We often know that in SQL indexing helps speed up queries, so everyone knows what the mechanism of indexing is? Why does it help speed up queries and what are its disadvantages? Today I would like to discuss about this topic.
1. Actual problem
You all know the web, I18n already know, right? Suppose you have 2 compiled files, en.yml and vi.yml. Each line in en.yml corresponds to vi.yml and vice versa. For example:
1 2 3 | en.yml: table: "table" |
1 2 3 | vi.yml: table: "cái bàn" |
meaning that every word translated in English must be translated in Vietnamese, so the number of lines in the file en.yml must be equal to vi.yml. However, one fine day you realize that en.yml has 1000 lines and vi.yml has only 999 lines, meaning that you missed translating a word into Vietnamese. You need to find the missing line in vi.yml to update, so how do you find the fastest line?
If you search from top to bottom between two files, you may have to go through 999 times, too many queries. However, there is a way to search up to 10 times for sure you will find that line. The way is as follows: The first time you scan on the 500th line and compare the 2 files, if the keyword match proves that the first 500 lines do not miss the value (the missing line is in the other half), and if it doesn’t match (gets deviates by 1 line), indicating that the first 500 lines contain the miss line. So only 1 test you have “double saw” the scope of search, and you continue to “double saw” up to 10 more times you will find the missing line. Why 10 times? Because 2 ^ 10 = 1024> 1000.
The indexing mechanism is also based on the same double saw method.
2. Indexing mechanism
Suppose you have a table of 1000 records containing the names of people: “Phong”, “Dung”, “Hai”, … You need to find someone named “Nam”. So the indexing mechanism will work in this case.
First, when you perform indexing for the field: name, the index will be numbered from 0 incrementally to 999 (with 1000 records), typed in alphabetical order. For example: “An” will have index = 0, “Anh” will have index = 1, “Anh” will have index = 2, … now you can understand that, in general, your records have been sorted by alphabetical order
When you run the query Select … where name = “Nam” now it will use the sawing method mentioned above, first get: name at the 500th index compared to “Nam”, although Of course, it is not equal to compare, but to compare larger or smaller, for example, record index 500 has: name is “Hoang”, then when compared, the result will be “Hoang” <“Nam” (according to alphabet) because so it is possible to identify “Nam” in the second half, which index is greater than 500. After up to 10 comparisons, you will find a record with: name is “Nam”.
The more the number of records, the more an indexing method shows its usefulness. Suppose you have 1 million records, you only need to compare 20 times is enough because 2 ^ 20 = 1024 ^ 2> 1000 ^ 2 = 1000000. While the normal query method must compare a maximum of 999999 times.
3. Indexing for multiple fields (B tree)
Indexing for multiple fields is also known as the B tree method.
Suppose you have 1 million records of a person’s name, and a person from a given province / city. You need to find a person in “Ninh Binh” province named “Nam”. How does indexing work now?
First you will need to type the index for the whole field: province and the whole field: name, now 1 million records will be grouped by province first, these provinces will be arranged in alphabetical order, for example “An Giang” has index is 0, “Ba Ria Vung Tau” has an index of 1, “Bac Giang” has an index of 2, … In the province / city group, the fields: name are indexed again. For example: “An”: 0, “Anh”: 1, “Anh”: 2, … Indexing in the index like this creates branches, so it is called a B tree.
When performing a query Select … where province = “Ninh Binh” and name = “Nam”. First filter out people in “Ninh Binh” province. The mechanism is as follows, each province retrieves the first record and compares it with “Ninh Binh” by the indexing method, Vietnam has 64 provinces so it takes only a maximum of 6 comparisons to find someone in the province ” Ninh Bình “, from that person will retrieve the entire group, then from that group again use the index method to filter out the name” Nam “again.
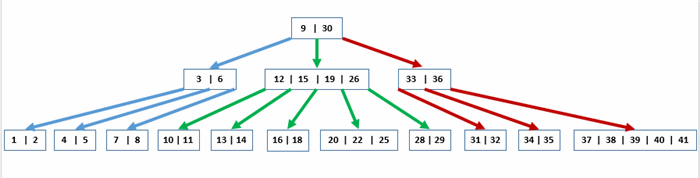
The illustration of B tree
The question is which should we index first to optimize the query,: province or: name. The answer is that schools with fewer records should hit first. In this problem, then: province has 64 provinces, and: name has hundreds of thousands of naming types, so the group by field: province first is more reasonable, because when filtering out the field: proivince, you have filtered 63/64 provinces and cities do not need to care about, equivalent to a very large number of records. And if you type in the: name field, then almost every record you have to touch at least 1 time.
When indexing in any order, when querying you must apply the same order, otherwise indexing will not work, for example, you index for: province first and then: name then use sentences For SQL “Select … where name = ‘Nam’ and province = ‘Ninh Binh'”, indexing is useless.
4. Disadvantages of indexing
Indexing helps speed up the query, but after each insert or update or delete (change the db), we need to redo indexing so the speed when doing these 3 things will decrease. For example, the initial “An” has an index of 0, “Anh” has an index of 1, “Anh” has an index of 2, when removing “An”, then this time “Anh” will have an index of 0, “Anh” will have an index of 1, the fields behind must change the same. So the disadvantage of the indexing method is that it reduces the speed of Insert, update, delete. Say is reduced but in fact when updating or deleting records we also need to query for that record so increase this and that, but reducing from 999999 comparisons to 20 comparisons is too worthy to trade off.
5. When should you not use indexing?
When there are too few records, namely less than 10, this time indexing will not work because comparing with even 10 times is still faster than comparing to check whether bigger or smaller than performing 3.4. times.