Introduce
What is metameter?
For those of you who have built deep learning models, it is certainly no stranger to this concept of metameter. In machine learning and deep learning, metameter is the parameters for which its value can be. This model controls the training process. It is not fixed, varies by problem, training process and can change during that training. In particular, it plays an important role in determining the model’s performance. Examples of metadata such as the number of units and layers in the neural network, or in a network trainer with metadata such as batchsize, learning rate schedule, optimizer, momentum, adam alpha, …
What is Optuna?
Optuna is a framework that automatically adjusts model parameters so that the best model can achieve the best performance.
Difficulty encountered when having to adjust parameters manually
Problem: you need to create an MLP model, how to choose the number of hidden layers, the number of units in a layer appropriately and accurately?
Choosing super parameters when doing the training model seems to be based on your feelings and experiences. And this doesn’t always get the best performance out of a model. And for those of you who do not have experience in super-parameter selection, this is really a challenge.
How to use the Optuna library in Pytorch
Install
1 2 | pip install optuna |
Define objective function
1 2 3 4 | <span class="token keyword">def</span> <span class="token function">objective</span> <span class="token punctuation">(</span> trial <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">return</span> |
Trial object definition
Trial is an instance of a class that is implemented in Optuna.It is used to define the optimized super parameters.The value is taken within the scope you define, the information of the parameters is Past searches are retained and new values will be based on that information. Trial is defined as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <span class="token comment"># Tham số thực hiện chọn loại </span> param1 <span class="token operator">=</span> Trial <span class="token punctuation">.</span> Suggest_categorical <span class="token punctuation">(</span> Name <span class="token punctuation">,</span> Choices <span class="token punctuation">)</span> <span class="token comment"># Định nghĩa tham số nguyên cho trial</span> param2 <span class="token operator">=</span> trial <span class="token punctuation">.</span> Suggest_int <span class="token punctuation">(</span> name <span class="token punctuation">,</span> low <span class="token punctuation">,</span> high <span class="token punctuation">)</span> <span class="token comment"># Biểu diễn tham số có giá trị liên tục</span> param3 <span class="token operator">=</span> trial <span class="token punctuation">.</span> Suggest_uniform <span class="token punctuation">(</span> name <span class="token punctuation">,</span> low <span class="token punctuation">,</span> high <span class="token punctuation">)</span> <span class="token comment"># Biểu diễn tham số có giá trị rời rạc</span> param4 <span class="token operator">=</span> trial <span class="token punctuation">.</span> Suggest_discrete_uniform <span class="token punctuation">(</span> name <span class="token punctuation">,</span> low <span class="token punctuation">,</span> high <span class="token punctuation">,</span> q <span class="token punctuation">)</span> <span class="token comment"># Biểu diễn các tham số logarithm</span> param5 <span class="token operator">=</span> trial <span class="token punctuation">.</span> Suggest_loguniform <span class="token punctuation">(</span> name <span class="token punctuation">,</span> low <span class="token punctuation">,</span> high <span class="token punctuation">)</span> |
name is the type of string and the value is the name of the parameter. Choicesis is a list form and it is represented as the choice of names of many types. Low and high are minimum and maximum values of parameter. Example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <span class="token keyword">def</span> <span class="token function">objective</span> <span class="token punctuation">(</span> trial <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token comment"># Categorical parameter</span> optimizer <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_categorical <span class="token punctuation">(</span> <span class="token string">'optimizer'</span> <span class="token punctuation">,</span> <span class="token punctuation">[</span> <span class="token string">'MomentumSGD'</span> <span class="token punctuation">,</span> <span class="token string">'Adam'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token comment"># Int parameter</span> num_layers <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_int <span class="token punctuation">(</span> <span class="token string">'num_layers'</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token comment"># Uniform parameter</span> dropout_rate <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_uniform <span class="token punctuation">(</span> <span class="token string">'dropout_rate'</span> <span class="token punctuation">,</span> <span class="token number">0.0</span> <span class="token punctuation">,</span> <span class="token number">1.0</span> <span class="token punctuation">)</span> <span class="token comment"># Loguniform parameter</span> learning_rate <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_loguniform <span class="token punctuation">(</span> <span class="token string">'learning_rate'</span> <span class="token punctuation">,</span> <span class="token number">1e</span> <span class="token operator">-</span> <span class="token number">5</span> <span class="token punctuation">,</span> <span class="token number">1e</span> <span class="token operator">-</span> <span class="token number">2</span> <span class="token punctuation">)</span> <span class="token comment"># Discrete-uniform parameter</span> drop_path_rate <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_discrete_uniform <span class="token punctuation">(</span> <span class="token string">'drop_path_rate'</span> <span class="token punctuation">,</span> <span class="token number">0.0</span> <span class="token punctuation">,</span> <span class="token number">1.0</span> <span class="token punctuation">,</span> <span class="token number">0.1</span> <span class="token punctuation">)</span> |
Defines study object
To search for metameter, you need to initialize an object study. This object saves your optimal results.
