Notes: This article is a translation from another blog, I will remove the irrelevant advertisement so that you can focus on the specific knowledge shared in this article. If you want to read more deeply and carefully then you should read the original. Thanks ^^!
PS: This article is quite long, I also get discouraged. But the knowledge about device management is very good.
Overview
Programming languages like C have low-level memory management functions like malloc() and free() . These primitive functions were developed and used by the developer to allocate memory and free up memory for the operating system.
At the same time, JavaScript will allocate memory when objects or strings, etc. are created and automatically release objects when they are no longer in use, a process called garbage collection.
The nature of hearing-free memory that seems to have “automatically” naturally appears to be a mistake. It causes JavaScript developers (and some other high-level languages) to ignore or intentionally ignore it. This is a huge mistake.
Even when working with high-level languages, developers should have an understanding of memory management (or at least grasp the basics). Sometimes there are problems with memory management (bugs, or garbage collection performance is limited) and then the developers need to understand its mechanism to be able to handle the problem. most optimal. (or to find a workaround, with minimal risky and bad code).
Memory life cycle (cycle of the device)
No matter which programming language you use, the Memory life cycle is always the same:
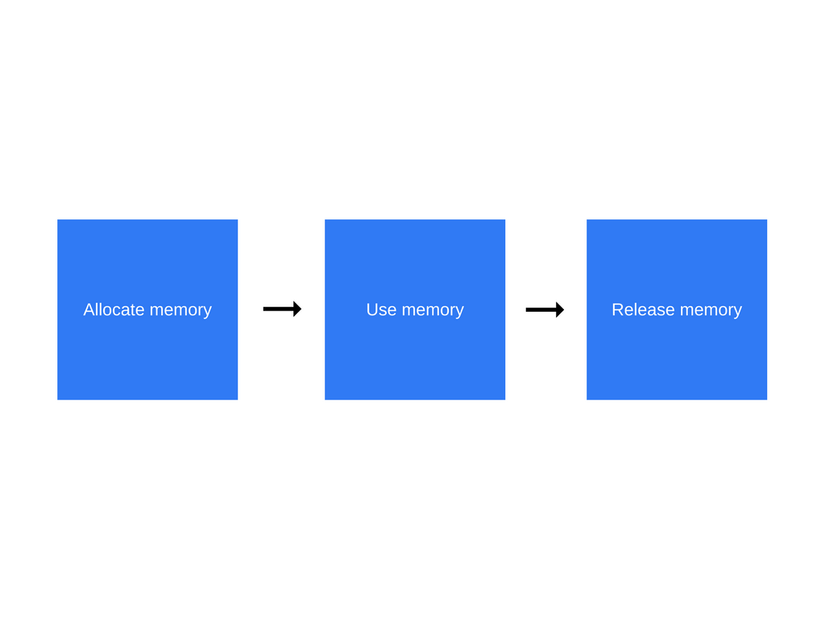
Here is an overview of what happens at each step of the cycle:
Allocate memory : Memory will be allocated by the operating system running your program. In low-level languages (e.g. C), this process should be handled by the developer himself. However, with highly enabled languages, this process is automatically handled by the engine.
Use memory : this is when your program actually uses the memory that has been allocated before. Read and Write operations will take place as soon as you create a variable, allocating memory for your variable in the code.
Release memory : This is when you release all memory that you no longer use. They will now be released and ready to be used again. For low-level languages, the Release memory process and the Allocate memory process are quite clear and the programmers will have to handle this problem themselves with their code.
For a quick look at the concepts of call stacks and memory heaps , you can read our first article on this topic .
What is memory?
Before going directly into details, we should see an overview of the concept of memory overview and how it works.
At the hardware level, computer memory consists of a large number of flip-flops . Each flip-flop contains several transistors and is capable of storing a bit. Each flip-flop will be addressed with a unique identifier, so we can read and overwrite them. So, conceptually, we can simply think like this: “our entire computer memory is just a giant bit array that we can read and write”.
