Xin chào các bạn. Lại là mình đây – Minh Monmen – người sẽ đồng hành cùng các bạn trong những phút giây thú vị tiếp theo (nếu các bạn còn đọc tới hết bài). Chuyện là hôm vừa rồi mình vừa dự một buổi meetup của nhóm Vietkubers về K8S tại Hà Nội. Trong đó có một section về Zero-downtime khi upgrade cluster. Thật sự là mình cảm thấy phần trình bày của các bạn ấy thiếu thiếu cái gì đó, do vậy về nhà phải tức tốc lục lại toàn bộ kiến thức của mình về vấn đề này để hệ thống lại cho quy củ. Cũng tiện tay viết lại mấy dòng để các bạn cùng tham khảo và bàn luận cùng mình.

First things first
Tên, như mình đã nói ở trên: Minh Monmen. (Tranh thủ quảng bá tên tuổi tí  ).
).
Kiến thức cần có trước khi đọc:
- Kubernetes là gì, tất nhiên rồi
- K8S manifest viết bằng yaml
- Deploy app lên K8S
Mình dự định sẽ viết bài này thành một series, bởi vì vấn đề zero-downtime nó không hề đơn giản. Application có muôn hình vạn trạng, do vậy mà vấn đề mà từng application gặp phải cũng khác nhau. Trong phần đầu tiên này, mình sẽ đề cập những khái niệm cơ bản, cũng như một case application được gọi là lý tưởng với k8s để chúng ta thử nghiệm. Nếu các bạn ủng hộ thì chắc mình sẽ có động lực viết tiếp phần 2, phần 3 về các case khó hơn mình đã gặp. Còn không thì chắc là… thôi =)).
Okay? Let’s begin!
Lưu ý: Trong bài có thể có 1 số thuật ngữ/từ ngữ mình dùng chưa được chính xác vì mình chưa nghĩ ra được cách diễn đạt nó bằng từ ngữ chuẩn chỉ. Các bạn có thể chỉ cần hiểu được ý nghĩa mình muốn nói là được, đừng bắt bẻ câu chữ nhé.
Stateful và stateless app
Chắc các bạn đã nghe chán chê thuật ngữ gọi là stateless và stateful rồi. Tuy nhiên mình nghĩ để hiểu được nó cho đúng thì cũng không đơn giản. Mình cũng phát hiện một điều rằng rất nhiều bài viết bây giờ đề cập tới stateless, stateful và cho rằng người đọc đã tự hiểu hai thuật ngữ đó nói tới cái gì. Tuy nhiên theo kinh nghiệm cá nhân khi training các bạn khác thì mình thấy hầu hết đều bị hiểu trật lất hết cả.

Thật ra stateless hay stateful là 2 từ chỉ 2 tính chất rất chung chung và có rất nhiều khía cạnh, trong khi đó mọi người lại hay hiểu nó một cách rất gò bó. Ví dụ mặc định cứ cái gì có session là stateful, có token là stateless,… Nope, nope và nope.
Stateful và stateless nên được hiểu ở từng ngữ cảnh cụ thể. Ví dụ ta có 1 shopping cart app chạy 3 instances:
- HTTP request
GET /cartđược gọi là stateless ở ngữ cảnh connection: do 1 request này mở 1 connection mới tới server, sau đó đóng connection đó lại. Toàn bộ thông tin nó cần truyền tải đã chứa trong request. - HTTP request
GET /cartđược gọi là stateful ở ngữ cảnh application: do để lấy được thông tin cart thì server phải lưu lại thông tin về cart từ các request trước bằng session/cookie. - Nếu session được lưu trên 1 persistent storage chung giữa các instance, ví dụ 1 con redis ở ngoài, vậy thì instance của chúng ta là stateless, do instance của chúng ta thực chất không lưu thông tin gì của request trước đó cả. Còn thằng redis để lưu session kia là stateful
- Nếu session được lưu in-memory trên từng instance, vây là instance của chúng ta lại là stateful.