1 2 | Study <span class="token operator">=</span> Optuna <span class="token punctuation">.</span> Creat_study <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
Then, using the optimize method:
1 2 | Study <span class="token punctuation">.</span> Optimize <span class="token punctuation">(</span> Objective <span class="token punctuation">,</span> N_trials <span class="token operator">=</span> <span class="token number">100</span> <span class="token punctuation">)</span> |
In which, the first parameter is the Objective function, the second parameter is the number of tests. This optimization process is done in Study object and will perform to find the minimum value of the parameters in Objective function by optimization method. At the end of the above process, the optimal value will be saved and you can view it with the following command:
1 2 3 4 5 6 7 8 9 10 11 | <span class="token comment"># Giá trị tối ưu của các tham số khởi tạo trong hàm **Objective**</span> Study <span class="token punctuation">.</span> Best_params <span class="token comment"># Kết quả mô hình tương ứng với các tham số tối ưu trên</span> Study <span class="token punctuation">.</span> Best_value <span class="token comment"># Xem tất cả trạng thái của các lần thử nghiệm</span> Study <span class="token punctuation">.</span> Trials |
Experiment and comparison between model using Optuna and selecting super parameter rice on Iris set
Install Optuna
You can install Optuna using pip or conda
1 2 | !pip install <span class="token operator">-</span> <span class="token operator">-</span> quiet optuna |
Check version
1 2 3 | <span class="token keyword">import</span> optuna optuna <span class="token punctuation">.</span> __version__ |
Super-parameter optimization
Experiment with the model to select the test parameters
I will perform testing the random forest model to perform classification on the Iris dataset and manually select the parameters as follows:
1 2 3 4 5 6 7 8 9 10 | <span class="token keyword">import</span> sklearn <span class="token punctuation">.</span> datasets <span class="token keyword">import</span> sklearn <span class="token punctuation">.</span> ensemble <span class="token keyword">import</span> sklearn <span class="token punctuation">.</span> model_selection iris <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> datasets <span class="token punctuation">.</span> load_iris <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token comment"># Prepare the data.</span> clf <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> ensemble <span class="token punctuation">.</span> RandomForestClassifier <span class="token punctuation">(</span> n_estimators <span class="token operator">=</span> <span class="token number">5</span> <span class="token punctuation">,</span> max_depth <span class="token operator">=</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token comment"># Define the model.</span> sklearn <span class="token punctuation">.</span> model_selection <span class="token punctuation">.</span> cross_val_score <span class="token punctuation">(</span> clf <span class="token punctuation">,</span> iris <span class="token punctuation">.</span> data <span class="token punctuation">,</span> iris <span class="token punctuation">.</span> target <span class="token punctuation">,</span> n_jobs <span class="token operator">=</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> cv <span class="token operator">=</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
The result achieved by the above model is: 0.966. Fortunately, the results are quite good with n_estimators = 5 and max_depth = 3.
