Mục tiêu bài viết
Phân tích câu hỏi là pha đầu tiên trong kiến trúc chung của một hệ thống hỏi đáp, có nhiệm vụ tìm ra các thông tin cần thiết làm đầu vào cho quá trình xử lý của các pha sau (trích chọn tài liệu, trích xuất câu trả lời, …). Vì vậy phân tích câu hỏi có vai trò hết sức quan trọng, ảnh hưởng trực tiếp đến hoạt động của toàn bộ hệ thống. Nếu phân tích câu hỏi không tốt thì sẽ không thể tìm ra được câu trả lời.
Hôm nay mình sẽ trình bày về các phương pháp phân loại ý định của người hỏi trong hệ thống hỏi đáp dựa trên tập dữ liệu là các câu hỏi của sinh viên trường Đại học Xây dựng. Trong quá trình xây dựng mình đã thử nghiệm nhiều phương pháp khác nhau, tuy nhiên với phạm vi blog này mình sẽ chia sẻ một phương pháp tốt nhất mà mình đã sử dụng, các phương pháp khác mình sẽ chia sẻ dần trong các bài viết tiếp theo.
Xác định ý định là gì?
Đối với hệ thống hỏi đáp, phân loại ý định (intent classification) là việc xác định ý định của người hỏi khi tương tác với hệ thống thông qua câu hỏi hay câu truy vấn của người dùng.
Ví dụ đối với câu hỏi: “Cho mình hỏi địa chỉ cơ sở A ở đâu ạ?”, thì ý định của người dùng là họ đang muốn hỏi về ‘ADDRESS’, ví dụ khác như câu hỏi : “Thời gian mở cửa của cửa hàng là mấy giờ?” thì ý định của người dùng là hỏi về ‘TIME’.
Dựa vào việc xác định ý định sẽ giúp việc trả lời câu hỏi được chính xác và đưa ra được câu trả lời mong muốn của người dùng.
Các phương pháp xác định ý định
Đối với các bài toán cần xác định ý định, có nhiều phương pháp để thực hiện.
Hướng tiếp cận nông (shalow)
Phương pháp cổ điển là dựa trên tần suất xuất hiện và mức độ quan trọng các từ trong các ý định đã biết hay còn gọi là hướng tiếp cận nông. Ví dụ để hỏi về thời gian thì trong câu hỏi sẽ hay xuất hiện các từ như “mấy giờ”, “ngày nào”, “tháng nào”, “năm nào”,…
Còn ý định muốn hỏi về địa điểm thì sẽ có các từ: “ở đâu”, “địa chỉ”, “chỗ nào”,..v.v.
Nhiều phương pháp sử dụng trong Q&A dùng các kĩ thuật dựa trên từ khóa để định vị các câu, đọan văn có khả năng chứa câu trả lời từ các văn bản được trích chọn về. Sau đó giữ lại các câu, đoạn văn có chứa chuỗi ký tự cùng loại với loại câu trả lời mong muốn (ví dụ các câu hỏi về tên người, địa danh, số lượng…).
Khi xác định được các từ hay xuất hiện trong các ý định thì tùy vào xác suất xuất hiện của các từ trong câu hỏi mà chúng ta sẽ dự đoán được khả năng ý định của người dùng sẽ thuộc vào loại nào.
Tuy nhiên việc xác định dựa trên từ điển như vậy sẽ không đầy đủ và thiếu chính xác. Ngôn ngữ tự nhiên là ngôn ngữ có tính nhập nhằng, vì vậy nên một số câu hỏi nếu dựa vào những từ như vậy chưa chắc đã xác định được ý định câu hỏi.
Hướng tiếp cận sâu (deep)
Trong những trường hợp khi mà hướng tiếp cận bề mặt
không thể tìm ra câu trả lời, những quá trình xử lý về ngữ pháp, ngữ nghĩa và ngữ cảnh là cần thiết để trích xuất hoặc tạo ra câu trả lời. Các kĩ thuật thường dùng như nhận dạng thực thể (named-entity recognition), trích xuất mối quan hệ, loại bỏ nhập nhằng ngữ nghĩa,… Hệ thống thường sử dụng các nguồn tri thức như Wordnet, ontology để làm giàu thêm khả năng lập luận thông qua các định nghĩa và mối liên hệ ngữ nghĩa. Các hệ thống hỏi đáp dựa theo mô hình ngôn ngữ thống kê cũng đang ngày càng phổ biến.
Trong bài viết này mình sẽ tiếp cận theo hướng tiếp cận sâu.
Dữ liệu sử dụng
Để xây dựng mô hình xác định ý định câu hỏi, mình sẽ sử dụng ontology là các cặp “câu hỏi – ý định” được thu thập từ sinh viên trường Đại học Xây dựng.