Because we are human, we do not have the ability to read all thoughts or mathematical formulas from string bits, we arrange them into larger groups, put them together and can be used to denote numbers. 8 bits will be 1 byte. Speaking of Bytes, there are several types (sometimes 16 bits, sometimes 32 bits).
A lot of things are stored in memory:
- All variables and data are used in the software.
- All code, including the operating system.
The compiler and the operating system work together to handle most of the memory management for you, but we recommend that you know what is going on there.
When you compile your code, the compiler can check primitive data types and calculate in advance how much memory they will need. The required quantity is then allocated and placed in the stack space . The space in which these variables are allocated is called the stack space because when functions are called, their memory is added above the available memory. When they terminate, they are deleted in LIFO order (last-in, last-out). For example, consider the following cases:
1 2 3 4 | int n; // 4 bytes int x[4]; // array có 4 elements, mỗi elements có 4 bytes double m; // 8 bytes |
The compiler should see something like this: 4 + 4 × 4 + 8 = 28 bytes.
That’s the way it works with current sizes for integers and doubles. About 20 years ago, integers were usually 2 bytes and doubles was 4 bytes. Your code should never depend on the size of the basic data types at this time.
The compiler will insert code to interact with the operating system, requiring the number of bytes needed on the stack to store your variables.
In the above example, the compiler will know the exact memory address of each variable. In fact, whenever we write into variable n, it will be roughly translated into “memory address 4127963”.
Note that if we try to access x[4] now, we will have to access the data type like variable m. That’s because we’re accessing an internal element that doesn’t exist in the array. (Its 4 bytes are appended after the last element of this array x[3] . – Note that this array in the example says there are only 4 elements. x[4] can now be read and overwrite some bits of variable m of type double). It certainly does not bring the optimization of the memory allocation to our software.
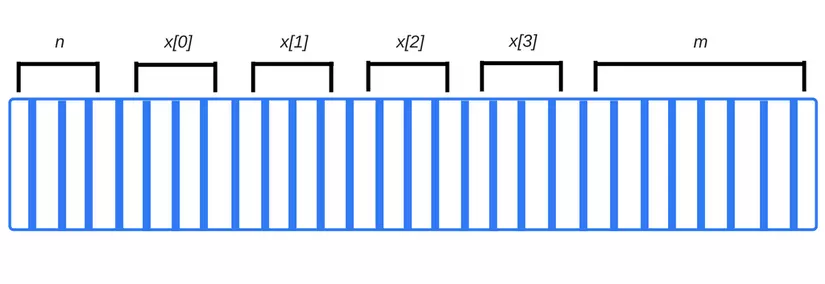
When functions call other functions, each function has its own segment in the stack when it is called. It keeps all its local variables there, but also contains a buffer that remembers its execution location. When that function is finished, its memory block is once again released and is available for other purposes.
Automatic allocation
Unfortunately, things are not entirely easy when we have no idea how much memory time it takes to compile for how much memory a variable will need. Suppose we want to do something like this:
1 2 3 4 | int n = readInput(); // reads input from the user ... // create an array with "n" elements |
Here, at compile time, the compiler does not know how much memory the array will need because it is determined by a dynamic value provided by the user.
