“Digging mine” with Puppeteer
- Tram Ho
Written by Vu Van Phong
1. Headless browser
Headless browser is a term used to refer to the browser running without using a graphical interface, instead communicating with the browser via the command line interface. Headless browsers allow you to understand HTML as a regular browser, through which you can get information about web page components such as layout, colors, fonts, even JavaScript implementation, … Thanks to the possibilities, Headless browser is suitable for testing 1 special website, Automation Testing.
In addition to usability for Automation Testing, Headless browser can also be used to do some things like create a crawler to scratch data, screen screenshots, … There are lots of cool things we can do. through using Headless browser.
2. Puppeteer
Puppeteer is a ‘Node library’ developed by Google that provides APIs that control Chrome or Chromium through DevTools Protocol . The default Puppeteer runs in headless mode but can also be installed to run non-headless . Most of the things that can be done manually on the browser can be done with Puppeteer.
Considering the possibility of a framework for implementing Automation Test , Puppeteer still has many limitations compared to Selenium, or functional Webdriver / O when focusing on Chrome browser without supporting various platforms. Browser. However, to do some tools, it is very suitable because of the simplicity, easy to install, can run under headless mode without interfaces, so it is quite fast.
Maybe you are interested
10 mobile app trends are expected to dominate 2019
Some CSS tricks that Frontend itself may not even know (Part 1)
3. Create a crawler with Puppeteer
Problem:
Recently, to play around with some things, I need to search for Japanese grammar data. In the site Mazzi Dictionary I find quite a lot of data I want. The job is to create a crawler to retrieve that data and save it to your database.
Previously, when I needed to make a tool crawler, I used some libraries like scrapy , beautifulsoup to crawl static page. However, in my current case the data is being rendered via Javascript, creating a normal crawler as usual is no longer feasible. One solution is to use Scapy + Splash to solve this problem, but Splash’s script is written in Lua, so I switched to another approach that is using Puppeteer because of its simplicity.
Problem solving:
In this example using 2 libraries is mongoose , and puppeteer can be easily installed via npm :
npm install mongoosenpm install puppeteer
First we create a model.js file to save the data to the database:
1 2 3 4 5 6 7 8 9 10 11 12 13 | const mongoose = require ('mongoose'); let grammarSchema = new mongoose.Schema ({ title: String, mean: String, use: String, explain: String, examples: [{ja: String, vi: String}], }) let Grammar = mongoose.model ('Grammar', grammarSchema); module.exports = Grammar; |
Creating a crawler.js file to define crawler, crawler must perform operations:
- From the homepage choose to switch to
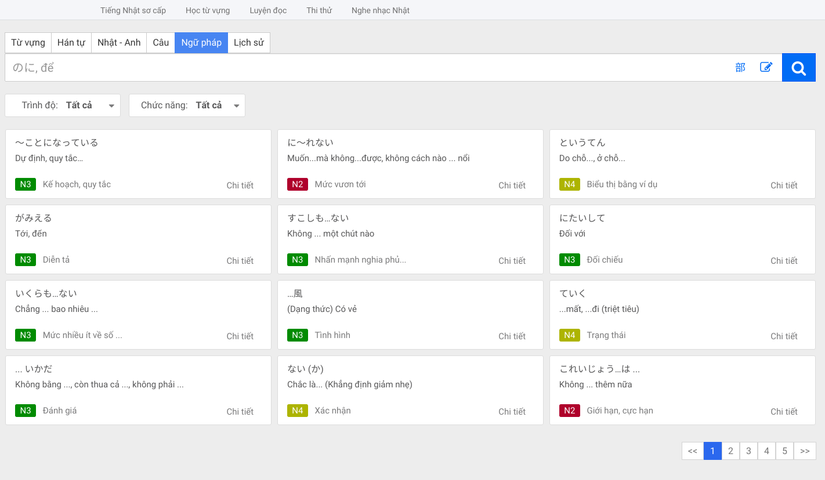
Ngữ pháptab - The Grammar tab displays 1 page, each page contains 12 grammar, click on each grammar pattern in turn and get the data in the popup displayed.
- After taking all the data of 1 page, move to the next page.