Mình sẽ đưa bài toán về việc xây dựng một mô hình phân lớp với các class là các ý định của người hỏi. Ví dụ sau đây là các câu hỏi trong tập dữ liệu:
1 2 3 4 5 6 7 8 9 10 11 | {'content': 'thưa thầy cô, bảng điểm của em hiện tại giờ được 1 môn C+ 2 tín chỉ, 2 môn ghi F là em bảo lưu ạ, nhưng điểm hệ số 4 của em lại ghi 0.45 là như nào ạ, mong các thầy cô giải đáp hộ em', 'intent': 'DIEM'} {'content': 'với tiêu chí xét học bổng năm 2 là bắt buộc qua tacb1,2 hay phải đạt 250 toeic ạ ', 'intent': 'HOC_BONG'} {'content': 'Em chào thầy cô ạ. Em xin được có một vài lời về vấn đề học bổng của nhà trường ạ. Trước tiên em xin chân thành cảm ơn quý thầy cô và nhà trường đã tạo điều kiện cho em cũng như các anh chị, các bạn sinh viên được học tập và thêm vào đó là những suất học bổng những phần quà để động viên tinh thần học tập của sinh viên chúng em. Theo em được biết thì trong khoảng thời gian trước thời điểm hiện tại thì nhà trường đã tiến hành trao học bổng cho sinh viên trong diện được xét học bổng của kì học trước. Một vài bạn trong lớp em đã nhận được học bổng nhưng riêng về cá nhân em thì em vẫn chưa nhận được học bổng ạ. Em không rõ là do có sai sót gì không nên em rất mong nhà trường xem xét lại và cho em lời đáp ạ. Những lời em nói ở trên nếu có chỗ nào không phù hợp thì cho em xin lỗi ạ. Em rất mong nhận được hồi âm ạ. Em xin chân thành cảm ơn ạ!', 'intent': 'HOC_BONG'} {'content': 'Trong khoảng thời gian chờ bằng, em có được phép đăng ký học lại môn học để nâng điểm tích lũy hay không?', 'intent': 'DKMH'} {'content': 'Em đã bảo vệ đồ án tốt nghiệp thì có thể học lại để cải thiện điểm các môn không ạ', 'intent': 'DKMH'} {'content': 'Em muốn xin hoãn xét tốt nghiệp để học cải thiện thì có được không ạ, và làm cách nào để đăng ký môn học ạ', 'intent': 'DKMH'} {'content': 'Thưa thầy, em học khóa 62 em có thể học lại môn cơ học đất khóa 64 được không ạ. Vì em thấy mã môn học khác nhau (138802, 130211)', 'intent': 'DKMH'} {'content': 'Cho em hỏi em có thể đăng ký trả nợ môn học cùng tên nhưng khác mã được không ạ?', 'intent': 'DKMH'} {'content': 'Em chào cô. Cô cho emxa0hỏixa0lâu nữa không sẽ có đợt huỷ môn học mà mình đăng kí nhầm vậy cô. Em cảm ơn cô nhiều.', 'intent': 'DKMH'} {'content': 'Cho em hỏi nếu em đăng ký môn học mà bị nhầm thì có hủy được không ạ', 'intent': 'DKMH'} |
Các câu hỏi được chia thành 10 nhóm ý định: ['DIEM', 'HOC_BONG', 'DKMH', 'HOC_PHI', 'KHAC', 'LICH_HOC', 'TAI_KHOAN', 'THU_TUC_SV', 'TN', 'TOEIC']
Trong đó
- ‘DIEM’ bao gồm các câu hỏi thắc mắc về Điểm
- ‘HOC_BONG’ bao gồm các câu hỏi thắc mắc về Học bổng
- ‘DKMH’ bao gồm các câu hỏi thắc mắc về việc đăng ký môn học
- ‘HOC_PHI’ bao gồm các câu hỏi thắc mắc về học phí
…
- ‘KHAC’ bao gồm các câu hỏi không thuộc vào 1 trong 9 nhóm trên
Xây dựng mô hình
Tài nguyên
Dữ liệu, pre-trained các mô hình biểu diễn từ các bạn có thể download ở đây.