Therefore we cannot know but allocate memory for the variable in the stack. Instead, our program needs to make explicit requests to the operating system that can allocate us the right amount of space at run-time. This memory will be allocated from the heap . The differences between static and dynamic memory allocation are summarized in the following table:

In order to fully understand how the dynamic allocation process works. We need to spend a lot of time to understand pointers (pointers), this problem can be a little deviated from the topic mentioned in this article. (This paragraph the author said if you want to dig deeper about pointers, just comment on the post of the author for further explanation)
Allocate memory in JavaScript
Now we will explain the first step in JavaScript “Device allocation”. JavaScript has reduced the responsibility for developers in this area of memory allocation. It works automatically as soon as you declare a variable.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | var n = 374; // cấp phát vùng nhớ cho 1 number var s = 'sessionstack'; // cấp phát vùng nhớ cho 1 string var o = { a: 1, b: null }; // cấp phát vùng nhớ cho một object và cho từng property của nó var a = [1, null, 'str']; // (giống như object) cấp phát vùng nhớ cho một // array và từng element của nó function f(a) { return a + 3; } // cấp phát vùng nhớ cho một function (function này được cấp phát như một object nhưng có thể được gọi tới) // function expressions cũng được cấp phát như một object someElement.addEventListener('click', function() { someElement.style.backgroundColor = 'blue'; }, false); |
See more Function Expressions here
Some instances of object initialization by calling an initialization function will also be allocated as objects
1 2 3 | var d = new Date(); // cấp phát vùng nhớ cho Date object var e = document.createElement('div'); // cấp phát cho một DOM element |
Methods can allocate new values or a new object. For example:
1 2 3 4 5 6 7 8 9 10 11 12 | var s1 = 'sessionstack'; var s2 = s1.substr(0, 3); // s2 là một string mới // Bởi vì các string là những giá trị bất biến, // JavaScript lúc này sẽ không cấp phát vùng nhớ cho nó, // nhưng vẫn sẽ lưu cái range [0, 3] lại. var a1 = ['str1', 'str2']; var a2 = ['str3', 'str4']; var a3 = a1.concat(a2); // một array mới với 4 elements được ghép lại // từ các elements của a1 và a2 |
Using memory in JavaScript
Using memory in javaScript is simply reading and overwriting it.
This is done by reading and writing the values of a certain value or an object’s property or even putting an argument into a function.
Freeing memory when not in use.
Most of the problems or errors in memory processing come from this step.
The most difficult task here is how to determine which allocated memory areas are no longer being used. Often developers need to determine where in their code they are no longer needed and to free up memory there immediately.
For high-level languages, it will have an additional process called garbage collector (this is provided by the engine). This process will help track the entire memory heap and when it will detect where it is no longer used, it will be removed automatically.  ).
).
Of course there is nothing absolute, the determination of which memory is needed or not can not be based on an algorithm that solves it.
Most of these garbage collectors work by collecting memory areas that are no longer accessible, such as pointer variables that are outside the current scope. However, such collection is also relatively dark and cannot be swept away. Because practically any device has pointer variables within its scope that point to it but never be accessed again.
Garbage collection
As a matter of fact, determining which memory is still in use or which device is not being used is very difficult and relative. So this Garbage Collection solution is also very limited to this problem so in this section we will explain the concepts necessary to understand the main algorithms of garbage collection and their limitations.
Memory references
GC algorithms rely primarily on its references. In the context of device management, an object can refer to another object if the first object can access the following object (either hidden or explicit). For example, an object can refer to its own prototype ( implicit reference ), and the values of each of its properties. ( explicit reference – roughly translated as a public query).
In this context, an object can be expanded to be a larger object than it originally was, and it may contain function scopes (or even global lexical scope).
Lexical scopes are variables that are initialized in nested functions: the inner function may contain the scope of the wrapper function even if the wrapper function has been returned (See more about closure and scopes ).
Reference-counting garbage collection
This garbage collection algorithm is super simple. An object is considered junk and can be erased when none of it is referenced.