Visit the Mazzi Dictionary page, and get grammatical data samples:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | (async () => { const browser = await puppeteer.launch ({slowMo: 250}); // Use const browser = await puppeteer.launch ({headless: false, slowMo: 250}); to run on non-headless const page = await browser.newPage (); await page.setViewport ({width: 1200, height: 1800}); await page.goto ('http://mazii.net/#!/search'); // Click on the Grammar tab await page.click ('# tab3'); const pageSize = 12; // Number of pages you want to crawl // Get data on each page for (let i = 0; i <pageSize; i ++) { await getData (page); // Click to move to the next page await page.click ('div.box-pagination> ul> li: nth-child (8)'); } await browser.close (); }) (); |
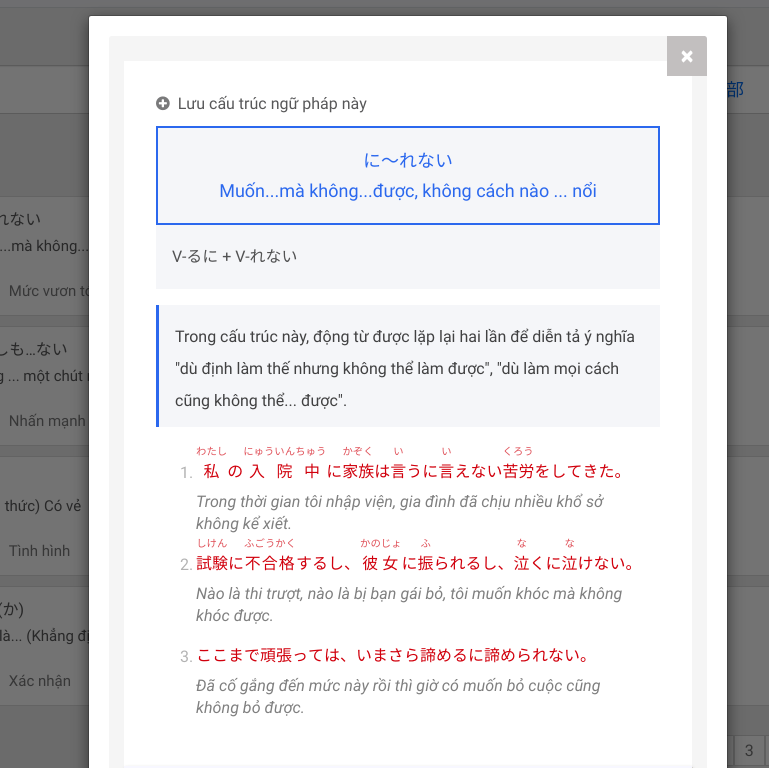
Definition of getData() function getData() : Our operation includes clicking on a grammar template -> Retrieving data from popup -> click close popup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | const getData = async (page) => { for (let i = 1; i <13; i ++) { try { await page.waitForSelector (`.box-card: nth-child ($ {i})`); page await.click (`.box-card: nth-child ($ {i})`); page.waitForSelector ('. grammar-item-title'); await page.waitForSelector ('. close-modal-jlpt'); // evaluate () allows JavaScript to be executed in the browser // Use Javascript to get data const grammar = await page.evaluate (() => { const title = document.querySelector ('. grammar-item-title'). textContent; const mean = document.querySelector ('. grammar-item-title-mean'). textContent; let use = ''; if (document.querySelector ('. gr-use-syn-item')! = null) { use + = document.querySelector ('. gr-use-syn-item'). textContent; } const explain = document.querySelector ('. gr-explain-note'). textContent; const examples = []; const examples_ele = document.querySelectorAll ('. japanese-char'); const examples_mean = document.querySelectorAll ('. example-mean-word'); const count_example = examples_ele.length; for (let i = 0; i <count_example; i ++) { let count_child_ja = examples_ele [i] .children.length; let ex_ja = ''; if (examples_ele [i] .hasAttribute ('ng-bind-html')) { ex_ja = examples_ele [i] .textContent.trim (); } else { cho (var j = 0; j <count_child_ja; j ++) { ex_ja + = examples_ele [i] .children [j] .firstChild.textContent.trim (); } } let ex_en = examples_mean [i] .textContent.trim (); examples.push ({ ja: ex_ja, en: ex_en }) } document.querySelector ('. close-modal-jlpt'). click (); return { title: title, mean: mean, use: use, explain: explain, examples: examples }; }); insert (grammar); } catch (error) { console.log (error); } } } |
Write a function that inserts data into the database:
1 2 3 4 5 6 7 8 9 | const insert = (Obj) => { const DB_URL = 'mongodb: // localhost: 27017 / grammar'; if (mongoose.connection.readyState == 0) {mongoose.connect (DB_URL); } let conditions = {title: Obj.title}; let options = {upsert: true, new: true, setDefaultsOnInsert: true}; Grammar.findOneAndUpdate (conditions, Obj, options, (err, result) => { if (err) throw err; }); } |
And here are the results: 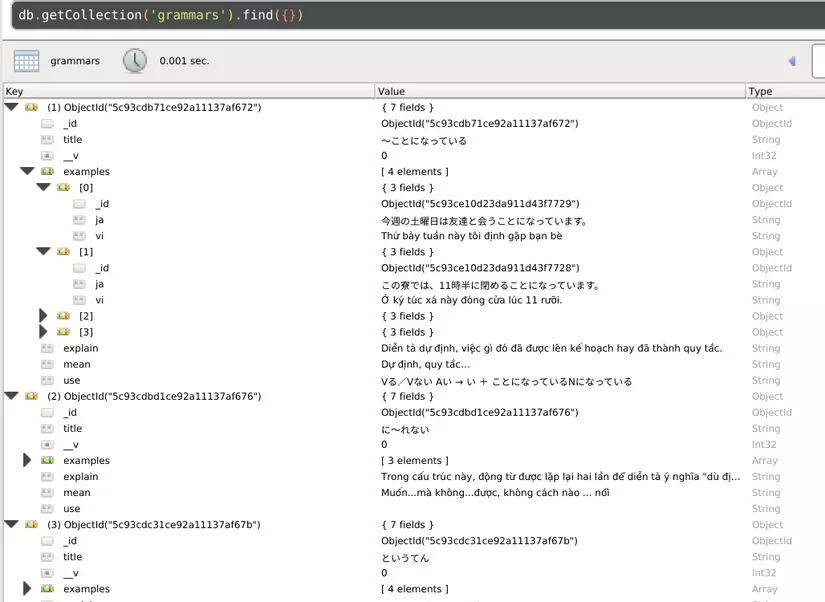 Thanks to everyone who followed the post
Thanks to everyone who followed the post
Link source code: Demo
Source : Viblo