Cài đặt các gói cần thiết
Trong bài này mình sử dụng thư viện pyvi để tiến hành một số tiền xử lý với văn bản. Để cài đặt bạn chạy lệnh sau:
1 2 | pip3 <span class="token function">install</span> pyvi |
Import các thư viện cần thiết
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <span class="token comment"># -*- coding: utf-8 -*-</span> <span class="token keyword">import</span> pandas <span class="token keyword">as</span> pd <span class="token keyword">import</span> string <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np <span class="token keyword">import</span> re<span class="token punctuation">,</span> os<span class="token punctuation">,</span> string <span class="token keyword">from</span> pyvi <span class="token keyword">import</span> ViTokenizer <span class="token keyword">from</span> pyvi<span class="token punctuation">.</span>ViTokenizer <span class="token keyword">import</span> tokenize <span class="token keyword">import</span> tensorflow <span class="token keyword">as</span> tf <span class="token keyword">from</span> gensim<span class="token punctuation">.</span>models<span class="token punctuation">.</span>fasttext <span class="token keyword">import</span> FastText <span class="token keyword">import</span> json <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>preprocessing <span class="token keyword">import</span> MinMaxScaler <span class="token keyword">from</span> tensorflow<span class="token punctuation">.</span>keras <span class="token keyword">import</span> <span class="token operator">*</span> <span class="token keyword">from</span> tensorflow<span class="token punctuation">.</span>keras<span class="token punctuation">.</span>layers <span class="token keyword">import</span> <span class="token operator">*</span> <span class="token keyword">from</span> tensorflow<span class="token punctuation">.</span>keras<span class="token punctuation">.</span>utils <span class="token keyword">import</span> to_categorical <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>model_selection <span class="token keyword">import</span> <span class="token operator">*</span> <span class="token keyword">import</span> matplotlib<span class="token punctuation">.</span>pyplot <span class="token keyword">as</span> plt<span class="token punctuation">;</span> plt<span class="token punctuation">.</span>rcdefaults<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">import</span> matplotlib<span class="token punctuation">.</span>pyplot <span class="token keyword">as</span> plt |
Khai báo các hàm tiền xử lý
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | <span class="token comment"># Loại bỏ các ký tự thừa</span> <span class="token keyword">def</span> <span class="token function">clean_text</span><span class="token punctuation">(</span>text<span class="token punctuation">)</span><span class="token punctuation">:</span> text <span class="token operator">=</span> re<span class="token punctuation">.</span>sub<span class="token punctuation">(</span><span class="token string">'<.*?>'</span><span class="token punctuation">,</span> <span class="token string">''</span><span class="token punctuation">,</span> text<span class="token punctuation">)</span><span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token punctuation">)</span> text <span class="token operator">=</span> re<span class="token punctuation">.</span>sub<span class="token punctuation">(</span><span class="token string">'(s)+'</span><span class="token punctuation">,</span> <span class="token string">r'1'</span><span class="token punctuation">,</span> text<span class="token punctuation">)</span> <span class="token keyword">return</span> text <span class="token comment">#tách câu</span> <span class="token keyword">def</span> <span class="token function">sentence_segment</span><span class="token punctuation">(</span>text<span class="token punctuation">)</span><span class="token punctuation">:</span> sents <span class="token operator">=</span> re<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token string">"([.?!])?[n]+|[.?!] "</span><span class="token punctuation">,</span> text<span class="token punctuation">)</span> <span class="token keyword">return</span> sents <span class="token comment">#tách từ</span> <span class="token keyword">def</span> <span class="token function">word_segment</span><span class="token punctuation">(</span>sent<span class="token punctuation">)</span><span class="token punctuation">:</span> sent <span class="token operator">=</span> tokenize<span class="token punctuation">(</span>sent<span class="token punctuation">)</span> <span class="token keyword">return</span> sent <span class="token comment">#Chuẩn hóa từ</span> <span class="token keyword">def</span> <span class="token function">normalize_text</span><span class="token punctuation">(</span>text<span class="token punctuation">)</span><span class="token punctuation">:</span> listpunctuation <span class="token operator">=</span> string<span class="token punctuation">.</span>punctuation<span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">'_'</span><span class="token punctuation">,</span> <span class="token string">''</span><span class="token punctuation">)</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> listpunctuation<span class="token punctuation">:</span> text <span class="token operator">=</span> text<span class="token punctuation">.</span>replace<span class="token punctuation">(</span>i<span class="token punctuation">,</span> <span class="token string">' '</span><span class="token punctuation">)</span> <span class="token keyword">return</span> text<span class="token punctuation">.</span>lower<span class="token punctuation">(</span><span class="token punctuation">)</span> |
Để loại bỏ từ dừng, mình dùng danh sách từ dừng, các bạn thay stopwords.csv bằng đường dẫn trong file mình để bên trên.
1 2 3 4 5 6 7 8 9 10 11 12 | filename <span class="token operator">=</span> <span class="token string">'stopwords.csv'</span> data <span class="token operator">=</span> pd<span class="token punctuation">.</span>read_csv<span class="token punctuation">(</span>filename<span class="token punctuation">,</span> sep<span class="token operator">=</span><span class="token string">"t"</span><span class="token punctuation">,</span> encoding<span class="token operator">=</span><span class="token string">'utf-8'</span><span class="token punctuation">)</span> list_stopwords <span class="token operator">=</span> data<span class="token punctuation">[</span><span class="token string">'stopwords'</span><span class="token punctuation">]</span> <span class="token keyword">def</span> <span class="token function">remove_stopword</span><span class="token punctuation">(</span>text<span class="token punctuation">)</span><span class="token punctuation">:</span> pre_text <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> words <span class="token operator">=</span> text<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">for</span> word <span class="token keyword">in</span> words<span class="token punctuation">:</span> <span class="token keyword">if</span> word <span class="token keyword">not</span> <span class="token keyword">in</span> list_stopwords<span class="token punctuation">:</span> pre_text<span class="token punctuation">.</span>append<span class="token punctuation">(</span>word<span class="token punctuation">)</span> text2 <span class="token operator">=</span> <span class="token string">' '</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span>pre_text<span class="token punctuation">)</span> <span class="token keyword">return</span> text2 |
Huấn luyện mô hình FastText phù hợp với dữ liệu bài toán
Trong bài này mình sử dụng FastText trong gói thư viện của Gensim để thực hiện mã hóa các từ thành vector (word2vec). Dữ liêu huấn luyện mình để trong file xaa.