See an example below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | var o1 = { o2: { x: 1 } }; // chúng ta tạo ra 2 objects. // 'o1' tham chiếu tới 'o2' tại biến 'x' của 'o2'. // lúc này thì không có cái nào là rác cả var o3 = o1; // 'o3' được khởi tại và có giá trị là 'o1' // lúc này 'o3' nó cũng trỏ tới cái object mà 'o1' trỏ tới (chính là o2). o1 = 1; // khi mình gán trực tiếp 'o1' = 1 rồi thì lúc này 'o1' sẽ chỉ có tham chiếu duy nhất trỏ tới nó đó là 'o3' (o1=1 thì khi đó o1 không còn = o2 nữa) var o4 = o3.o2; // 'o4' được khởi tạo và nó bằng 'o3.o2' nghĩa là lúc này nó có trỏ tới 'o2' và có một property là 'x = 1'. // 'o4' lúc này sẽ có 2 reference: // 1 là là biến x trong 'o2'. // 2 là chính giá trị của nó o3 = '374'; // Nếu gán trực tiếp 'o3' với giá trị '374' thì lúc này 'o1' sẽ không có đối tượng nào tham chiếu đến nó nữa cả // Lúc này nó chính là rác. // Nhưng mà lúc này gía trị bàn đầu của nó là 'o2' vẫn tồn tại // và được tham chiếu bởi 'o4', cho nên vùng nhớ chứa nó vẫn không được giải phóng o4 = null; // 'o4' trước đó tham chiếu tới 'o2' nhưng mà giờ được gán giá trí khác // vậy lúc này 'o1' chính xác là không còn ai tham chiếu tới nữa. // Nó sẽ được thu gom. |
(How confused (_ _!))
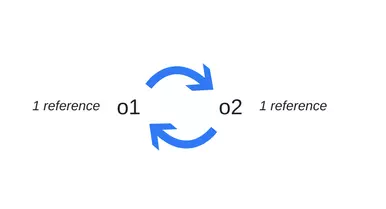
The problem comes from cycles.
