Hello mn another month passed =))), today I will share about handle with Missing data in data analysis. As people have been working with real data, the missing data problem is quite common, so solving the missing value problem is necessary to help our problem be improved. significantly more. In this article I will present some ways to solve this problem.
Types of missing data
To solve this problem, we must also understand the missing value type of the data we have. There are three types of missing data that are presented below:
Missing at Random – Randomly missing data
The data loss here is random, but there is still a systematic relationship between lost data and observed data. For example, in Figure 1 young people have IQ data deficiencies, which means that there is a systematic relationship between the IQ variable and the age variable.
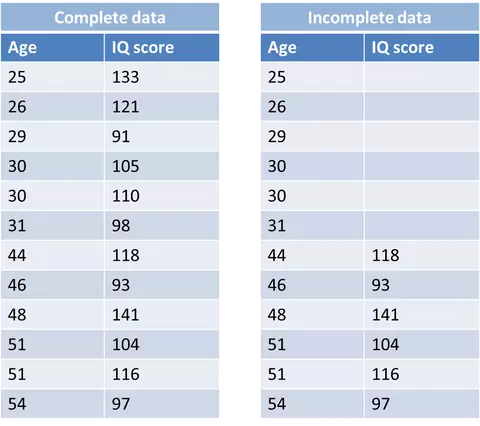
Figure 1: Example of MAR
Missing Completely at Random – Missing data is completely random
As its name says it all. The data loss here is completely random, and there is no relationship or relationship between the data and any data, missing or observed data. In the example below we will never find a relationship between the missing value and the preserved value.
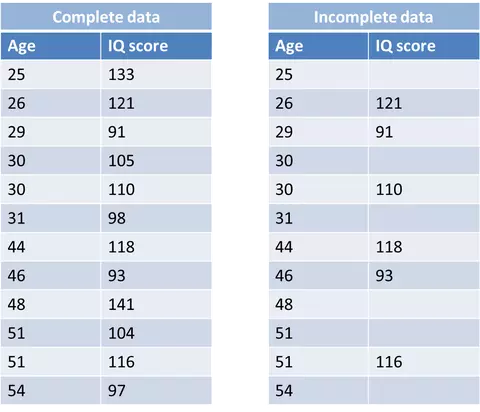
Figure 2: MCAR example
Missing Not at Random – The missing data is not random
MNAR: The data loss is not accidental but there is a trend relationship between missing value and non-missing value in a variable. For example, in Figure 3 – people with low IQ are missing and high IQ is not missing, meaning that there is a relationship between the missing and non-missing values in the IQ variable itself.
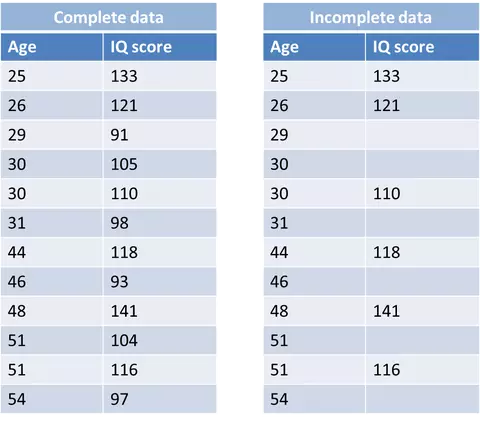
Figure 3: Example of MNAR
How to solve missing problems
Search for missing data in dataset
We can see many missing data types appear: it can be a bellow string, it can be NA, N / A, Non, -1, 99 or 999. The best way to solve mising values is you. be clear about what data you have: Understand how missing data is being represented, how data is collected, in which field the missing data is, etc.
We can eliminate missing data when we realize completely random data missing (MCAR). However, with MAR and MNAR, the elimination will affect the accuracy of the model better than we should find ways to handle this problem.
Determine the missing value in data
Specifically, here I will use the titanic dataset, first I will see how many variables are missing for this data set. First, import the input:
1 2 3 4 | import pandas as pd import matplotlib.pyplot as plt import seaborn as sns |
1 2 3 4 5 6 7 8 | # Load Data train = pd.read_csv('data/train.csv') test = pd.read_csv('data/test.csv') # Concatenate train & test train_objs_num = len(train) y = train['Survived'] dataset = pd.concat(objs=[train.drop(columns=['Survived']), test], axis=0) |
Use the dataframe.info () command to check for missing data:
1 2 | dataset.info() |
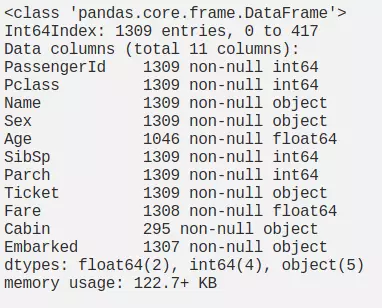
Figure 4: Data overview
Based on Figure 4 we can see the features: Age, Fare, Cabin, Embarked containing missing values. Next we show the percentage of missing data by feature like:
1 2 3 4 5 6 7 8 9 10 11 | total = dataset.isnull().sum().sort_values(ascending=False) percent = (dataset.isnull().sum()/dataset.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) f, ax = plt.subplots(figsize=(15, 6)) plt.xticks(rotation='90') sns.barplot(x=missing_data.index, y=missing_data['Percent']) plt.xlabel('Features', fontsize=15) plt.ylabel('Percent of missing values', fontsize=15) plt.title('Percent missing data by feature', fontsize=15) missing_data.head() |
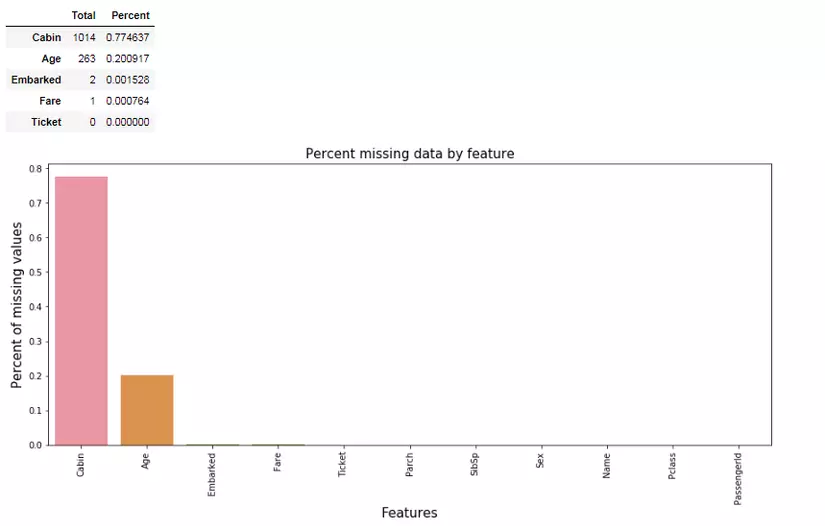
Figure 5: missing data rate by feature
Removing Data
Listwise deletion