FastText được đánh giá là tốt hơn so với word2vec trong việc biểu diễn các từ mới nên mình sẽ sử dụng trong bài toán này.
Đây là file gồm 1 phần các bài viết từ wikipedia tiếng việt, các văn bản đã được tiền xử lý bằng một số
kỹ thuật như tách từ, loại bỏ từ dừng, chuẩn hóa…
Ngoài ra mình cũng cần bổ sung các câu trong file dữ liệu của bộ dữ liệu phân loại ý định để huấn luyện cho mô hình word2vec.
Điều này giúp bổ sung một số từ trong miền dữ liệu của topology mà trong bộ ngữ liệu của wikipedia không có. Điều này giúp mô hình FastText có khả năng biểu diễn đầy đủ hơn.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | <span class="token keyword">import</span> json wiki_data_path <span class="token operator">=</span> <span class="token string">'xaa'</span> qa_data_path <span class="token operator">=</span> <span class="token string">'intent_db_v2.json'</span> <span class="token keyword">def</span> <span class="token function">read_data</span><span class="token punctuation">(</span>path<span class="token punctuation">)</span><span class="token punctuation">:</span> traindata <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> sents <span class="token operator">=</span> <span class="token builtin">open</span><span class="token punctuation">(</span>pathdata<span class="token punctuation">,</span> <span class="token string">'r'</span><span class="token punctuation">)</span><span class="token punctuation">.</span>readlines<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">for</span> sent <span class="token keyword">in</span> sents<span class="token punctuation">:</span> traindata<span class="token punctuation">.</span>append<span class="token punctuation">(</span>sent<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">with</span> <span class="token builtin">open</span><span class="token punctuation">(</span>qa_data_path<span class="token punctuation">)</span> <span class="token keyword">as</span> json_file<span class="token punctuation">:</span> qa_data <span class="token operator">=</span> json<span class="token punctuation">.</span>load<span class="token punctuation">(</span>json_file<span class="token punctuation">)</span> <span class="token keyword">for</span> question <span class="token keyword">in</span> qa_data<span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'content'</span> <span class="token keyword">in</span> question <span class="token punctuation">:</span> content <span class="token operator">=</span> clean_text<span class="token punctuation">(</span>question<span class="token punctuation">[</span><span class="token string">'content'</span><span class="token punctuation">]</span><span class="token punctuation">)</span> content <span class="token operator">=</span> word_segment<span class="token punctuation">(</span>content<span class="token punctuation">)</span> content <span class="token operator">=</span> remove_stopword<span class="token punctuation">(</span>normalize_text<span class="token punctuation">(</span>content<span class="token punctuation">)</span><span class="token punctuation">)</span> traindata<span class="token punctuation">.</span>append<span class="token punctuation">(</span>content<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Corpus loaded"</span><span class="token punctuation">)</span> <span class="token keyword">return</span> traindata<span class="token punctuation">,</span> qa_data train_data<span class="token punctuation">,</span> qa_data <span class="token operator">=</span> read_data<span class="token punctuation">(</span>wiki_data_path<span class="token punctuation">)</span> |
Huấn luyện mô hình FastText như sau:
1 2 3 4 | model_fasttext <span class="token operator">=</span> FastText<span class="token punctuation">(</span>size<span class="token operator">=</span><span class="token number">150</span><span class="token punctuation">,</span> window<span class="token operator">=</span><span class="token number">10</span><span class="token punctuation">,</span> min_count<span class="token operator">=</span><span class="token number">2</span><span class="token punctuation">,</span> workers<span class="token operator">=</span><span class="token number">4</span><span class="token punctuation">,</span> sg<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span> model_fasttext<span class="token punctuation">.</span>build_vocab<span class="token punctuation">(</span>train_data<span class="token punctuation">)</span> model_fasttext<span class="token punctuation">.</span>train<span class="token punctuation">(</span>train_data<span class="token punctuation">,</span> total_examples<span class="token operator">=</span>model_fasttext<span class="token punctuation">.</span>corpus_count<span class="token punctuation">,</span> epochs<span class="token operator">=</span>model_fasttext<span class="token punctuation">.</span><span class="token builtin">iter</span><span class="token punctuation">)</span> |
Sau khi đã huấn luyện xong các bạn cần lưu lại model để sử dụng cho lần sau bằng đoạn code sau:
1 2 | model_fasttext<span class="token punctuation">.</span>wv<span class="token punctuation">.</span>save<span class="token punctuation">(</span><span class="token string">"fasttext_gensim.model"</span><span class="token punctuation">)</span> |
Để loại lại mô hình chúng ta làm như sau:
1 2 | fast_text_model <span class="token operator">=</span> KeyedVectors<span class="token punctuation">.</span>load<span class="token punctuation">(</span><span class="token string">'/content/drive/MyDrive/NUCE/NLP/QA/model/fasttext_gensim.model'</span><span class="token punctuation">)</span> |
In thử kích thước một từ:
1 2 3 | input_text <span class="token operator">=</span> fast_text_model<span class="token punctuation">.</span>wv<span class="token punctuation">.</span>get_vector<span class="token punctuation">(</span><span class="token string">"hôm_nay"</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>input_text<span class="token punctuation">.</span>shape<span class="token punctuation">)</span> |
1 2 | (150,) |
Biểu diễn từ và biểu diễn câu
Sau khi đã huấn luyện mô hình FastText, chúng ta sẽ tiến hành mã hóa các câu thành vector bằng cách mã hóa từng từ trong câu và đưa các vector biểu diễn các từ này vào một vector có kích thước bằng số từ của câu dài nhất (để đảm bảo các câu đều được biểu diễn đầy đủ).