Qua ví dụ trên, ta có thể thấy tùy vào từng ngữ cảnh cụ thể mà cái ta đang nói đến có thể có tính chất stateless hay stateful khác nhau.
Trong bài viết này, mình sẽ đề cập tới 1 ứng dụng lý tưởng với k8s. 1 ứng dụng stateless ở ngữ cảnh instance và cũng stateless ở ngữ cảnh connection. Các tiêu chí nó cần đạt được là:
- Không lưu thông tin trực tiếp trên instance app.
- Connection dạng request-response tức thời.
Zero-downtime và bài toán gặp phải
Chắc mình không cần phải nói cho các bạn thuật ngữ zero-downtime là gì nữa phải hôn? Zero-downtime tức là ứng dụng không có thời gian chết – rõ ràng rồi. Tuy nhiên để đạt được trạng thái zero-downtime thì chúng ta phải kết hợp rất nhiều yếu tố, từ việc code app sao cho đúng, tới việc triển khai thế nào cho chuẩn. Zero-downtime phải được thoả mãn trong các case sau:
- Scale up ứng dụng, tăng thêm instance chạy.
- Scale down ứng dụng, giảm số instance chạy.
- Update ứng dụng bằng phiên bản mới.
- Update hạ tầng triển khai (update phần mềm, update phần cứng).
Các case này là các case chủ động, ở đây mình sẽ không đề cập tới các case bị động như xảy ra lỗi, node down,… vì nó ở ngoài phạm vi của bài viết này.
Phần mà bài nói của các bạn Vietkubers đề cập tới thật ra chỉ là 1 case update phần mềm triển khai. Tức là phần ngọn của triển khai zero-downtime. Để có thể đạt được zero-downtime ở case đó, trước hết ứng dụng của các bạn phải đạt đủ điều kiện cho quá trình zero-downtime đã. Các điều kiện cần đó là:
- Có cơ chế graceful shutdown
- Có đủ thời gian move request sang các instance khác trước khi shutdown
- Instance mới phải sẵn sàng xử lý request khi join load-balancing
Từ 2 điều kiện này ta có thể thấy với các ứng dụng khác nhau sẽ có các case phải giải quyết khác nhau. Ví dụ 1 số case như sau:
- Ứng dụng request-response có thời gian phản hồi nhanh, không phụ thuộc instance xử lý (lý tưởng – case trong bài này)
- Ứng dụng req-res có thời gian phản hồi chậm (ví dụ các ứng dụng upload, xử lý dữ liệu lớn,…)
- Ứng dụng req-res phụ thuộc instance xử lý / request phía trước (ví dụ các app frontend SPA khi gọi css/js,…)
- Ứng dụng sử dụng persistent connection (ví dụ ứng dụng sử dụng websocket,…)
Chuẩn bị đồ nghề
Ứng dụng lý tưởng
Để cho đơn giản, trong bài viết này mình sẽ demo cho các bạn 1 ứng dụng stateless lý tưởng, dạng req-res và có thời gian response nhanh. gcr.io/google-samples/hello-app là một image docker có duy nhất nhiệm vụ hiển thị hostname và version của container đang chạy, rất lý tưởng cho việc test của chúng ta khi thực hiện update app lên phiên bản mới.
Công cụ test
Mình sẽ dùng 1 tool có tên là fortio để tạo request tới app trên k8s cluster của chúng ta. Công cụ này sẽ giúp chúng ta tạo request liên tục tới app và thống kê các request gặp lỗi.
Môi trường
1 Cụm K8S đang hoạt động hoặc K8S local (chạy với minikube) đều được, vì chúng ta đang thử nghiệm zero-downtime ở mức độ instance – pod, không phải ở mức độ k8s node.