Experiment using Optuna to automatically adjust parameters
The superparameter of the above model is n_estimators and max_depth. Use trial objects to define them. Then create a study object to optimize this meta-parameter and finally get the best one.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <span class="token keyword">import</span> optuna <span class="token keyword">def</span> <span class="token function">objective</span> <span class="token punctuation">(</span> trial <span class="token punctuation">)</span> <span class="token punctuation">:</span> iris <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> datasets <span class="token punctuation">.</span> load_iris <span class="token punctuation">(</span> <span class="token punctuation">)</span> n_estimators <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_int <span class="token punctuation">(</span> <span class="token string">'n_estimators'</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">20</span> <span class="token punctuation">)</span> max_depth <span class="token operator">=</span> <span class="token builtin">int</span> <span class="token punctuation">(</span> trial <span class="token punctuation">.</span> suggest_float <span class="token punctuation">(</span> <span class="token string">'max_depth'</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">32</span> <span class="token punctuation">,</span> log <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> clf <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> ensemble <span class="token punctuation">.</span> RandomForestClassifier <span class="token punctuation">(</span> n_estimators <span class="token operator">=</span> n_estimators <span class="token punctuation">,</span> max_depth <span class="token operator">=</span> max_depth <span class="token punctuation">)</span> <span class="token keyword">return</span> sklearn <span class="token punctuation">.</span> model_selection <span class="token punctuation">.</span> cross_val_score <span class="token punctuation">(</span> clf <span class="token punctuation">,</span> iris <span class="token punctuation">.</span> data <span class="token punctuation">,</span> iris <span class="token punctuation">.</span> target <span class="token punctuation">,</span> n_jobs <span class="token operator">=</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> cv <span class="token operator">=</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">)</span> study <span class="token operator">=</span> optuna <span class="token punctuation">.</span> create_study <span class="token punctuation">(</span> direction <span class="token operator">=</span> <span class="token string">'maximize'</span> <span class="token punctuation">)</span> study <span class="token punctuation">.</span> optimize <span class="token punctuation">(</span> objective <span class="token punctuation">,</span> n_trials <span class="token operator">=</span> <span class="token number">100</span> <span class="token punctuation">)</span> |
After finishing the optimization process after 100 trials, we have the best test.
1 2 3 4 5 | trial <span class="token operator">=</span> study <span class="token punctuation">.</span> best_trial <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">'Accuracy: {}'</span> <span class="token punctuation">.</span> <span class="token builtin">format</span> <span class="token punctuation">(</span> trial <span class="token punctuation">.</span> value <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">"Best hyperparameters: {}"</span> <span class="token punctuation">.</span> <span class="token builtin">format</span> <span class="token punctuation">(</span> trial <span class="token punctuation">.</span> params <span class="token punctuation">)</span> <span class="token punctuation">)</span> |
The following results :
1 2 3 | Accuracy <span class="token punctuation">:</span> <span class="token number">0.9733333333333333</span> Best hyperparameters <span class="token punctuation">:</span> <span class="token punctuation">{</span> <span class="token string">'n_estimators'</span> <span class="token punctuation">:</span> <span class="token number">7</span> <span class="token punctuation">,</span> <span class="token string">'max_depth'</span> <span class="token punctuation">:</span> <span class="token number">8.773682352088931</span> <span class="token punctuation">}</span> |
As such, the accuracy will increase by more than 1%, and the metrics will change and not be the same as I manually selected above.