Các câu ngắn hơn độ dài của câu dài nhất sẽ được thêm padding là các số 0 để đưa các câu về cùng kích thước mà không ảnh hưởng đến ý nghĩa của câu. Việc padding mình sử dụng hàm tf.keras.preprocessing.sequence.pad_sequences
Code thực hiện như sau:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | max_length_inp <span class="token operator">=</span> <span class="token number">30</span> <span class="token keyword">def</span> <span class="token function">sentence_embedding</span><span class="token punctuation">(</span>sent<span class="token punctuation">)</span><span class="token punctuation">:</span> content <span class="token operator">=</span> clean_text<span class="token punctuation">(</span>sent<span class="token punctuation">)</span> content <span class="token operator">=</span> word_segment<span class="token punctuation">(</span>content<span class="token punctuation">)</span> content <span class="token operator">=</span> remove_stopword<span class="token punctuation">(</span>normalize_text<span class="token punctuation">(</span>content<span class="token punctuation">)</span><span class="token punctuation">)</span> inputs <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token keyword">for</span> word <span class="token keyword">in</span> content<span class="token punctuation">.</span>split<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> word <span class="token keyword">in</span> fast_text_model<span class="token punctuation">.</span>wv<span class="token punctuation">.</span>vocab<span class="token punctuation">:</span> inputs<span class="token punctuation">.</span>append<span class="token punctuation">(</span>fast_text_model<span class="token punctuation">.</span>wv<span class="token punctuation">.</span>get_vector<span class="token punctuation">(</span>word<span class="token punctuation">)</span><span class="token punctuation">)</span> inputs <span class="token operator">=</span> tf<span class="token punctuation">.</span>keras<span class="token punctuation">.</span>preprocessing<span class="token punctuation">.</span>sequence<span class="token punctuation">.</span>pad_sequences<span class="token punctuation">(</span><span class="token punctuation">[</span>inputs<span class="token punctuation">]</span><span class="token punctuation">,</span> maxlen<span class="token operator">=</span>max_length_inp<span class="token punctuation">,</span> dtype<span class="token operator">=</span><span class="token string">'float32'</span><span class="token punctuation">,</span> padding<span class="token operator">=</span><span class="token string">'post'</span><span class="token punctuation">)</span> <span class="token keyword">return</span> inputs |
Đọc dữ liệu
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <span class="token keyword">import</span> json <span class="token keyword">def</span> <span class="token function">read_data</span><span class="token punctuation">(</span>qa_data_input<span class="token punctuation">)</span><span class="token punctuation">:</span> sentences <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> labels <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> intents <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token keyword">for</span> question <span class="token keyword">in</span> qa_data<span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'intent'</span> <span class="token keyword">in</span> question<span class="token punctuation">:</span> <span class="token keyword">if</span> question<span class="token punctuation">[</span><span class="token string">'intent'</span><span class="token punctuation">]</span> <span class="token keyword">not</span> <span class="token keyword">in</span> intents<span class="token punctuation">:</span> intents<span class="token punctuation">.</span>append<span class="token punctuation">(</span>question<span class="token punctuation">[</span><span class="token string">'intent'</span><span class="token punctuation">]</span><span class="token punctuation">)</span> sentences<span class="token punctuation">.</span>append<span class="token punctuation">(</span>sentence_embedding<span class="token punctuation">(</span>question<span class="token punctuation">[</span><span class="token string">'content'</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span> labels<span class="token punctuation">.</span>append<span class="token punctuation">(</span>intents<span class="token punctuation">.</span>index<span class="token punctuation">(</span>question<span class="token punctuation">[</span><span class="token string">'intent'</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Corpus loaded"</span><span class="token punctuation">)</span> <span class="token keyword">return</span> sentences<span class="token punctuation">,</span> labels<span class="token punctuation">,</span> intents sentences<span class="token punctuation">,</span> labels<span class="token punctuation">,</span> intents <span class="token operator">=</span> read_data<span class="token punctuation">(</span>qa_data<span class="token punctuation">)</span> |
Phân chia dữ liệu
Vì dữ liệu trong các class là không đều nhau, vì vậy để đánh giá chính xác mô hình ta cần phân chia dữ liệu đánh giá sao cho số lượng các samples trong các class bằng nhau.