There is a restriction that comes from the loop. In the following example we will see two objects referencing each other and creating a loop. Slack is out of scope after the function is called and then they are no longer working and their memory can be freed. But for the current counting algorithm to clean up the garbage, it will still find that if there is at least one reference object, it will still not be released. This means that when they keep referring to each other, they make a loop. Then both cannot be released.
1 2 3 4 5 6 7 8 9 | function f() { var o1 = {}; var o2 = {}; o1.p = o2; // o1 references o2 o2.p = o1; // o2 references o1. This creates a cycle. } f(); |
Mark-and-sweep algorithm
To determine whether an object is still usable, this algorithm determines whether the object is accessible.
This algorithm has 3 steps:
- Roots: Roots is basically a global variable that is referenced in the code. For example, in JavaScript we have an object
windowis a global variable that is considered to be root. In Nodejs the same objects are called “global”. A complete list of roots will be built by garbage collector. - Next the algorithm will start to check all the roots in the list and its children and then mark them as active (ie not garbage). And vice versa if the root does not point to it is considered as garbage.
- And finally the garbage collector will free up all the memory of the unaffected elements and release their memory back to the operating system can use.
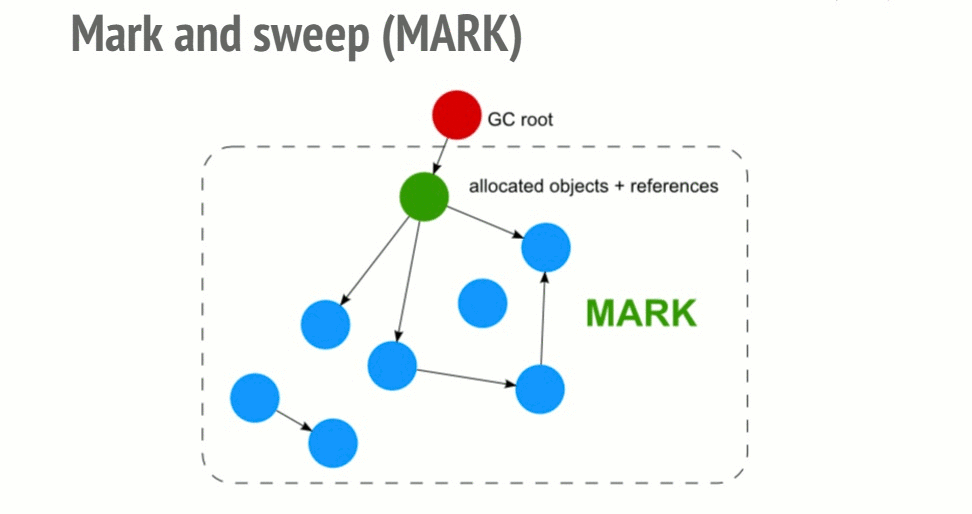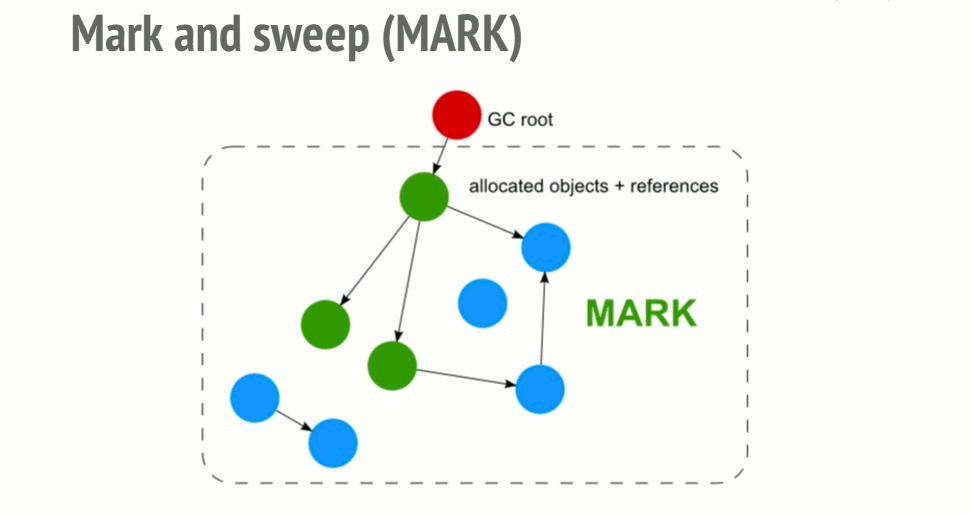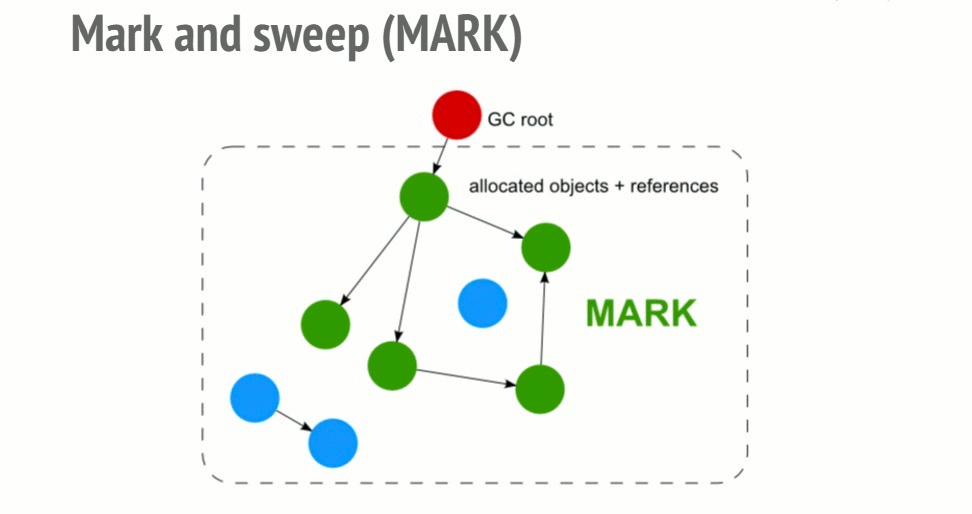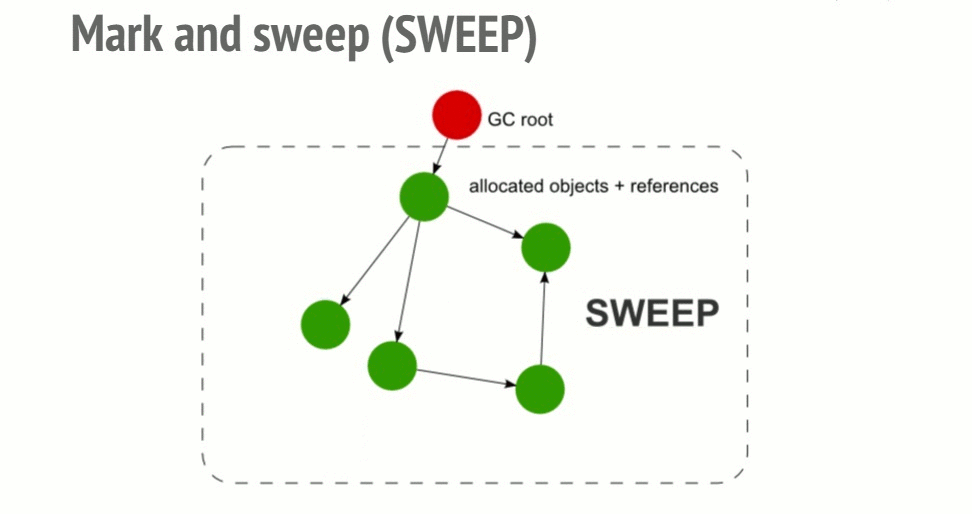
This algorithm is better than the previous one because an object has no references that make the object inaccessible. And obviously this theory does not apply to the case of cycles. Since 2012, all modern browsers have had a garbage collector and sweep sweep collector. All improvements in JavaScript garbage collection such as (generational / incremental / concurrent / parallel garbage collection) are directed to the development of this algorithm. But it does not really improve the GC’s own problem or can achieve its goal of determining whether an object is accessible.
See this article to learn more about garbage collection as well as mark-and-sweep algorithms and how it has been optimized.
Cycles are no longer a problem now
In the first example above, after the function was called to return a value, the two objects were no longer referenced by the global variable, they would now be found by the GC.
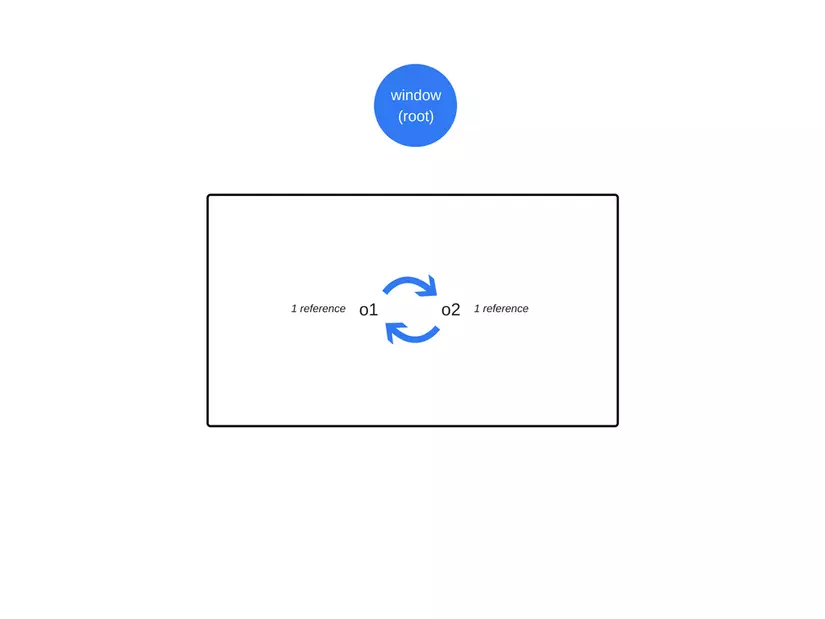
Although they have mutual reference, they are still considered garbage because they are not referenced by root. So now they will be collected.
