What is Index?
Index – an index (also known as a “key” in MySQL) is the data structure that storage engines use to find it quickly. Indexes are important for good performance, especially for big data. Small databases can work fine even without an index, but as the data gets bigger, performance can drop very quickly.
Basic indexing
The easiest way to understand how an index works in MySQL is to think about the table of contents in a book. To see where a particular topic is discussed in a book, you look at the table of contents and it tells you the page number (s) where that term appears.
The host engine in MySQL also uses the index in a similar way. It looks up the data structure of the index to find a value. When it finds a match, it can find the row that contains the match. Suppose you run the following query:
1 2 | mysql> SELECT first_name FROM users WHERE user_id = 5; |
There is an index on the user_id column, so MySQL will use the index to find the rows with a user_id 5. In other words, it does a lookup of the values in the index and returns any rows containing the price. treatment is indicated.
The index can contain values from one or more columns in the table, so if you index more than one column, the column order is important, as MySQL can only effectively search on the outermost prefix. left of the index.
Types of indexes
There are many types of indexes that are designed for different purposes. Indexes are done in the storage layer, not the server class. Hence, they are not standardized: indexing works differently within each tool, and not all tools support all types of indexes. Even when multiple tools support the same type of index, they can implement it differently.
B-Tree index
The B-Tree index uses a B-Tree data structure to store data, which is the type of index commonly used in most MySQL data storage engines. The general idea of B-Tree is that all values are stored in order and each leaf page has the same distance from the root.
An index is built on top of the B-Tree structure:
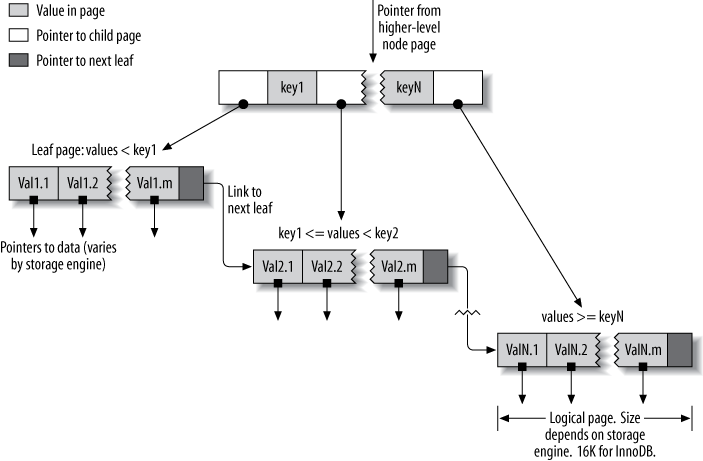
The B-Tree index speeds up data access because the archiving engine doesn’t have to scan the entire table to find the desired data. Instead, it starts at the root node (not shown in the image above). The positions in the root node hold the pointers to the child nodes and the storage engine obeys these pointers. It finds correct pointers by looking at values in node pages, specifying upper and lower bounds of values in child nodes. Finally, the storage engine determines that the desired value does not exist or the page leaves successfully.
Since B-Tree stores indexed columns in order, they are useful for finding data within a range. For example, in descending order of an index’s data tree on a text field alphabetically, we can efficiently search for “people whose names start with I through K”.
Suppose we have the following table:
1 2 3 4 5 6 7 8 | CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f')not null, key(last_name, first_name, dob) ); |
The index will contain values from the columns last_name, first_name, and dob for every row in the table. The following figure illustrates how an index sorts the data it stores. 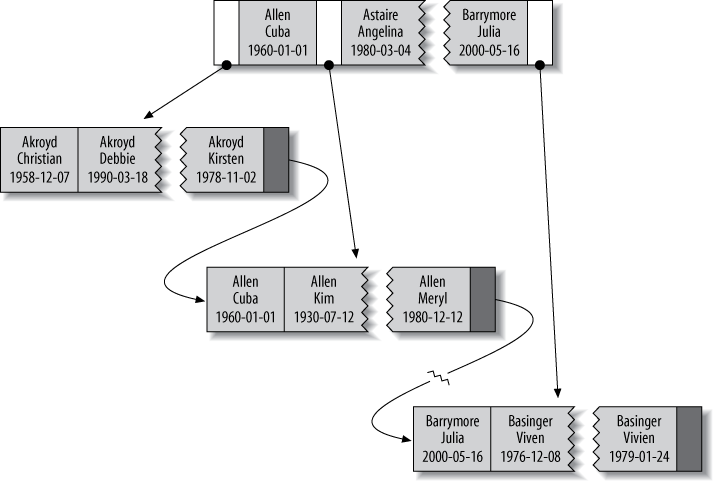
Notice that the index sorts the values in the order of the columns declared in the index in the CREATE TABLE statement. Look at the last two entries: there are two people with the same name but different birth dates and the last name sorted by date of birth.
Other types of queries can use the B-Tree index
1. Search for a full match
Search for the full key value in the values specified for all columns in the index. For example, the above index can help us find a person named Cuba Allen, born on 1960-01-01.
