1. Lời mở đầu
Nếu các bạn đã tìm hiểu qua các bài toán về Computer Vision như object detection, classification, các bạn có thể thấy hầu hết thông tin về dữ liệu trong ảnh đã được thể hiện hết sức chi tiết và đầy đủ qua các pixel. Chúng ta chỉ cần đưa qua mô hình qua các mạng như CNN và tiến hành trích xuất thông tin. Tuy nhiên, đối với dữ liệu ở dạng text, khi thông tin dữ liệu không chỉ được chứa dưới dạng các pixel mà còn liên quan ngữ nghĩa giữa các từ thì làm cách nào có thể biểu diễn chúng? Và Word Embedding là một trong những cách giúp chúng ta có thể biễu diễn dữ liệu dạng text một cách hiệu quả hơn.
2. Word Embedding là gì ?
Word Embedding là một không gian vector dùng để biểu diễn dữ liệu có khả năng miêu tả được mối liên hệ, sự tương đồng về mặt ngữ nghĩa, văn cảnh(context) của dữ liệu. Không gian này bao gồm nhiều chiều và các từ trong không gian đó mà có cùng văn cảnh hoặc ngữ nghĩa sẽ có vị trí gần nhau. Ví dụ như ta có hai câu : “Hôm nay ăn táo ” và “Hôm nay ăn xoài “. Khi ta thực hiện Word Embedding, “táo” và “xoài” sẽ có vị trí gần nhau trong không gian chúng ta biễu diễn do chúng có vị trị giống nhau trong một câu .
3. Tại sao chúng ta cần Word Embedding ?
Chúng ta thử so sánh với một cách biểu diễn khác mà chúng ta thường dùng trong các bài toán multi-label, multi-task là one-hot encoding. Nếu sử dụng one-hot encoding, dữ liệu mà chúng ta biểu diễn sẽ có dạng như sau:
| Document | Index | One-hot encoding |
|---|---|---|
| a | 1 | [1, 0, 0, …., 0](9999 số 0) |
| b | 2 | [0, 1, 0, …., 0] |
| c | 3 | [0, 0, 1, …., 0] |
| …. | …… | …… |
| mẹ | 9999 | [0, 0, 0, …, 1, 0] |
| vân | 10000 | [0, 0, 0, …., 0, 1] |
Nhìn vào bảng bên trên, ta thấy có 3 vấn đề khi ta biểu diễn dữ liệu dạng text dưới dạng one-hot:
- Chi phí tính toán lớn : Nếu data có 100 từ, độ dài của vector one-hot là 100.Nếu data có 10000 từ, độ dài của vector one-hot là 10000. Tuy nhiên, để mô hình có độ khái quát cao thì trong thực tế dữ liệu có thể lên đến hàng triệu từ, lúc đó độ dài vector one-hot sẽ phình to gây khó khăn cho việc tính toán, lưu trữ.
- Mang ít giá trị thông tin: Các vector hầu như toàn số 0. Và các bạn có thể thấy, đối với dữ liệu dạng text thì giá trị chứa trong các pixel (nếu input dạng ảnh ) hay các dạng khác là rất ít. Nó chủ yếu nằm trong vị trí tương đối giữa các từ với nhau và quan hệ về mặt ngữ nghĩa. Tuy nhiên, one-hot vector không thể biểu diễn điều đó vì nó chỉ đánh index theo thứ tự từ điển đầu vào chứ không phải vị trí các từ trong một context cụ thể. Để khắc phục điều đó, trong mô hình thường dùng một lớp RNN hoặc LSTM để nó có thể trích xuất được thông tin về vị trí. Có một cách khác như trong mô hình transformer, được bỏ hoàn toàn lớp word embeddig hay RNN và thêm vào đó lớp positional encoding và self-attention
- Độ khái quát yếu : Ví dụ ta có ba từ cùng chỉ người mẹ : mẹ, má, bầm. Tuy nhiên, từ bầm tương đối hiếm gặp trong tiếng Việt. Khi biểu diễn bằng one-hot encoding, khi đưa vào model train thì từ bầm mặc dù cùng nghĩa so với hai từ kia nhưng lại bị phân vào class khác nhau do cách biểu diễn khác nhau. Còn nếu dùng word embedding, do biểu diễn được cả thông tin về vị trí, ngữ nghĩa nên từ bầm sẽ có vị trí gần với hai từ kia. Đúng như mục đích embedding của mình