Đây là hình ảnh số lượng các câu hỏi trong các class tương ứng:
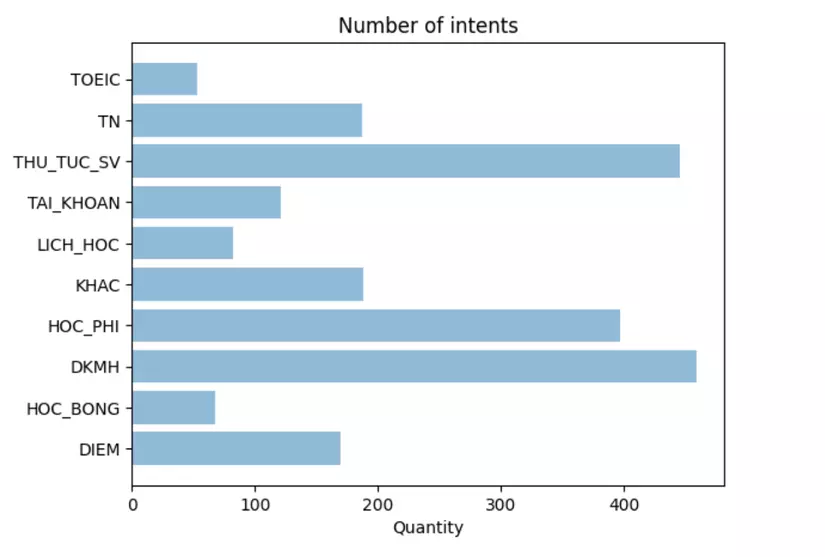
Để phân chia sao cho các câu hỏi trong các class của tập validate như nhau ta thực hiện như sau:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | <span class="token keyword">def</span> <span class="token function">split_balanced</span><span class="token punctuation">(</span>data<span class="token punctuation">,</span> target<span class="token punctuation">,</span> test_size<span class="token operator">=</span><span class="token number">0.2</span><span class="token punctuation">)</span><span class="token punctuation">:</span> classes <span class="token operator">=</span> np<span class="token punctuation">.</span>unique<span class="token punctuation">(</span>target<span class="token punctuation">)</span> <span class="token comment"># can give test_size as fraction of input data size of number of samples</span> <span class="token keyword">if</span> test_size<span class="token operator"><</span><span class="token number">1</span><span class="token punctuation">:</span> n_test <span class="token operator">=</span> np<span class="token punctuation">.</span><span class="token builtin">round</span><span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>target<span class="token punctuation">)</span><span class="token operator">*</span>test_size<span class="token punctuation">)</span> <span class="token keyword">else</span><span class="token punctuation">:</span> n_test <span class="token operator">=</span> test_size n_train <span class="token operator">=</span> <span class="token builtin">max</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token builtin">len</span><span class="token punctuation">(</span>target<span class="token punctuation">)</span><span class="token operator">-</span>n_test<span class="token punctuation">)</span> n_train_per_class <span class="token operator">=</span> <span class="token builtin">max</span><span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">,</span><span class="token builtin">int</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>floor<span class="token punctuation">(</span>n_train<span class="token operator">/</span><span class="token builtin">len</span><span class="token punctuation">(</span>classes<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> n_test_per_class <span class="token operator">=</span> <span class="token builtin">max</span><span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">,</span><span class="token builtin">int</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>floor<span class="token punctuation">(</span>n_test<span class="token operator">/</span><span class="token builtin">len</span><span class="token punctuation">(</span>classes<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> ixs <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token keyword">for</span> cl <span class="token keyword">in</span> classes<span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>n_train_per_class<span class="token operator">+</span>n_test_per_class<span class="token punctuation">)</span> <span class="token operator">></span> np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>target<span class="token operator">==</span>cl<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># if data has too few samples for this class, do upsampling</span> <span class="token comment"># split the data to training and testing before sampling so data points won't be</span> <span class="token comment"># shared among training and test data</span> splitix <span class="token operator">=</span> <span class="token builtin">int</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>ceil<span class="token punctuation">(</span>n_train_per_class<span class="token operator">/</span><span class="token punctuation">(</span>n_train_per_class<span class="token operator">+</span>n_test_per_class<span class="token punctuation">)</span><span class="token operator">*</span>np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>target<span class="token operator">==</span>cl<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> ixs<span class="token punctuation">.</span>append<span class="token punctuation">(</span>np<span class="token punctuation">.</span>r_<span class="token punctuation">[</span>np<span class="token punctuation">.</span>random<span class="token punctuation">.</span>choice<span class="token punctuation">(</span>np<span class="token punctuation">.</span>nonzero<span class="token punctuation">(</span>target<span class="token operator">==</span>cl<span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">[</span><span class="token punctuation">:</span>splitix<span class="token punctuation">]</span><span class="token punctuation">,</span> n_train_per_class<span class="token punctuation">)</span><span class="token punctuation">,</span> np<span class="token punctuation">.</span>random<span class="token punctuation">.</span>choice<span class="token punctuation">(</span>np<span class="token punctuation">.</span>nonzero<span class="token punctuation">(</span>target<span class="token operator">==</span>cl<span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">[</span>splitix<span class="token punctuation">:</span><span class="token punctuation">]</span><span class="token punctuation">,</span> n_test_per_class<span class="token punctuation">)</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">else</span><span class="token punctuation">:</span> ixs<span class="token punctuation">.</span>append<span class="token punctuation">(</span>np<span class="token punctuation">.</span>random<span class="token punctuation">.</span>choice<span class="token punctuation">(</span>np<span class="token punctuation">.