Why should I use NoSQL?
Currently, services on the Internet have to deal with huge amounts of information and data and have a complex relationship with each other. Most of the data will be stored distributed on many different servers to ensure user access. Therefore, relational database management systems (RDBMS: Relational Database Management System) proved to be no longer suitable for services like this. People started to think about developing new DBMS (Database Management System) suitable to manage these distributed volumes of data and that is NoSQL.
In RDBMS, selecting a database management system is very easy because all database management systems such as MySQL, Oracle, MS SQL, etc. use the same type of solution towards properties. ACID (Atomicity, Consitency, Isolation, and Durability). When using NoSQL, the decision becomes difficult because NoSQL database offers different solutions and it is necessary to have a clear understanding of each solution in order to choose the solution that best suits your application / system requirements.
Example: If your data has the form:
- Document Databases (eg MongoDB): Document databases are often used to store JSON documents in collections and query related fields. It is possible to use this database to build applications that do not have too many relationships between documents.
- A good example of this type of application is – Blog Engine / If you want to host a product catalog.
- Graph Databases (ex: Neo4j): Graphical databases are often used to store relationships between entities, where nodes are entities and join edges are relationships. between them.
- For example, if you are building a social network and if user A follows user B. Then user A and user B can be nodes and “follow” is the connecting edge between them. Graph is a great way to do joining between nodes, even in the case of the link depth reaching 100 levels.
- Cache (ex: Redis): Cache is often used when you need extremely fast access to your data.
- For example, if you are building an e-commerce application. You have product categories that must be loaded on each page load event.
Instead of having to access the database for each of those readings (for each page load) which often takes time, you can store it in the cache which will make read / write work extremely fast. fast. Cache like Redis will be a buffer for your database for frequent data retrieval. It is possible to store data in cache and not have to access the database during the entire process.
- For example, if you are building an e-commerce application. You have product categories that must be loaded on each page load event.
- Search Databases (eg ElasticSearch): If you want to do a full text search on your data (e.g. products in an e-commerce application) then you need a search database like ElasticSearch, it has can help you perform searches on large amounts of data and give you an interesting set of features.
- Row Store (example: Cassandra): Cassandra is often used to store a form of data over time such as bulk analyzes / logs / data collected from sensor sensors. If you have a kind of application of that type that has a very large amount of data to write and little to read and the data is non-relational then Cassandra is the database that you should care about. next.
What is Cassandra?

Cassandra is a distributed database that combines the Google Bigtable data model with a distributed system design like a clone of Amazon Dynamo.
- July 2008: Cassandra is created by Facebook to solve its own database problems, then passed on to the open source community.
- March 2009: Cassandra becomes an Apache development project.
- February 17, 2010: Apache makes Cassandra its flagship project.
After more than 10 years in development, Cassandra has become one of the top management systems used by many organizations.
Some organizations use Cassandra as a database management system

Advantages of Cassandra
1, Open source
Cassandra is Apache’s open source project, which means it’s free. You can download the app and use it however you want. As it is open source, it creates a large user community for people to share their experiences, knowledge and suggestions related to Big Data. Furthermore, Cassandra can integrate with other Apache open source projects such as Hadoop, Apache Pig and Apache Hive.
2, Peer to peer architecture
Cassandra follows a peer-to-peer architecture, instead of a client / server architecture. The nodes in cassandra have a similar role, all take care of reading and writing data, reducing the risk of bottlenect (bottleneck). Therefore, there are no dead spots. Furthermore, any number of servers / nodes can be added to any Cassandra cluster in any data center. Certainly, with its strong architecture and special characteristics, Cassandra is much more advanced than other databases.
Nodes communicate with each other by Gossip communication – Gossip is a protocol used to update information about the state of other nodes participating in the cluster. This is a peer-to-peer communication protocol in which each node periodically exchanges its status information with the other nodes to which they are associated. The gossip process runs every second and exchanges information with at most three other nodes in the cluster. Nodes exchange information about themselves and also with the nodes they have exchanged, this way all nodes can quickly understand the state of all the remaining nodes in the cluster. A gossip packet includes its associated version, so in every gossip exchange, the old information is overwritten by the latest information in some nodes.
The number of firms using NoSQL is increasing and Cassandra is also increasingly used. Popular firms like NetFlix, eBay, Reddit, Ooyala use Cassandra to further increase their structure efficiency.
The largest known Cassandra system is one that holds 300TB of data spread over 400 separate machines.
Because of its good ability to handle large chunks of data, it is used for a wide variety of applications, from those that match the processing speed, to the incorporation of other technologies in real-time processing. by BigData.