4. Vậy làm thế nào để biễu diễn Word Embedding ?
Có 2 phương pháp chủ yếu được hay dùng để tính toán Word Embedding là Count based method và Predictive method. Cả hai cách này đều dựa trên một giả thuyết rằng những từ nào xuất hiện trong cùng một văn cảnh, một ngữ nghĩa sẽ có vị trí gần nhau trong không gian mới được biến đổi
4.1. Count-based method
Phương pháp này tính toán mức liên quan về mặt ngữ nghĩa giữa các từ bằng cách thống kê số lần đồng xuất hiện của một từ so với các từ khác.
Ví dụ bạn có hai câu như sau:
Mèo ăn cơm
Mèo ăn cá
==> Ta xây dựng được ma trận đồng xuất hiện của các từ như sau và nhận thấy cơm và cá có ý nghĩa tương đồng nhau nên nó sẽ có vị trí gần nhau trong không gian vector biểu diễn
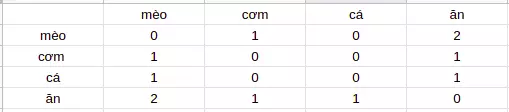
Tuy nhiên phương pháp này gặp một nhược điểm đó là khi dữ liệu của ta lớn, một số từ có tần suất xuất hiện lớn nhưng lại không mang nhiều thông tin (như trong tiếng Anh: a, an, the, …). Và nếu chúng ta thống kê cả số lượng data này thì tần suất của các từ này sẽ làm mờ đi giá trị của những từ mang nhiều thông tin nhưng ít gặp hơn.
Và để giải quyết vấn đề, có một giải pháp là chúng ta đánh lại trọng số (re-weight) cho dữ liệu sao cho phù hợp với bài toán của mình.
Có một thuật toán rất hay dùng để giải quyết vấn đề này, đó chính là TF_IDF transform. Trong đó: TF là tấn suất xuất hiện của một từ trong data(term frequency) và IDF là một hệ số giúp làm giảm trọng số của những từ hay xuất hiện trong data (inverse document frequency). Nhờ việc kết hợp giữa TF vs IDF, phương pháp này có thể giảm bớt trọng số của những từ xuất hiện nhiều nhưng lại không có nhiều thông tin.
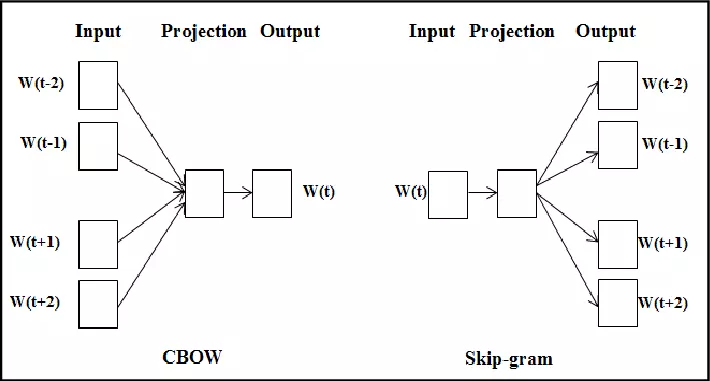
4.2. Predictive Methods (Word2Vec)
Khác so với Count-based method, Predictive method tính toán sự tương đồng ngữ nghĩa giữa các từ để dự đoán từ tiếp theo bằng cách đưa qua một mạng neural network có một hoặc vài layer dựa trên input là các từ xung quanh (context word). Một context word có thể là một hoặc nhiều từ. Ví dụ cũng với hai câu ở trên, ban đầu hai từ cơm và cá có thể được khởi tạo ở khá xa nhau nhưng để tối thiểu loss giữa hai từ đó và context word (“Mèo” và “ăn”) thì vị trí của hai từ cơm và cá trong không gian vector phải gần nhau. Có 2 phương pháp predictive method phổ biến đó chính là :
- Continuous Bag-of-Words (CBOW)
- Skip-gram
4.2.1. Continuous Bag-of-Words (CBOW)
CBOW model : Phương pháp này lấy đầu vào là một hoặc nhiều từ context word và cố gắng dự đoán output từ đầu ra (target word) thông qua một tầng neural đơn giản . Nhờ việc đánh giá output error với target word ở dạng one-hot, mô hình có thể điều chỉnh weight, học được vector biểu diễn cho target word. Ví dụ ta có một câu tiếng anh như sau : “I love you”. Ta có:
– Input context word : love
– Output target word: you
Ta biến đổi input context đầu vào dưới dạng one-hot đi qua một tầng hidden layer và thực hiện softmax phân loại để dự đoán ra từ tiếp theo là gì.