The non-intuitive Garbage Collectors
Although the Garbage Collectors are very convenient, there are also some limitations when some problems may not integrate with itself. One of them is non-determinism . In other words, GCs are an unpredictable type. You really don’t know when the collection is done. In some cases our program may use more memory than it requires. In some cases, the problem of short-pause is also quite a concern for some sensitive applications.
Although non-determinism means that we are not sure when the collection will be executed, but in most CGs processes they use the same model to perform cleanup during the add-on process. device area. If no allocation operations are made, most CGs will not work either. Consider the following scenario:
- Allocate a large size memory.
- Most elements (or all of them) are hidden inaccessible (assuming we disable a pointer to a cache we no longer use).
- No attribution operations are performed anymore.
In this case, most CGs will not run. In other words, although in the cases above GCs have identified objects that have not been queried and they are ready to clean up, but the collector does not make the execution request, the GC will not run. These are not very serious leaks, but in fact they still lead to more memory usage than is intended.
So what is a memory leak?
Memory leak roughly means the memory areas that we have used before but are no longer used. But they haven’t been freed up for the operating system yet or for areas where the available memory is available.

Different programming languages will use different ways to handle memory management. However, determining whether a device has been used is not really an undecidable problem . In other words, only the developer can determine which memory area he needs and which memory is not. There are also several programming languages that provide features that help developers do this. But others require developers to identify and manage this problem themselves. Wikipedia has a lot of good articles for manual or auto memory management issues.
4 types of memory leaks often encountered in javaScript
1: Global variables
JavaScript treats undeclared variables in an interesting way: When a variable is undeclared but pointed to, immediately an attribute will be created in the global object window . It should look like this:
1 2 3 4 | function foo(arg) { bar = "some text"; } |
It will be equivalent to
1 2 3 4 | function foo(arg) { window.bar = "some text"; } |
Saying this, the purpose of the bar variable is to refer to a string some test inside the foo function. But when you don’t use var to declare it, a backup global variable will be created in the object window . With the above short code is not a big deal. But imagine that with a bunch of code all creating global redundant variables like this, it’s definitely a big deal for our memory.
You can also accidentally create a global variable using this :
1 2 3 4 5 6 7 | function foo() { this.var1 = "potential accidental global"; } // Foo gọi chính nó, this trỏ tới global object (window) // thay vì là undefined. foo(); |
You can avoid all of this by adding ‘use strict’ at the top of your JavaScript file, at which point it will switch to a much more strict JavaScript parsing mode, which will prevent creating variables. global surprise.
Accidentally creating global variables is certainly not a big deal, but it is important that if you regularly create such variables, then in theory GC will not be able to collect and clean up. all these variables are removed. So we need to pay special attention to global variables when creating to store a large number of bits. Only use global variables when you’re forced to do so, be sure to assign a null value or update its value after you’re done.
2: Timers or callbacks are forgotten
For example, with setInterval an API is provided with the browser and is commonly used in JavaScript.
Libraries that provide observers or other tools that allow callback functions will usually have to make sure that once its instances are unreachable (all inaccessible) all references (sub) pointers to) the callbacks that it allows are also unreachable. The following cases also occur:
1 2 3 4 5 6 7 8 | var serverData = loadData(); setInterval(function() { var renderer = document.getElementById('renderer'); if(renderer) { renderer.innerHTML = JSON.stringify(serverData); } }, 5000); //This will be executed every ~5 seconds. |
The code above shows the consequences of using timers whose reference nodes or data are no longer needed.
This explanation is a bit complicated and cumbersome so I did not translate. I will explain it from a simple personal point of view like this. The renderer variable in some cases if it’s equal to false then it’s clear that the function callback inside setInterval will not make sense anymore. But it still runs continuously every 5 seconds (property of the setInterval function). Because it is still active, the process and its dependencies will not be cleaned up. So now serverData and loadData() are redundant which cannot be collected.
When using observers, you need to have an explicit command to remove them when you’re done (either the observer is no longer needed or the object is inaccessible).