Triển khai với cấu hình mặc định
Và giờ là thời khắc để bắt đầu triển khai ứng dụng. Mình có K8S manifest với deployment và service đơn giản sau:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | <span class="token key atrule">apiVersion</span><span class="token punctuation">:</span> apps/v1 <span class="token key atrule">kind</span><span class="token punctuation">:</span> Deployment <span class="token key atrule">metadata</span><span class="token punctuation">:</span> <span class="token key atrule">name</span><span class="token punctuation">:</span> hello<span class="token punctuation">-</span>app <span class="token key atrule">spec</span><span class="token punctuation">:</span> <span class="token key atrule">replicas</span><span class="token punctuation">:</span> <span class="token number">2</span> <span class="token key atrule">selector</span><span class="token punctuation">:</span> <span class="token key atrule">matchLabels</span><span class="token punctuation">:</span> <span class="token key atrule">app</span><span class="token punctuation">:</span> hello<span class="token punctuation">-</span>app <span class="token key atrule">template</span><span class="token punctuation">:</span> <span class="token key atrule">metadata</span><span class="token punctuation">:</span> <span class="token key atrule">labels</span><span class="token punctuation">:</span> <span class="token key atrule">app</span><span class="token punctuation">:</span> hello<span class="token punctuation">-</span>app <span class="token key atrule">spec</span><span class="token punctuation">:</span> <span class="token key atrule">containers</span><span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span><span class="token punctuation">:</span> gcr.io/google<span class="token punctuation">-</span>samples/hello<span class="token punctuation">-</span>app<span class="token punctuation">:</span><span class="token number">1.0</span> <span class="token key atrule">imagePullPolicy</span><span class="token punctuation">:</span> Always <span class="token key atrule">name</span><span class="token punctuation">:</span> hello<span class="token punctuation">-</span>app <span class="token key atrule">ports</span><span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">containerPort</span><span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token punctuation">---</span> <span class="token key atrule">apiVersion</span><span class="token punctuation">:</span> v1 <span class="token key atrule">kind</span><span class="token punctuation">:</span> Service <span class="token key atrule">metadata</span><span class="token punctuation">:</span> <span class="token key atrule">name</span><span class="token punctuation">:</span> hello<span class="token punctuation">-</span>app <span class="token key atrule">spec</span><span class="token punctuation">:</span> <span class="token key atrule">type</span><span class="token punctuation">:</span> NodePort <span class="token key atrule">ports</span><span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">port</span><span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">targetPort</span><span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">nodePort</span><span class="token punctuation">:</span> <span class="token number">30001</span> <span class="token key atrule">protocol</span><span class="token punctuation">:</span> TCP <span class="token key atrule">selector</span><span class="token punctuation">:</span> <span class="token key atrule">app</span><span class="token punctuation">:</span> hello<span class="token punctuation">-</span>app |
Tiếp đó hãy thử apply vào cluster nhé:
1 2 3 4 5 6 7 8 | $ kubectl apply -f hello-app.yaml deployment.apps/hello-app created service/hello-app created $ kubectl get pods NAME READY STATUS RESTARTS AGE hello-app-789b7b9c97-hf9rr 1/1 Running 0 2s hello-app-789b7b9c97-tfdwj 1/1 Running 0 2s |
Các bạn hãy bật 1 cửa sổ terminal nữa lên và chạy lệnh sau để theo dõi quá trình thay đổi của service, replicaset và pod trên k8s nhé:
1 2 | $ <span class="token function">watch</span> -n 2 <span class="token string">"kubectl get services && kubectl get replicasets && kubectl get pods"</span> |
Câu lệnh trên có nghĩa là cứ 2s sẽ gọi lệnh phía sau 1 lần
Chạy thử vào app của chúng ta xem sao:
1 2 3 4 5 6 7 8 9 | $ <span class="token function">curl</span> http://157.230.xxx.yyy:30001/ Hello, world<span class="token operator">!</span> Version: 1.0.0 Hostname: hello-app-789b7b9c97-hf9rr $ <span class="token function">curl</span> http://157.230.xxx.yyy:30001/ Hello, world<span class="token operator">!</span> Version: 1.0.0 Hostname: hello-app-789b7b9c97-tfdwj |
Vậy là chúng ta đã triển khai thành công ứng dụng hello-app phiên bản 1.0 với service dạng NodePort tại cổng 30001 trên server. Thử curl vào endpoint trên ta sẽ thấy lần lượt các pod đang chạy được load-balancing để phản hồi yêu cầu của chúng ta.