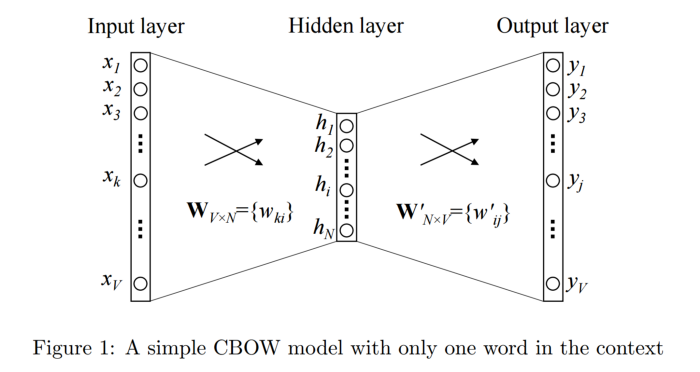
4.2.2. Skip-gram
Nếu như CBOW sử dụng input là context word và cố gắng dự đoán từ đầu ra (target word) thì ngược lại, mô hình Skip-gram sử dụng input là target word và cố gắng dự đoán ra các từ hàng xóm của nó. Chúng định nghĩa các từ là hàng xóm (neightbor word) của nó thông qua tham số window size. Ví dụ nếu bạn có một câu như sau: “Tôi thích ăn cua hoàng đế”. Và input target word ban đầu là từ cua. Với kích thước window size = 2, ta sẽ có các neighbor word (thích, ăn, hoàng, đế ). Và chúng ta sẽ có 4 cặp input-output như sau: (cua, thích ), (cua, hoàng ), (cua, đế ), (cua, ăn ). Các neightbor word được coi như nhau trong quá trình training.
Tổng kết: So sánh giữa hai phương pháp Count based method và Word2Vec, khi chúng ta huấn luyện một bộ dữ liệu lớn, thì Count-based method cần tương đối nhiều bộ nhớ hơn so với Word2Vec do phải xây dựng một ma trận đồng xuất hiện khổng lồ. Tuy nhiên, do nó được xây dựng trên việc thống kê các từ nên khi số lượng dữ liệu của bạn đủ lớn, bạn có thể train thêm nhiều nhiều dữ liệu nữa mà không lo tăng kích thước của ma trận đồng xuất hiện trong khi tăng độ chính xác của mô hình. Trong khi đó việc tăng thêm dữ liệu khi đã có lượng dữ liệu tương đối với Predictive method là hoàn toàn không thể vì dữ liệu được chia thành hai tập train và valid. Nhưng ngược lại, Word2Vec sử dụng mô hình học máy giúp tăng tính khái quát của mô hình đồng thời giảm chi phí tính toán và bộ nhớ
5. Lời kết
Gần đây mình mới học khóa về NLP nên bài viết có thể có nhiều sai sót, khó hiểu nên nếu có gì sai sót các bạn có thể comment dưới bài viết nhé  . Cảm ơn các bạn đã theo dõi bài viết của mình.
. Cảm ơn các bạn đã theo dõi bài viết của mình. 