Test datasets on different algorithms
Until now, testing on different algorithms to get the most objective assessment takes a lot of coding and training, now Optuna has supported you with that. Let’s get it!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | <span class="token keyword">import</span> sklearn <span class="token punctuation">.</span> svm <span class="token keyword">def</span> <span class="token function">objective</span> <span class="token punctuation">(</span> trial <span class="token punctuation">)</span> <span class="token punctuation">:</span> iris <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> datasets <span class="token punctuation">.</span> load_iris <span class="token punctuation">(</span> <span class="token punctuation">)</span> classifier <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_categorical <span class="token punctuation">(</span> <span class="token string">'classifier'</span> <span class="token punctuation">,</span> <span class="token punctuation">[</span> <span class="token string">'RandomForest'</span> <span class="token punctuation">,</span> <span class="token string">'SVC'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token keyword">if</span> classifier <span class="token operator">==</span> <span class="token string">'RandomForest'</span> <span class="token punctuation">:</span> n_estimators <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_int <span class="token punctuation">(</span> <span class="token string">'n_estimators'</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token number">20</span> <span class="token punctuation">)</span> max_depth <span class="token operator">=</span> <span class="token builtin">int</span> <span class="token punctuation">(</span> trial <span class="token punctuation">.</span> suggest_float <span class="token punctuation">(</span> <span class="token string">'max_depth'</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">32</span> <span class="token punctuation">,</span> log <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> clf <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> ensemble <span class="token punctuation">.</span> RandomForestClassifier <span class="token punctuation">(</span> n_estimators <span class="token operator">=</span> n_estimators <span class="token punctuation">,</span> max_depth <span class="token operator">=</span> max_depth <span class="token punctuation">)</span> <span class="token keyword">else</span> <span class="token punctuation">:</span> c <span class="token operator">=</span> trial <span class="token punctuation">.</span> suggest_float <span class="token punctuation">(</span> <span class="token string">'svc_c'</span> <span class="token punctuation">,</span> <span class="token number">1e</span> <span class="token operator">-</span> <span class="token number">10</span> <span class="token punctuation">,</span> <span class="token number">1e10</span> <span class="token punctuation">,</span> log <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> clf <span class="token operator">=</span> sklearn <span class="token punctuation">.</span> svm <span class="token punctuation">.</span> SVC <span class="token punctuation">(</span> C <span class="token operator">=</span> c <span class="token punctuation">,</span> gamma <span class="token operator">=</span> <span class="token string">'auto'</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> sklearn <span class="token punctuation">.</span> model_selection <span class="token punctuation">.</span> cross_val_score <span class="token punctuation">(</span> clf <span class="token punctuation">,</span> iris <span class="token punctuation">.</span> data <span class="token punctuation">,</span> iris <span class="token punctuation">.</span> target <span class="token punctuation">,</span> n_jobs <span class="token operator">=</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> cv <span class="token operator">=</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> mean <span class="token punctuation">(</span> <span class="token punctuation">)</span> study <span class="token operator">=</span> optuna <span class="token punctuation">.</span> create_study <span class="token punctuation">(</span> direction <span class="token operator">=</span> <span class="token string">'maximize'</span> <span class="token punctuation">)</span> study <span class="token punctuation">.</span> optimize <span class="token punctuation">(</span> objective <span class="token punctuation">,</span> n_trials <span class="token operator">=</span> <span class="token number">100</span> <span class="token punctuation">)</span> |
Let’s see the results:
1 2 3 4 5 | trial <span class="token operator">=</span> study <span class="token punctuation">.</span> best_trial <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">'Accuracy: {}'</span> <span class="token punctuation">.</span> <span class="token builtin">format</span> <span class="token punctuation">(</span> trial <span class="token punctuation">.</span> value <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">"Best hyperparameters: {}"</span> <span class="token punctuation">.</span> <span class="token builtin">format</span> <span class="token punctuation">(</span> trial <span class="token punctuation">.</span> params <span class="token punctuation">)</span> <span class="token punctuation">)</span> |
1 2 3 | Accuracy <span class="token punctuation">:</span> <span class="token number">0.9866666666666667</span> Best hyperparameters <span class="token punctuation">:</span> <span class="token punctuation">{</span> <span class="token string">'classifier'</span> <span class="token punctuation">:</span> <span class="token string">'SVC'</span> <span class="token punctuation">,</span> <span class="token string">'svc_c'</span> <span class="token punctuation">:</span> <span class="token number">4.448968980739045</span> <span class="token punctuation">}</span> |
After only a few lines of code using Optuna , the accuracy is 0.987%, and as above, the SVC model has better results than the Random forest.
Visualization with Optuna
Not only supports the automatic optimization of the super parameters, she also assists us in visualizing the state of the tests.