Giờ chúng ta sửa lại image của deployment trên thành version 2.0 nhé
1 2 3 4 5 6 7 8 | <span class="token punctuation">...</span> <span class="token key atrule">spec</span><span class="token punctuation">:</span> <span class="token key atrule">template</span><span class="token punctuation">:</span> <span class="token key atrule">spec</span><span class="token punctuation">:</span> <span class="token key atrule">containers</span><span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span><span class="token punctuation">:</span> gcr.io/google<span class="token punctuation">-</span>samples/hello<span class="token punctuation">-</span>app<span class="token punctuation">:</span><span class="token number">2.0</span> <span class="token punctuation">...</span> |
Bắt đầu triển khai fortio nào:
1 2 | $ fortio load -qps 100 -t 60s <span class="token string">"http://157.230.xxx.yyy:30001/"</span> |
Lệnh trên chạy fortio load 100 request/s trong thời gian 60s
Và apply image mới nào:
1 2 3 4 | $ kubectl apply -f hello-app.yaml deployment.apps/hello-app configured service/hello-app unchanged |
Đây là kết quả test:
1 2 3 4 5 6 7 | Sockets used: 11 <span class="token punctuation">(</span>for perfect keepalive, would be 4<span class="token punctuation">)</span> Code -1 <span class="token keyword">:</span> 2 <span class="token punctuation">(</span>0.1 %<span class="token punctuation">)</span> Code 200 <span class="token keyword">:</span> 3964 <span class="token punctuation">(</span>99.9 %<span class="token punctuation">)</span> Response Header Sizes <span class="token keyword">:</span> count 3966 avg 116.9705 +/- 1.858 min 0 max 117 <span class="token function">sum</span> 463905 Response Body/Total Sizes <span class="token keyword">:</span> count 3966 avg 182.95386 +/- 2.905 min 0 max 183 <span class="token function">sum</span> 725595 All <span class="token keyword">done</span> 3966 calls <span class="token punctuation">(</span>plus 4 warmup<span class="token punctuation">)</span> 60.572 ms avg, 66.0 qps |
Vậy là vẫn có 1 lượng nhỏ (0.1%) request gặp lỗi khi chúng ta update app. Tại sao vậy?
Tìm hiểu vấn đề
Đầu tiên chúng ta hãy nhắc tới các cơ chế replace pod của K8S. Có 2 kiểu replace pod được K8S triển khai đó là:
- Recreate: dừng toàn bộ pod cũ rồi bắt đầu start các pod mới
- Rolling Update: Start các pod mới và dừng pod cũ cùng lúc, điều khiển bằng việc khống chế số pod hoạt động tối thiểu (
maxUnavailable) và số pod mới tối đa (maxSurge). Chi tiết hơn về 2 thông số này ở đây
Ở đây để đạt được zero-downtime, chúng ta sẽ áp dụng cơ chế Rolling update. Như vậy K8S sẽ start các pod mới lên để nhận request mới, đồng thời ngắt các pod cũ cùng lúc đó. Cơ chế này được áp dụng mặc định. Tham khảo thêm tại đây
Tuy nhiên hãy nhìn 1 cách kỹ càng hơn vào lifecycle của 1 pod:
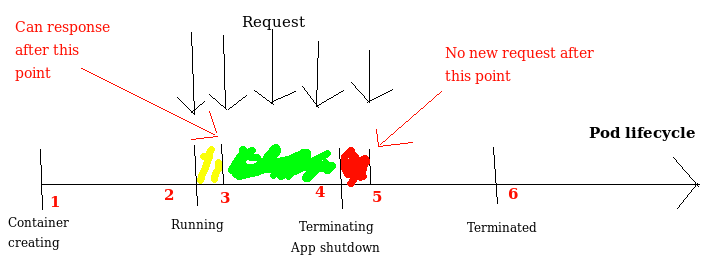
Hình trên biểu thị 4 trạng thái hoạt động bình thường bao gồm Container Creating, Running, Terminating, Terminated của 1 pod. Trên lý thuyết thì request sẽ được routing tới pod xử lý trong quãng thời gian từ điểm số 2 tới điểm số 4. Để giữ cho không có request nào bị lỗi thì ứng dụng cần có khả năng xử lý request ở điểm số 2, và dừng nhận request từ điểm số 4. Tuy nhiên trên thực tế, ứng dụng của chúng ta sẽ:
- App mất thời gian khởi động. Do vậy thời điểm ứng dụng có khả năng xử lý request bị lùi từ số 2 xuống điểm số 3