2. Search matches the leftmost prefix
This index can help you find all people with the last name Allen. This uses only the first column in the index.
3. Search for a match with the column prefix
We can search on the first part of the column’s value. This index can help you find all people whose last names begin with J. This only uses the first column in the index.
4. Search for matches of a range of values
This index can help you find people whose last name is between Allen and Barrymore. This also uses only the first column.
5. Search for an exact match of one part and a range of values from another
This index can help you find people with the last name Allen and names that start with a K (Kim, Karl, etc.). This is an exact match on last_name and a range query on first_name.
6. Indexing queries only
B-Tree indexes can often support indexed queries, which are index-only queries, not row archives.
Since tree nodes are sorted, they can be used for both lookup queries (find values) and ORDER BY (searches for values in sorted order)
Some limitations of the B-Tree index:
- They are not useful if the lookup does not start from the leftmost of the indexed columns.
- You cannot omit columns in the index.
- The storage engine cannot optimize access with any column to the right of the first range condition. For example if your query is
WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23'index access will use only the first two columns in the index, because LIKE is a range condition.
Now we can see why column order is so important: these restrictions are all related to column order. For optimal performance, you may need to create indexes with the same columns in different orders to satisfy your queries.
Hash indexes
Hash indexes are built on hash tables and are only useful for exact lookups that use every column in the index. For each row, the storage engine calculates the hash of the indexed columns, which is a small value that will likely be different for rows with different key values. It stores the hash codes in the index and stores a pointer to each row in the hash table.
In MySQL, only the Memory storage engine supports explicit hash indexes. They are the default index type for the Memory table, although the Memory table may also have a B-Tree index.
As an example of a hash index, we have the following table:
1 2 3 4 5 6 | CREATE TABLE testhash ( fname VARCHAR(50) NOT NULL, lname VARCHAR(50) NOT NULL, KEY USING HASH(fname) ) ENGINE=MEMORY; |
Contains data as follows:
| fname | lname |
|---|---|
| Arjen | Lentz |
| Baron | Schwartz |
| Peter | Zaitsev |
| Vadim | Tkachenko |
Now, suppose the index uses a virtual hash function called f (), which returns the following values (these are just examples, not real values):
1 2 3 4 5 | f('Arjen')= 2323 f('Baron')= 7437 f('Peter')= 8784 f('Vadim')= 2458 |
The data structure of the index will look like this, note that the slot value is sorted but the pointer value is not:
| Slot | Value |
|---|---|
| 2323 | Pointer to row 1 |
| 2458 | Pointer to row 4 |
| 7437 | Pointer to row 2 |
| 8784 | Pointer to row 3 |
Search with command mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQL will calculate the hash of ‘Peter’ and use it to look up the pointer in the index. Since f (‘Peter’) = 8784, MySQL will look up the index for 8784 and find a pointer to row 3. The final step is to compare the value in row 3 with ‘Peter’, to make sure it’s correct.
Limitations of hash index:
- Since the index only contains the hash code and the row pointer instead of storing the values, MySQL cannot use the values in the index to avoid reading the rows.
- MySQL cannot use the hash index for sorting because they do not store the rows in the sorted order.
- Hash indexes do not support partial key searches, as they compute hashes from the entire indexed value.
- The hash index only supports comparison using the =, IN (), and <=> operators (note that <> and <=> are not the same operator).
- Accessing data in a hash index is very quick, unless there are multiple values with the same hash function.
- Some index maintenance operations can be slow if there are many conflicts (there are multiple values with the same hash).
These limitations make index hashes useful only in special cases. However, when tailored to the needs of the application, they can significantly improve performance.
Spatial index (R-Tree)
Unlike a B-Tree index, a spatial index does not require a WHERE clause to operate on the left-most prefix of the index. They index data in all dimensions at once. Hence, lookups can use any combination of dimensions efficiently. However, you must use MySQL’s GIS functions, such as MBRCONTAINS () to do this, and MySQL’s GIS support is not well supported so most people don’t use it. The optimal solution is to use GIS in open source RDBMS is PostGIS in PostgreSQL.
Full-text indexes
FULLTEXT is a special type of index that finds keywords in text instead of comparing values directly with values in the index. Full-text search is completely different from other types of search, it is more flexible than being able to search with ambiguous keywords, root word, plural, or Boolean value. It is more like a search engine than simply looking for matching value with the WHERE clause. Having a full-text index on a column does not remove the value of a B-Tree index on the same column.
Benefits of indexing
The index not only allows the server to quickly navigate to the desired location in a table, but also has other benefits based on the properties of the data structure used to create them.
The B-Tree index, the most common type you’ll use, works by storing data in a sorted order, and MySQL can exploit that for queries with statements like ORDER BY and GROUP BY. Because the data is pre-sorted, the B-Tree index also stores related values closely. Finally, the index actually stores a copy of the values, so some queries can be satisfied only from the index. The three main benefits derive from these properties are:
- Indexes reduce the amount of data a server has to examine.
- Indexes help the server avoid sorting and temporary tables.
- The indexes turn random I / O into sequential I / O.