If the missing data in the dataset is MCAR and the number of missing values is not much, we will delete those missing values. As shown in Figure 1: the missing values in the IQ score variable corresponding to the Age variable (age: 25, 30, 31, 48, 51, 54) we will drop it off. Or with the titanic dataset above features: Embarked and Fare are missing very little data, I will remove these values by executing the following command
1 2 | data = dataset.dropna(subset=['Fare', 'Embarked']) |
When you want to eliminate missing values in all fields you use this command:
1 2 | dataset.dropna(how='all',inplace=True) |
Or when you just want to remove missing data streams from at least 2 or more features:
1 2 | dataset.dropna(thresh=2,inplace=True) |
Dropping variable
A lot of cases occur when data is missing, if in the case of a variable with multiple values missing and we can judge that the missing variable really doesn’t matter if it doesn’t appear in the data, then they We can delete that variable as well. Normally, when the data of a variable is about 60 ~ 70% missing, we should consider removing that variable completely.
With the above data set, I can eliminate all missing variables by executing the following command, but this will cause us to lose a lot of useful data.
1 2 | dataset.dropna(axis=1,inplace=True) |
Data Imputation
Replace the missing data with the values: -1, -99, -999
With the continuous features, the fact that we replace missing values with -1, -99, -999, … will help tree models like (RF – Random Forest) work well. rather than replacing with the above values, these models can explain the lack of data through this encoding. Its disadvantages that solve the performance of linear model will be affected.
1 2 | dataset.Fare.fillna(-99,inplace=True) |
Replace with mean, midian, mode values
With this method we fill in the missing values with the ** mean ** or median values of some variables if the variable is continuous and enter the mode if the variable is categorical. Although this method is fast, it reduces the variance of data. Besides, when doing this way, it is suitable for simple linear model and NN. But for tree- based problems, it doesn’t seem right.
1 2 | dataset.Age.fillna(dataset.Age.mean(),inplace=True) |
or:
1 2 | dataset.Age.fillna(dataset.Age.median(),inplace=True) |
Or with categorical variables we use mode :
1 2 | dataset.Cabin.fillna(dataset.Cabin.mode()[0],inplace=True) |
Use prediction model for data impution
Here we can use K-NN, Linear-Regression to predict missing values:
1 2 3 4 5 6 7 8 9 10 11 12 13 | from sklearn.linear_model import LinearRegression linreg = LinearRegression() train = pd.read_csv("train.csv") data = train[['Pclass','SibSp','Parch','Fare','Age']] x_train = data[data['Age'].notnull()].drop(columns='Age') y_train = data[data['Age'].notnull()]['Age'] x_test = data[data['Age'].isnull()].drop(columns='Age') y_test = data[data['Age'].isnull()]['Age'] linreg.fit(x_train, y_train) predicted = linreg.predict(x_test) train.Age[train.Age.isnull()] = predicted train.info() |
Or with KNN we use the sklearn library:
1 2 3 4 5 6 7 | import numpy as np from sklearn.impute import KNNImputer imputer = KNNImputer(n_neighbors=5) imputer.fit(train.select_dtypes('float64')) cols_float = list(train.select_dtypes('float64').columns) train[cols_float] = imputer.transform(train.select_dtypes('float64')) |
The results after implementation are: 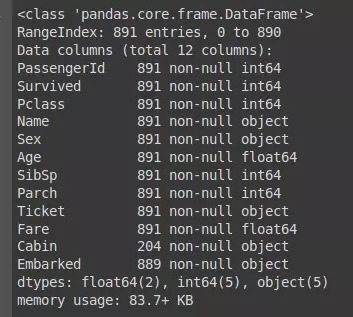
With categorical data here, I will fill the missing value using the above methods.
Conclude
Thanks for everyone who has read your article. Hopefully this article will be helpful for everyone in pre-processing data. If there is anything incorrect or missing articles hope to receive your comments and additional.
Reference
https://www.iriseekhout.com/missing-data/missing-data-mechanisms/mcar/
https://medium.com/@danberdov/dealing-with-missing-data-8b71cd819501
https://medium.com/@george.drakos62/handling-missing-values-in-machine-learning-part-1-dda69d4f88ca