- Update routing trên k8s. Với các kiểu service được expose ra ngoài qua nodeport hay ingress, K8S và ingress controller sẽ mất thời gian để update routing, trong khi app đã nhận được signal dừng xử lý từ điểm số 4 Phần này mình chỉ note lại kết quả cho các bạn, còn cơ chế bên trong vì sao lại mất thời gian thì không đủ thời gian để nói ở đây. Do vậy điểm pod dừng nhận request bị đẩy từ điểm 4 (bắt đầu trạng thái Terminating) xuống điểm 5
Từ những nguyên nhân trên dẫn tới 2 khoảng thời gian đỏ và vàng nếu có request tới pod sẽ bị lỗi. Điều này ảnh hưởng tới quá trình dừng pod cũ (phần đỏ) và sử dụng pod mới (phần vàng).
Cách giải quyết
Ta sẽ giải quyết từng quá trình một. Đầu tiên là với phần vàng.
Readiness check
Để giải quyết bài toán Ứng dụng cần thời gian để khởi động, K8S cung cấp cho chúng ta 1 công cụ gọi là Readiness probe. Đây thực chất là 1 cấu hình test. Theo đó K8S sẽ thực hiện kiểm tra Readiness probe định kỳ để check xem ứng dùng đã thật sự sẵn sàng để xử lý request hay chưa, từ đó mới điều hưởng request tới pod.
Để cấu hình Readiness probe chúng ta thêm đoạn manifest sau:
1 2 3 4 5 6 7 8 9 10 11 12 | <span class="token punctuation">...</span> <span class="token key atrule">containers</span><span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span><span class="token punctuation">:</span> gcr.io/google<span class="token punctuation">-</span>samples/hello<span class="token punctuation">-</span>app<span class="token punctuation">:</span><span class="token number">2.0</span> <span class="token key atrule">readinessProbe</span><span class="token punctuation">:</span> <span class="token key atrule">httpGet</span><span class="token punctuation">:</span> <span class="token key atrule">path</span><span class="token punctuation">:</span> / <span class="token key atrule">port</span><span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">initialDelaySeconds</span><span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">periodSeconds</span><span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">successThreshold</span><span class="token punctuation">:</span> <span class="token number">1</span> <span class="token punctuation">...</span> |
Config ở trên báo cho K8S chạy kiểm tra bằng cách thực hiện 1 request http
GET /tới container trên cổng 8080. Interval là 5 giây. Thời gian chờ khởi động 5 giây. Số lần thành công để tính là ready: 1
Bằng việc check Readiness probe, chúng ta đã delay việc forward request tới pod cho tới khi ứng dụng sẵn sàng (điểm số 3)
Prestop hook
Để giải quyết vấn đề update routing trên K8S cần thời gian, chúng ta sẽ can thiệp vào 1 lifecycle hook của K8S tên là preStop. Prestop hook được gọi theo kiểu synchorous trước khi gửi tín hiệu shutdown tới pod. Việc của preStop hook này đơn giản chỉ là chờ một lát để load balancer ngừng forward request tới pod trước khi shutdown app
