Apache Spark is a framework for handling big data. The platform gained widespread popularity due to its ease of use and improved data processing speed over Hadoop. Apache Spark can distribute the workload on a group of computers in a cluster for more efficient processing of large data sets. This open source tool supports many programming languages such as: Java, Scala, Python and R. In this article, I will share how to install and configure Apache Spark on Ubuntu
Install the necessary packages for Spark
Before you want to install Apache Spark, on your computer must have installed the following environments: Java, Scala, Git. If not, open your terminal and install them all with the following command:
1 2 | sudo apt install default-jdk scala git -y |
To check whether Java and Scala environments are installed on your machine, use the following command:
1 2 | java -version; javac -version; scala -version; git --version |
Download and set up Spark for Ubuntu
To download Apache Spark for Ubuntu, you visit the website https://spark.apache.org/downloads.html , then choose to download the appropriate version for your computer.
Copy the compressed file to wherever you want to put Spark, usually the added software will be placed in the / opt directory of Ubuntu, but I can find it anywhere as long as you find it convenient for yourself. . Extract the directory with the following command:
1 2 | tar xvzf <ten_file_nen_spark>.tgz |
Configure Spark environment
In the Home folder, open hidden folders, then navigate to the .profile file, add the following line at the end of the file:
1 2 3 4 | export SPARK_HOME=<duong_dan_toi_thu_muc_ban_vua_dat_spark> export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin export PYSPARK_PYTHON=/usr/bin/python3 |
For example, I configured my .profile file as follows (oh forgot, so your computer must have python3 too):
1 2 3 4 | SPARK_HOME=/media/trannguyenhan01092000/LEARN/spark-3.0.1-bin-hadoop2.7 PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin PYSPARK_PYTHON=/usr/bin/python3 |
Start Spark Standalone
Move your terminal to the Sbin folder in your Spark directory with the command cd. Run the following command to launch Spark:
1 2 | ./start-master.sh |
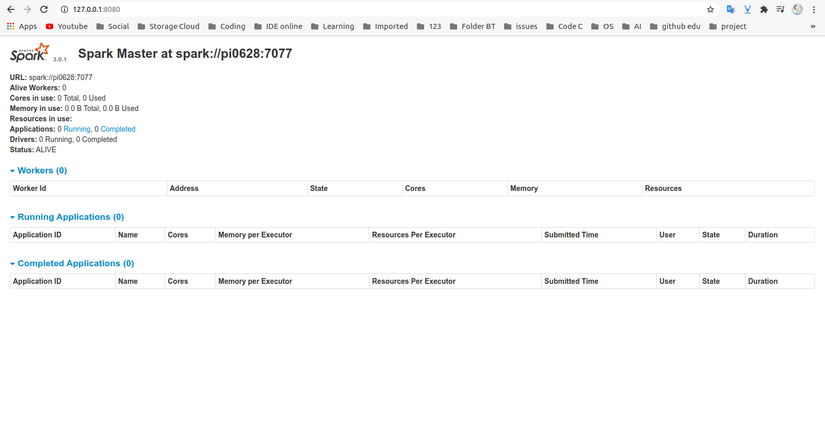
To see the Spark Web UI, open a web browser and enter the localhost IP address on port 8080:
1 2 | http://127.0.0.1:8080/ |
(Remember to turn off all other applications that share ports with Spark to avoid conflicts.)
Here is the interface after a successful launch (wait for about 10 seconds):
Reference: https://tailieu-bkhn.blogspot.com/ , https://phoenixnap.com/