Introduce
One of the things that people who work with Data need to do, especially Data Engineering, need to be concerned about extracting data from many sources, pouring it into one place (Data Warehouse, Data Lake, …), to store and analyze data. We can call it Data Pipeline . To understand it better, first let’s talk about ETL and ELT.
What is ETL already?
Extract
- Data mining is the first stage of the ETL/ELT process, in which data is collected from a variety of source systems.
- The data can be completely raw, such as sensor data from IoT devices, or it can be unstructured data from medical documents, scanned data, or corporate emails, it can be real data. Transmission data comes from a social media network or near real-time stock market buy/sell transactions, or may come from existing corporate databases and data warehouses.
- There are many techniques for data extraction, depending on the type of data source and the intended use of the data
- OCR is used to extract scanned text from an image document so it can be read on a computer
- ADC can digitize analog audio signals and recordings
- CCD captures and digitizes images
- Cookies: log and track user behavior on the internet
- Web scraping
- APIs
- SQL language for querying relational databases and NoSQL for querying documents, key-values, graphs
- Medical imaging devices and biometric sensors for data collection
- …
Transform
- Where rules and processes are applied to data in preparation for loading the data into the target system.
- This is usually done in an intermediate working environment called the ” Staging area “.
- Here the data is cleaned to ensure reliability and compatibility with the target system
- Some data transformation techniques:
- Cleaning
- Filtering
- Joining
- Normalizing
- Data Structuring
- Feature Engineering
- Anonymizing and Encrypting
- Sorting
- Aggregating
In addition, for the Transformation block, we will have 2 more keywords to pay attention to:
- Schema-on-write is the usual approach used in ETL pipelines, faster query execution, because the data is already loaded in a specific format and easy to locate column indexes or compress data. Whether. However, it takes longer to load the data into the database.
- Schema-on-read is related to modern ELT approach, initial data loading is very fast , because the data does not have to conform to any format to read or parse or serialize, as it just is a copy/move of a .
Load
- This is the loading stage all about writing the Trasformed data to the target system. The system can be as simple as a comma-delimited file (like a CSV file), it can also be a database, or it can be part of a complex system like Data Warehouse, Data Lake, etc.
- Some data loading techniques
- Full loading: the technique of loading all data from the source into the system only once, suitable for large data or data that does not change often. This technique takes a lot of time and system resources
- Incremental loading: technique of loading data only from newly added records to the data source, this technique saves time and system resources but requires a distinguishing mark mechanism
- Scheduled loading: the technique of loading data according to a predetermined schedule. This technique is suitable for applications with slow data processing times or when the data source does not change frequently
- On-demand loading: the technique of loading data upon request from a user or application. This technique saves system resources but requires a fast response mechanism to meet the load requirements of the data.
- Batch and stream: while Batch is used to load data before processing, Stream loads data in stream or block form during processing. Batch is suitable for mass data processing applications, while stream is suitable for continuous data processing applications.
- Push and pull: Push and pull are two techniques for bringing data from the source into the system. Push is a technique to push data from the source into the system, while pull is a technique to get data from the source into the system. Push is suitable for applications with rapidly changing data, while pull is suitable for applications with slow changing data.
- Prallel and serial: Parallel and serial are two techniques for processing data on multiple streams. Parallel is a technique for processing data on multiple parallel threads, while serial is a technique for processing data on a single thread. Parallel is suitable for applications that process large or distributed data, while serial is suitable for applications that handle simple data.
ETL and ELT?
First of all, ETL and ELT are both data processing techniques used to extract, transform and load data from many different sources into the system Let’s analyze the difference between these two data processing techniques. 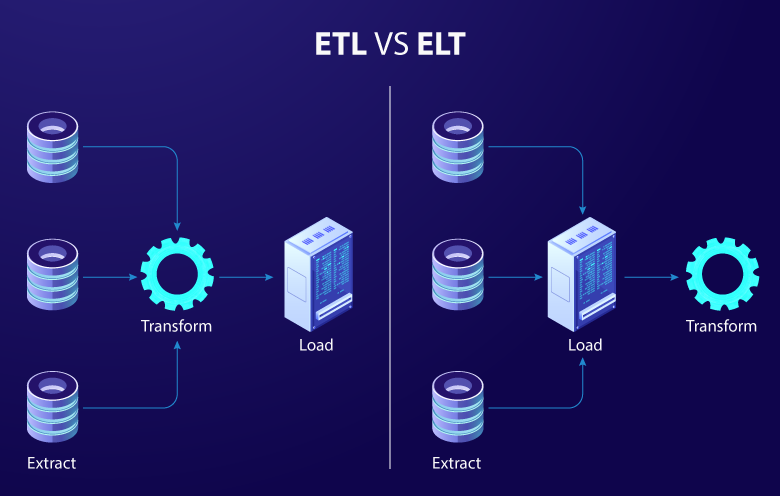
Order of data transformation steps
- In ETL, data is extracted from the source, then transformed to fit the structure and format of the target system, before being loaded into the target system. Data transformation steps typically include filtering, sorting, concatenation, data type conversion, normalization, and grouping. After the data has been transformed, it is loaded into the target system.
- In ELT, data is loaded directly into the target system, then the transformation is performed in the target environment . Data transformation tools and techniques are often built-in to the target system, allowing users to perform data transformations flexibly and efficiently.
The decoupling between data loading and data transformation in ELT allows users to maximize the processing capacity of the target system and minimize the load on intermediate systems . However, performing data transformations at the target environment also requires the right tools and techniques to ensure data consistency and accuracy.
The ability to handle big data
- ETL’s strengths are its ability to handle structured, relational data and compute processing resources in-place , so it is suitable for traditional relational data systems.
- However, the weakness of ETL is the difficulty of scalability , because data transformation often occurs at a single point , resulting in server load and limited scalability.
- ELT allows handling of any data type, structured and unstructured , and has better extensibility than ETL. With ELT, data transformation is performed in the target environment, reducing the load on intermediate systems and taking full advantage of the target system’s processing power. This makes it easier to extend ELT systems .
It can be said that ELT is a natural development of ETL, one of the factors that promotes natural development is the need to store and process raw data in the age of huge and constantly evolving data. as diverse as today
Time to better understand before implementation
- ELT can take time to better understand data transformation tools and techniques at the target environment.
- ETL can take time to design and implement data transformation processes before the data is loaded into the target system.
Data processing during data transformation
- During ETL, data is often transformed and transformed before being loaded into the target system.
- During ELT, data is copied as-is to the target system before being transformed.
- With ETL, data loss during transformation can occur, because the original data has been transformed or discarded. Data loss errors can occur due to programming errors, database errors or system errors during data transformation.
- With ELT, data is copied as-is to the target system before being transformed. Therefore, no data is lost during data transformation, as the original data is preserved.
Therefore, ELT is more secure and reliable than ETL.
However, copying data as-is during ELT can be more time- and resource-intensive than in ETL. In addition, keeping the original data intact can also create security problems if not managed and controlled well.
In fact, ETL/ELT or Data Pipeline is much more complicated , I read an article about AirFlow, why it was born to solve that complexity. In the next article we will learn about AirFlow ^^

(To be continued)