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <span class="token punctuation">...</span> <span class="token key atrule">containers</span><span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span><span class="token punctuation">:</span> gcr.io/google<span class="token punctuation">-</span>samples/hello<span class="token punctuation">-</span>app<span class="token punctuation">:</span><span class="token number">2.0</span> <span class="token key atrule">readinessProbe</span><span class="token punctuation">:</span> <span class="token key atrule">httpGet</span><span class="token punctuation">:</span> <span class="token key atrule">path</span><span class="token punctuation">:</span> / <span class="token key atrule">port</span><span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">initialDelaySeconds</span><span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">periodSeconds</span><span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">successThreshold</span><span class="token punctuation">:</span> <span class="token number">1</span> <span class="token key atrule">lifecycle</span><span class="token punctuation">:</span> <span class="token key atrule">preStop</span><span class="token punctuation">:</span> <span class="token key atrule">exec</span><span class="token punctuation">:</span> <span class="token key atrule">command</span><span class="token punctuation">:</span> <span class="token punctuation">[</span><span class="token string">"/bin/bash"</span><span class="token punctuation">,</span> <span class="token string">"-c"</span><span class="token punctuation">,</span> <span class="token string">"sleep 15"</span><span class="token punctuation">]</span> <span class="token punctuation">...</span> |
Cấu hình preStop phía trên đơn giản chỉ là chạy 1 lệnh bash chờ 15s rồi gửi shutdown signal tới app.
Thành quả
Đây là sơ đồ lifecycle của pod sau khi chúng ta đã thêm readliness probe và lifecycle. Chúng ta có thể thấy việc shutdown app từ điểm số 5 được đẩy lùi xuống số 7. Do vậy request đẩy vào pod trong khoảng thời gian update routing (số 4 -> 5) vẫn được xử lý hoàn chỉnh. Ngoài ra readiness probe cũng thông báo cho K8S đẩy request mới vào pod từ điểm số 3.

Hãy cùng thay đổi version app và theo dõi fortio nhé:
1 2 3 4 | $ kubectl apply -f hello-app.yaml deployment.apps/hello-app configured service/hello-app unchanged |
1 2 3 4 5 6 7 8 | $ fortio load -qps 100 -t 60s <span class="token string">"http://157.230.xxx.yyy:30001/"</span> <span class="token punctuation">..</span>. Sockets used: 8 <span class="token punctuation">(</span>for perfect keepalive, would be 4<span class="token punctuation">)</span> Code 200 <span class="token keyword">:</span> 4833 <span class="token punctuation">(</span>100.0 %<span class="token punctuation">)</span> Response Header Sizes <span class="token keyword">:</span> count 4833 avg 117 +/- 0 min 117 max 117 <span class="token function">sum</span> 565461 Response Body/Total Sizes <span class="token keyword">:</span> count 4833 avg 183 +/- 0 min 183 max 183 <span class="token function">sum</span> 884439 All <span class="token keyword">done</span> 4833 calls <span class="token punctuation">(</span>plus 4 warmup<span class="token punctuation">)</span> 49.618 ms avg, 80.5 qps |
All done, zero-downtime.
Kết luận
Vậy là mình đã show cho các bạn 2 vấn đề thực tế mình đã xử lý khi triển khai ứng dụng trên K8S để đảm bảo zero-downtime khi rolling update ứng dụng của bạn.
- Xử lý readiness probe
- Cấu hình preStop hook
Hy vọng các bạn sẽ thu thập dc kinh nghiệm gì đó từ bài viết này để áp dụng cho công việc của mình. Nếu các bạn còn hứng thú với các vấn đề khó hơn như các kết nối persistent, sticky session,… khi xử lý zero-downtime thì hãy comment ủng hộ để mình có động lực viết thêm nhé.
Xin cảm ơn.