</span>nonzero<span class="token punctuation">(</span>target<span class="token operator">==</span>cl<span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">,</span> n_train_per_class<span class="token operator">+</span>n_test_per_class<span class="token punctuation">,</span> replace<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># take same num of samples from all classes</span> ix_train <span class="token operator">=</span> np<span class="token punctuation">.</span>concatenate<span class="token punctuation">(</span><span class="token punctuation">[</span>x<span class="token punctuation">[</span><span class="token punctuation">:</span>n_train_per_class<span class="token punctuation">]</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> ixs<span class="token punctuation">]</span><span class="token punctuation">)</span> ix_test <span class="token operator">=</span> np<span class="token punctuation">.</span>concatenate<span class="token punctuation">(</span><span class="token punctuation">[</span>x<span class="token punctuation">[</span>n_train_per_class<span class="token punctuation">:</span><span class="token punctuation">(</span>n_train_per_class<span class="token operator">+</span>n_test_per_class<span class="token punctuation">)</span><span class="token punctuation">]</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> ixs<span class="token punctuation">]</span><span class="token punctuation">)</span> X_train <span class="token operator">=</span> data<span class="token punctuation">[</span>ix_train<span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">]</span> X_test <span class="token operator">=</span> data<span class="token punctuation">[</span>ix_test<span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">]</span> y_train <span class="token operator">=</span> target<span class="token punctuation">[</span>ix_train<span class="token punctuation">]</span> y_test <span class="token operator">=</span> target<span class="token punctuation">[</span>ix_test<span class="token punctuation">]</span> <span class="token keyword">return</span> X_train<span class="token punctuation">,</span> X_test<span class="token punctuation">,</span> y_train<span class="token punctuation">,</span> y_test |
Tiến hành chia dữ liệu huấn luyện và kiểm tra:
1 2 3 4 | trainX <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>sentences<span class="token punctuation">)</span> trainy <span class="token operator">=</span> to_categorical<span class="token punctuation">(</span>np<span class="token punctuation">.</span>array<span class="token punctuation">(</span>labels<span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token builtin">len</span><span class="token punctuation">(</span>intents<span class="token punctuation">)</span><span class="token punctuation">)</span> X_train<span class="token punctuation">,</span> X_test<span class="token punctuation">,</span> y_train<span class="token punctuation">,</span> y_test <span class="token operator">=</span> split_balanced<span class="token punctuation">(</span>trainX<span class="token punctuation">,</span> trainy<span class="token punctuation">,</span> test_size<span class="token operator">=</span><span class="token number">0.2</span><span class="token punctuation">)</span> |
Định nghĩa mô hình
Trong bài này mình sử dụng LSTM để tiến hành phân lớp. Mạng LSTM được sử dụng với keras bằng cách khá đơn giản như sau
1 2 3 4 5 6 7 8 | <span class="token comment">#model A</span> model <span class="token operator">=</span> Sequential<span class="token punctuation">(</span><span class="token punctuation">)</span> model<span class="token punctuation">.</span>add<span class="token punctuation">(</span>LSTM<span class="token punctuation">(</span><span class="token number">128</span><span class="token punctuation">,</span> input_shape<span class="token operator">=</span><span class="token punctuation">(</span>max_length_inp<span class="token punctuation">,</span> fast_text_model<span class="token punctuation">.</span>vector_size<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> model<span class="token punctuation">.</span>add<span class="token punctuation">(</span>Dropout<span class="token punctuation">(</span><span class="token number">0.2</span><span class="token punctuation">)</span><span class="token punctuation">)</span> model<span class="token punctuation">.</span>add<span class="token punctuation">(</span>Dense<span class="token punctuation">(</span><span class="token number">64</span><span class="token punctuation">,</span> activation<span class="token operator">=</span><span class="token string">'relu'</span><span class="token punctuation">)</span><span class="token punctuation">)</span> model<span class="token punctuation">.</span>add<span class="token punctuation">(</span>Dense<span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>intents<span class="token punctuation">)</span><span class="token punctuation">,</span> activation<span class="token operator">=</span><span class="token string">'softmax'</span><span class="token punctuation">)</span><span class="token punctuation">)</span> model<span class="token punctuation">.</span><span class="token builtin">compile</span><span class="token punctuation">(</span>loss<span class="token operator">=</span><span class="token string">'categorical_crossentropy'</span><span class="token punctuation">,</span> optimizer<span class="token operator">=</span><span class="token string">'adam'</span><span class="token punctuation">,</span> metrics<span class="token operator">=</span><span class="token punctuation">[</span><span class="token string">'accuracy'</span><span class="token punctuation">]</span><span class="token punctuation">)</span> |