- Visualize history of study object
1 2 | optuna <span class="token punctuation">.</span> visualization <span class="token punctuation">.</span> plot_optimization_history <span class="token punctuation">(</span> study <span class="token punctuation">)</span> |
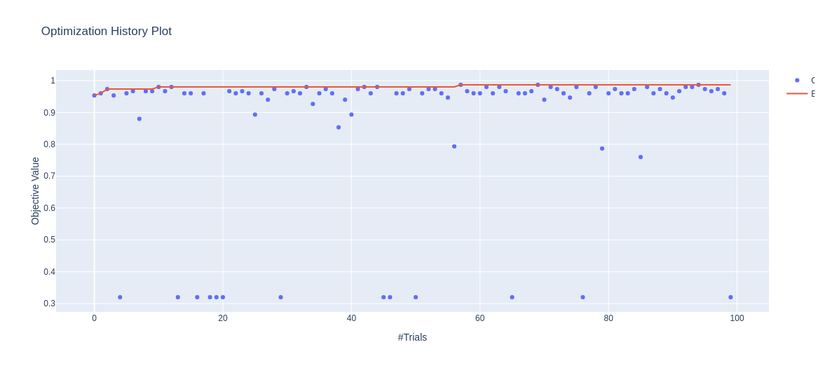
2. Visualize the precision of a super-parameter at each test
1 2 | optuna <span class="token punctuation">.</span> visualization <span class="token punctuation">.</span> plot_contour <span class="token punctuation">(</span> study <span class="token punctuation">,</span> params <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token string">'n_estimators'</span> <span class="token punctuation">,</span> <span class="token string">'max_depth'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> |
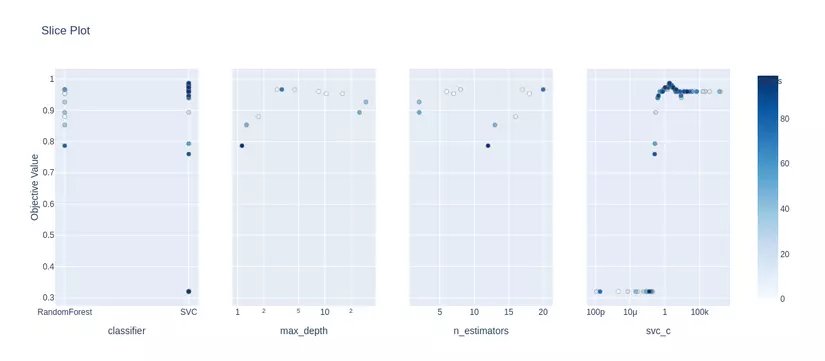
- Visualize accuracy surface for many parameters of the random forest model
1 2 | optuna <span class="token punctuation">.</span> visualization <span class="token punctuation">.</span> plot_contour <span class="token punctuation">(</span> study <span class="token punctuation">,</span> params <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token string">'n_estimators'</span> <span class="token punctuation">,</span> <span class="token string">'max_depth'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> |
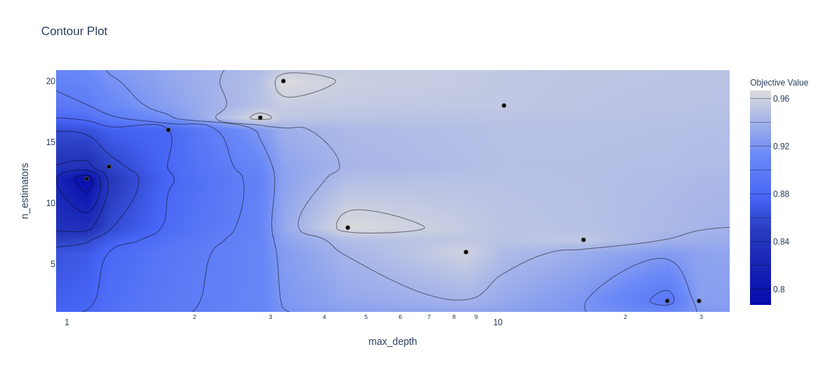
Conclude
If you are wondering or wasting time choosing parameters, give Optuna a try. If this article is interested by everyone, I will try to learn and write more articles about prunning model using Optuna. Thank you for watching, please leave 1 vote for me.