Break the classic code
Recently I tried Matasano's crypto challenges ( cryptopals.com ). This is basically a set of challenges about encryption, cryptography; in which players will try to complete practice exercises on coding (including installing common encryption algorithms, code breaks) from classic to modern. In challenge 3 and 4 , you are required to break the classic code, namely single-byte XOR. The encryption algorithm is simple, you will select a key K (1 byte length) and turn XOR in turn with the input bytes of the plaintext. It is easy to see that this is a modern and extensive version of the Caesar code . Here is the encryption algorithm:
1 2 3 | def single_byte_xor (msg: bytes, key: int) -> bytes: cipher = byte (b ^ khóa cho b trong msg) return cipher |
With Challenge 3, you will be provided with a ciphertext (encrypted using single-byte XOR) and your job is to find the plaintext. For this lesson, since the key space is small (256 values), you can try 256 possible values of the key ( 0x00 -> 0xFF ), decrypt the ciphertext with that key and see which plaintext is similar to English. Best.
But challenge 3 wants you to create a program that automatically decodes. In order to do this, we need to have a way to " mark " the plain text compared to English. That is, we need to know how the text has the same code as English. And we will choose the plaintext with the highest score.
Classical code systems can be broken by frequency analysis , so to build a " scoring " function we can use the knowledge of probability distribution of letters in English. The picture below is the frequency of English letters.
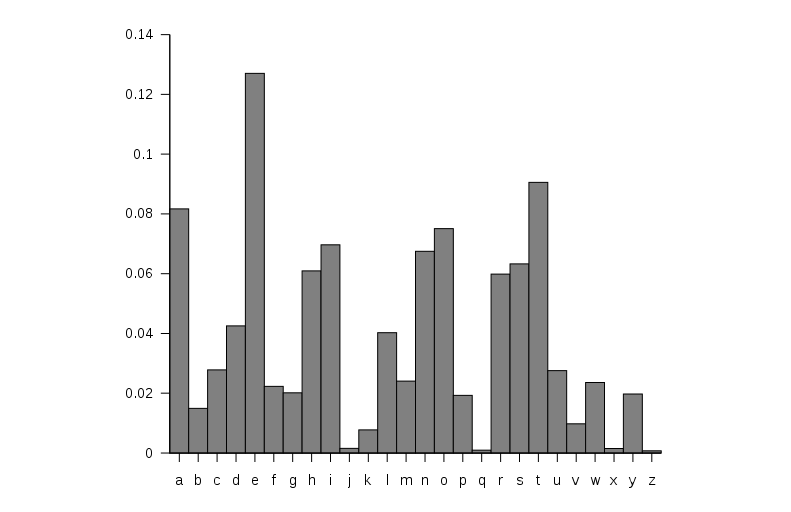
Source: https://en.wikipedia.org
With this challenge 3, I use Chi-squared statistics to judge the weight (grading) for the plaintext. Understand simple, Chi-squared statistics represent similarity between 2 probability distributions, the more 2 distributions are, the smaller and equal Chi-squared value if 2 distributions are identical. Here is the formula for Chi-squared:
Where, Ci is the number of occurrences of the letter i in the text, and Ei is the number of expected occurrences (Expected) of the letter i in the text.
Because in an English sentence, a space character appears a lot, so in order to better evaluate it, I used both space characters when calculating Chi-squared. You can get the probability data of the English alphabet including space at http://www.data-compression.com/english.shtml .
We can complete the challenge 3 by selecting the clearest version of Chi-squared.
But to complete challenge 4 we need to use more accurate weight evaluation, which is to use Chi-square for 2-letter pairs. The data you can get at english_bigram .
In the next article, I will present my solutions to challenges 5 and 6 . If you are an avid reader , cryptanalyst, and modern cryptanalysis, try Matasano's crypto challenges .
This is my solution if you are interested: https://github.com/vuonghv/cryptopals