Xem chi tiết số lượng các tham số mô hình:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 142848 _________________________________________________________________ dropout (Dropout) (None, 128) 0 _________________________________________________________________ dense (Dense) (None, 64) 8256 _________________________________________________________________ dense_1 (Dense) (None, 10) 650 ================================================================= Total params: 151,754 Trainable params: 151,754 Non-trainable params: 0 |
Huấn luyện mô hình
Để huấn luyên mô hình chúng ta sẽ fit dữ liệu huấn luyện và kiểm tra như sau:
1 2 | model<span class="token punctuation">.</span>fit<span class="token punctuation">(</span>X_train<span class="token punctuation">,</span> y_train<span class="token punctuation">,</span> epochs<span class="token operator">=</span><span class="token number">300</span><span class="token punctuation">,</span> batch_size<span class="token operator">=</span><span class="token number">20</span><span class="token punctuation">,</span> verbose<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">,</span> validation_data<span class="token operator">=</span><span class="token punctuation">(</span>X_test<span class="token punctuation">,</span> y_test<span class="token punctuation">)</span><span class="token punctuation">,</span> callbacks<span class="token operator">=</span><span class="token punctuation">[</span>tensorboard_callback<span class="token punctuation">]</span><span class="token punctuation">)</span> |
Tham số verbose=1 để chỉ định in ra kết quả đánh giá sau mỗi lần thực hiện xong 1 epoch
Kết quả sau khi chạy xong 1 số epochs như sau:
1 2 3 4 5 6 7 8 9 10 11 12 | ..... Epoch 246/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0073 - accuracy: 0.9941 - val_loss: 1.7335 - val_accuracy: 0.8364 Epoch 247/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0119 - accuracy: 0.9915 - val_loss: 1.7414 - val_accuracy: 0.8295 Epoch 248/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0074 - accuracy: 0.9929 - val_loss: 1.7672 - val_accuracy: 0.8295 Epoch 249/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0098 - accuracy: 0.9915 - val_loss: 1.7550 - val_accuracy: 0.8295 Epoch 250/300 87/87 [==============================] - 1s 14ms/step - loss: 0.0050 - accuracy: 0.9966 - val_loss: 1.7392 - val_accuracy: 0.8364 |
Đánh giá mô hình
Import các thư viện cần thiết để đánh giá:
1 2 3 4 5 6 7 8 9 | <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> accuracy_score <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> precision_score <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> recall_score <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> f1_score <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> cohen_kappa_score <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> roc_auc_score <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> confusion_matrix <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> multilabel_confusion_matrix |
Chúng ta sẽ tiến hành đánh giá mô hình dựa trên các chỉ số như f1_score, độ chính xác (accuracy) như sau:
Các phương pháp đánh giá hệ thống phân lớp các bạn có thể xem tại đây
- f1-score
1 2 3 4 5 | yhat_classes <span class="token operator">=</span> model<span class="token punctuation">.</span>predict_classes<span class="token punctuation">(</span>X_test<span class="token punctuation">,</span> verbose<span class="token operator">=</span><span class="token number">0</span><span class="token punctuation">)</span> y_test_true <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span><span class="token punctuation">[</span>np<span class="token punctuation">.</span>where<span class="token punctuation">(</span>label <span class="token operator">==</span><span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token keyword">for</span> label <span class="token keyword">in</span> y_test<span class="token punctuation">]</span><span class="token punctuation">)</span> f1 <span class="token operator">=</span> f1_score<span class="token punctuation">(</span>yhat_classes<span class="token punctuation">,</span> y_test_true<span class="token punctuation">,</span> average<span class="token operator">=</span><span class="token string">'weighted'</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>f1<span class="token punctuation">)</span> |
Kết quả in ra sẽ được:
1 2 | 0.8303684789128464 |
- Độ chính xác
1 2 3 4 | <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Evaluate on test data"</span><span class="token punctuation">)</span> results <span class="token operator">=</span> model<span class="token punctuation">.</span>evaluate<span class="token punctuation">(</span>X_test<span class="token punctuation">,</span> y_test<span class="token punctuation">,</span> batch_size<span class="token operator">=</span><span class="token number">10</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"test loss, test acc:"</span><span class="token punctuation">,</span> results<span class="token punctuation">)</span> |
Kết quả:
1 2 3 4 | Evaluate on test data 44/44 [==============================] - 0s 5ms/step - loss: 1.2874 - accuracy: 0.8272 test loss, test acc: [1.2874339818954468, 0.8271889686584473] |
Như vậy kết quả dự đoán của mô hình trên tập kiểm tra đạt 82.7 %. Kết quả chưa cao lắm nhưng có thể chấp nhận được.
Fine-tune mô hình
Để nâng cao độ chính xác của mô hình, bạn đọc có thể thử nghiệm các thay đổi bằng cách sử dụng mô hình biểu diễn từ tốt hơn hoặc sử dụng mô hình khác như BERT, GRU, RNN…
Ngoài ra chúng ta có thể thử nghiệm thay đổi các tham số để và so sánh các thay đổi để đưa ra được mô hình tốt nhất.
Tổng kết
Bài viết mình đã vừa trình bày về kỹ thuật xác định ý định của câu hỏi sử dụng deeplearning. Mọi thắc mắc và ý kiến đóng góp các bạn có thể trao đổi dưới bài viết này.
Link google colab của bài viết
Cám ơn các bạn đã đọc bài viết.