Fortunately, most modern browsers will do this for you: the browser will automatically collect observers once an observer becomes inaccessible even if you forget to delete the listener. Some older browsers did not do this (IE6).
However, the following example will show you a few specific cases we need to note to remove observers when it becomes useless:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | var element = document.getElementById('launch-button'); var counter = 0; function onClick(event) { counter++; element.innerHtml = 'text ' + counter; } element.addEventListener('click', onClick); // Do stuff element.removeEventListener('click', onClick); // một listeners element.parentNode.removeChild(element); // Lúc này element đã nằm ngoài scope, // cả element và onClick sẽ được thu lượm ngay cả trên các browsers cũ // chúng không có cơ chế handle cycels tốt lắm |
But with modern browsers you don’t even need to removeEventListener before turning the element’s node into unreachable. Because it will always do this for you. If you use JQuery (some libraries, frameworks also have support) the listeners will also be removed for you before the node is no longer referenced. The JQuery library helps you ensure there is no memory leak even when the application is running under older browser versions.
3: Closures
An important aspect in JavaScript is Closures: An inner functions can acccess to variables of an outer (enclosing) function. Because of the JavaScript implementations in the runtime, the following memory leaks will also occur:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | var theThing = null; var replaceThing = function () { var originalThing = theThing; var unused = function () { if (originalThing) // a reference to 'originalThing' console.log("hi"); }; theThing = { longStr: new Array(1000000).join('*'), someMethod: function () { console.log("message"); } }; }; setInterval(replaceThing, 1000); |
When replaceThing function is called. theThing will be updated into an object containing a very large array and a closure ( someMethod ). However, originalThing is referenced by another closure, the unused variable. It should be noted that the scope of closures is created for closures in the same parent scope so that the scope is shared.
In this case, the Scrope created for the someMethod closure function will be referenced by the unused function (the two closures have the same scope), and unused refers to the originalThing . Although unused is initialized but not used, someMethod is used by theThing , theThing variable is initialized outside the scope of the replaceThing function (which is a global variable). Once someMethod shares the scope with unused , this unused is a reference by originalThing so the unused variable at this time cannot be collected (because it is still referenced by the global scope now).
In the previous example, someMethod ‘s scope was shared with unused while unused to originalThing , in fact someMethod can be used via theThing outside of replaceThing ‘s scope despite the fact that unused is not called ( its existence is useless). In fact the useless reference originalThing north forces it to still work when someMathod shares its closure scope with the unused variable.
All of this can lead to a significant memory leak. You can see a spike in memory usage when the code above is run over and over again. Its size will not be reduced when GC is run. A chain link between closures will be created (its root will be theThing variable for the above case), and each scope of each closures will have to load an indirect reference to a large array.
This issue was found by the Meteor team and they have a great article describing it in great detail.
4: Out of DOM references
There are some situations when developers store DOM nodes within data structures. Suppose you want to update contents for some rows in a table quickly. If you store a reference for each DOM row in a dictionary or an array, then there will be two references pointing to the same DOM element: one in the DOM tree and one in the dictionary. If you want to remove these rows, you should also note that the references must also be removed.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | var elements = { button: document.getElementById('button'), image: document.getElementById('image') }; function doStuff() { elements.image.src = 'http://example.com/image_name.png'; } function removeImage() { // image là một biến thuộc về object element document.body.removeChild(document.getElementById('image')); // Ở đây, chúng ta vẫn còn một reference tới #button trong object elements global. // nói cách khác thì cái element button này vẫn tồn tại trong bộ nhớ và không thể đc collect bởi GC } |
There is another consideration that needs to be taken into account when it begins to refer to the inner branches of a DOM tree. If you create a reference to a table cell (<td> tag) and then want to delete the table but keep the reference to a specific cell, then a memory leak may occur, though Not very big. You might think GC will clean up everything except that particular cell, but no, it’s not like that. Once the cell is the child node of the table, children always keep a reference to its parents, at which point the only presumably reference will hold the entire table in memory.