded -o jsonpath="{.data.mongodb-root-password}" | base64 -d) ubuntu@base-node:~/mongodb-installation$ echo $MONGODB_ROOT_PASSWORD Admin_123 ubuntu@base-node:~/mongodb-installation$ kubectl run --namespace default mongodb-mongodb-sharded-client --rm --tty -i --restart='Never' --image docker.io/bitnami/mongodb-sharded:6.0.5-debian-11-r4 --command -- mongosh admin --host mongodb-mongodb-sharded --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORD If you don't see a command prompt, try pressing enter. Current Mongosh Log ID: 64426c8f1baee5fdc3a59f9e Connecting to: mongodb://<credentials>@mongodb-mongodb-sharded:27017/admin?directConnection=true&authSource=admin&appName=mongosh+1.8.0 Using MongoDB: 6.0.5 Using Mongosh: 1.8.0 For mongosh info see: https://docs.mongodb.com/mongodb-shell/ To help improve our products, anonymous usage data is collected and sent to MongoDB periodically (https://www.mongodb.com/legal/privacy-policy). You can opt-out by running the disableTelemetry() command. [direct: mongos] admin> show dbs; admin 172.00 KiB config 2.10 MiB [direct: mongos] admin> |
Creating and adding shardsvr to the cluster, as well as configuring replicas for shardsvr/configsvr is fully automated. I can check the sharding status of the cluster as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | [direct: mongos] admin> sh.status() shardingVersion { _id: 1, minCompatibleVersion: 5, currentVersion: 6, clusterId: ObjectId("64426a2d7858463604dbec98") } --- shards [ { _id: 'mongodb-mongodb-sharded-shard-0', host: 'mongodb-mongodb-sharded-shard-0/mongodb-mongodb-sharded-shard0-data-0.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017,mongodb-mongodb-sharded-shard0-data-1.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017,mongodb-mongodb-sharded-shard0-data-2.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017', state: 1, topologyTime: Timestamp({ t: 1682074269, i: 3 }) }, { _id: 'mongodb-mongodb-sharded-shard-1', host: 'mongodb-mongodb-sharded-shard-1/mongodb-mongodb-sharded-shard1-data-0.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017,mongodb-mongodb-sharded-shard1-data-1.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017,mongodb-mongodb-sharded-shard1-data-2.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017', state: 1, topologyTime: Timestamp({ t: 1682074247, i: 2 }) }, { _id: 'mongodb-mongodb-sharded-shard-2', host: 'mongodb-mongodb-sharded-shard-2/mongodb-mongodb-sharded-shard2-data-0.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017,mongodb-mongodb-sharded-shard2-data-1.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017,mongodb-mongodb-sharded-shard2-data-2.mongodb-mongodb-sharded-headless.default.svc.cluster.local:27017', state: 1, topologyTime: Timestamp({ t: 1682074248, i: 2 }) } ] --- active mongoses [ { '6.0.5': 2 } ] --- autosplit { 'Currently enabled': 'yes' } --- balancer { 'Currently enabled': 'yes', 'Failed balancer rounds in last 5 attempts': 0, 'Currently running': 'no', 'Migration Results for the last 24 hours': 'No recent migrations' } --- databases [ { database: { _id: 'config', primary: 'config', partitioned: true }, collections: { 'config.system.sessions': { shardKey: { _id: 1 }, unique: false, balancing: true, chunkMetadata: [ { shard: 'mongodb-mongodb-sharded-shard-0', nChunks: 1024 } ], chunks: [ 'too many chunks to print, use verbose if you want to force print' ], tags: [] } } } ] |
So I have installed mongodb shard cluster on K8S quite simply. To summarize, once you get used to it, you only have to edit a few parameters and set the command to set up a mongodb cluster.
Thank you for taking the time to read it. If you find the article useful, please leave an upvote and bookmark the article to support me!