3, Scalable elastic
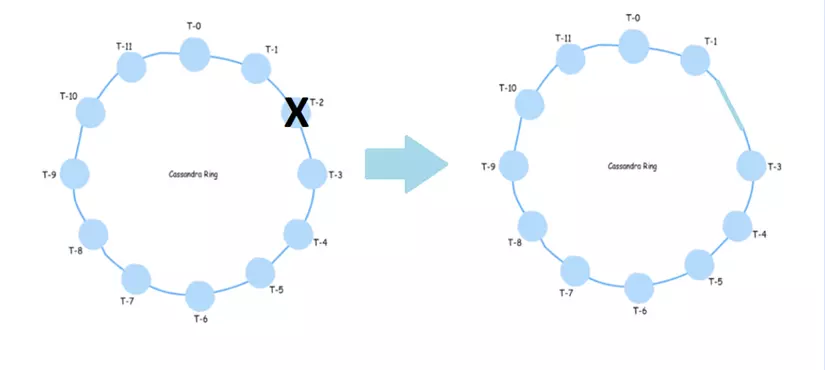
One of the advantages of using Cassandra is its elastic scalability. Cassandra cluster can be easily scaled or expanded. Any number of nodes can be added or removed in the Cassandra cluster without causing any disturbance. You do not need to restart cluster or change query related to Cassandra application while expanding or minimizing. When scaling read and write throughput both increase simultaneously with zero downtime or any application pause.
4, Highly Availbility and Fault Tolerance
- Another prominent feature of Cassandra is data copying which makes Cassandra highly error tolerant. Replication means each data is stored in multiple places. This allows even if one node fails, the user can still retrieve data from another location. In a Cassandra cluster, each row is replicated based on keyspaces. You can order as many copies as you want. Just like replication, data replication can also occur across multiple data centers. This leads to high resilience in Cassandra.
- When performing read and write operations, Cassandra can either work on the most recent copy or on all copies. This depends on the ConsitencyLevel parameter you set.
5 High efficiency
The basic idea behind Cassandra’s development is to exploit the hidden capabilities of certain multi-core machines. Cassandra made this dream come true. Cassandra demonstrated brilliant performance under large amounts of data. Therefore, Cassandra is loved by organizations that have large amounts of data and are unable to lose data.
A bit of an interesting comparison between Cassandra and MySQL with data larger than 50GB:
| Column 1 | average reading time | average recording time |
|---|---|---|
| MySQL | ~ 300ms | 0.12ms |
| Cassandra | ~ 350ms | 15ms |
Cassandra’s performance is higher than that of SQL administration systems when the amount of data input is greater than 50GB because it takes full advantage of the multi-core machines.
6, Column orientation
Cassandra has a highly data model – column oriented. That is, Cassandra caches columns based on column names, resulting in a very fast cut. Unlike traditional databases where the column name includes only metadata, in the Cassandra column name can also include the actual data. So the rows in Cassandra can contain a different number of columns. The data model in Cassandra is very rich.
Row-oriented RDBMSs must predefined columns in the tables. For Cassandra we don’t have to do that, we like to add as many columns to the row.
7, Consistency adjustable.
Data consistency in nodes can be arbitrarily adjusted:
- Copies of data are saved on all nodes
- The number of buttons for saving copies of data can be customized
8, Schema-less
In Cassandra, columns can be weights of your choice in rows. The Cassandra data model is well known as an optional schema data model. In contrast to a traditional database, rows with a different number of column sets can vary.
9, Cassandra is easy to learn and use
Cassandra uses CQL – Cassandra Query Language. It is basically SQL but has no advanced features. It sounds like a downside, but it’s a big advantage for Cassandra. Due to this simplicity, you can completely master Cassandra in a short time.
10, DISTRIBUTED AND DECENTRALIZED
The ability to split data into parts placed on different nodes while the user still sees this data as a unified block.
11, The ability to analyze
There are 4 main methods of performing analysis on Cassandra:
- Solr-based integrated search
- Batch analysis integrates Hadoop and Cassandra
- External batch analysis is supported by Hadoop and Cloudera / Hortonworks.
- Spark is based on real-time analysis.
Defect
- Cassandra does not support much computation on storage, it does not support sum, group, join, max, min and any other functions that developers want to use to compute data when querying.
- Because data is distributed, data is spread on many machines, so when there is an error in the database, the error will spread to all machines on the system.
Conclude
It can be seen that the advantage of Cassandra stems from the fact that it can store data, make copies on multiple machines. Fins exactly what that mechanism is like.
- Cassandra’s design is one that is distributed across thousands of servers without any centralization. Cassandra has a Peer to Peer design that all server nodes in the system play the same role and there is no server node when a real problem crashes the whole system like ants. Traditional Client / Server architecture. Cassandra’s host nodes are independent of each other and participate in the connection with other servers in the system.
- Each node can handle read and write operations, regardless of whether the data is physically stored on which server in the system. When a node fails and the machine stops working, the operation is performed on another server.
The article is referenced from many sources ^^