Để tiếp nối seri này, hôm nay mình sẽ viết về 2 khái niệm cơ bản nhất trong Semantic Annotation là Ontology và RDF.
1-Ontology
1.1 Khái niệm
Trong khoa học máy tính, một ontology là một mô hình dữ liệu biểu diễn một lĩnh vực và được sử dụng để suy luận về các đối tượng trong lĩnh vực đó và mối quan hệ giữa chúng. Ontology
cung cấp một bộ từ vựng chung bao gồm các khái niệm, các thuộc tính quan trọng và các định nghĩa về các khái niệm và các thuộc tính này. Ngoài bộ từ vựng, ontology còn cung cấp các ràng
buộc, đôi khi các ràng buộc này được coi như các giả định cơ sở về ý nghĩa mong muốn của bộ từ vựng, nó được sử dụng trong một miền mà có thể được giao tiếp giữa người và các hệ thống
ứng dụng phân tán hỗn tạp khác.
Các ontology được sử dụng như là một biểu mẫu trình bày tri thức về thế giới hay một phần của nó. Các ontology thường miêu tả:
- Các cá thể: Các đối tượng cơ bản, nền tảng.
- Các lớp: Các tập hợp, hay kiểu của các đối tượng.
- Các thuộc tính: Thuộc tính, tính năng, đặc điểm, tính cách, hay các thông số mà các đối tượng có và có thể đem ra chia sẻ.
- Các mối liên hệ: Các con đường mà các đối tượng có thể liên hệ tới một đối tượng khác.
Bộ từ vựng ontology được xây dựng trên cơ sở tầng RDF và RDFS, cung cấp khả năng biểu diễn ngữ nghĩa mềm dẻo cho tài nguyên Web và có khả năng hỗ trợ lập luận.
1.2 Các thành phần Ontology
Các cá thể (Individuals) – Thể hiện
Các cá thể là các thành phần cơ bản, nền tảng của một ontology. Các cá thể trong một ontology có thể bao gồm các đối tượng cụ thể như con người, động vật, cái bàn… cũng như các cá thể
trừu tượng như các thành viên hay các từ. Một ontology có thể không cần bất kỳ một cá thể nào, nhưng một trong những lý do chính của một ontology là để cung cấp một ngữ nghĩa của việc
phân lớp các cá thể, mặc dù các cá thể này không thực sự là một phần của ontology.
Các lớp (Classes) – Khái niệm
Các lớp là các nhóm, tập hợp các đối tượng trừu tượng. Chúng có thể chứa các cá thể, các lớp khác, hay là sự phối hợp của cả hai.
Các ontology biến đổi tuỳ thuộc vào cấu trúc và nội dung của nó: Một lớp có thể chứa các lớp con, có thể là một lớp tổng quan (chứa tất cả mọi thứ), có thể là lớp chỉ chứa những cá thể riêng
lẻ, Một lớp có thể xếp gộp vào hoặc bị xếp gộp vào bởi các lớp khác. Mối quan hệ xếp gộp này được sử dụng để tạo ra một cấu trúc có thứ bậc các lớp, thường là với một lớp thông dụng nhất
kiểu Thing ở trên đỉnh và các lớp rất rõ ràng kiểu 2002, Ford ở phía dưới cùng.
Các thuộc tính (Properties)
Các đối tượng trong ontology có thể được mô tả thông qua việc khai báo các thuộc tính của chúng. Mỗi một thuộc tính đều có tên và giá trị của thuộc tính đó. Các thuộc tính được sử dụng
để lưu trữ các thông tin mà đối tượng có thể có. Ví dụ, đối với một cá nhân có thể có các thuộc tính: Họ_tên, ngày_sinh, quê_quán, số_cmnd…
Giá trị của một thuộc tính có thể có các kiểu dữ liệu phức tạp.
Các mối quan hệ (Relation)
Một trong những ứng dụng quan trọng của việc sử dụng các thuộc tính là để mô tả mối liên hệ giữa các đối tượng trong ontology. Một mối quan hệ là một thuộc tính có giá trị là một đối tượng
nào đó trong ontology.
Một kiểu quan hệ quan trọng là kiểu quan hệ xếp gộp (subsumption). Kiểu quan hệ này mô tả các đối tượng nào là các thành viên của các lớp nào của các đối tượng.
Hiện tại, việc kết hợp các ontology là một tiến trình được làm phần lớn là thủ công, do vậy rất tốn thời gian và đắt đỏ. Việc sử dụng các ontology là cơ sở để cung cấp một định nghĩa thông
dụng của các thuật ngữ cốt lõi có thể làm cho tiến trình này trở nên dễ quản lý hơn. Hiện đang có các nghiên cứu dựa trên các kỹ thuật sản sinh để nối kết các ontology, tuy nhiên lĩnh vực này
mới chỉ hiện hữu về mặt lý thuyết.
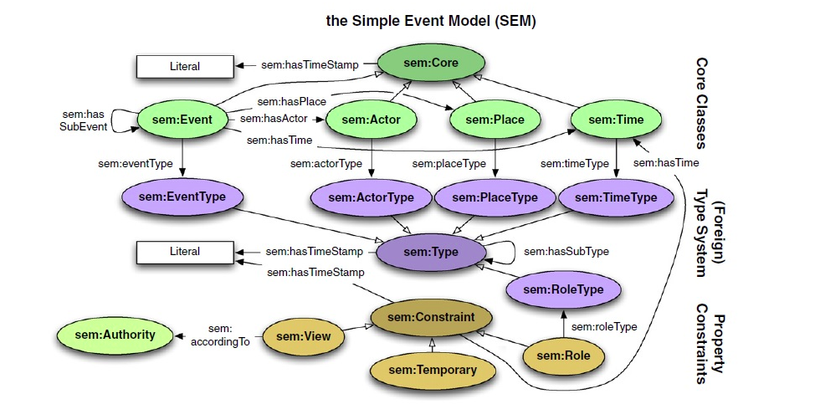
Ví dụ về 1 ontology
2- RDF
2.1 Khái niệm
Nội dung thông tin Web được phục vụ chủ yếu cho con người, và máy móc không thể đọc và hiểu được nội dung này. Do đó, rất khó để tự động hóa bất cứ nội dung nào trên Web, ít nhất trên quy mô lớn. Hơn nữa, với lượng thông tin khổng lồ trên Web, chúng ta không thể xử lý chúng chỉ bằng phương pháp thủ công. Vì vậy, W3C đề xuất một giải pháp để mô tả dữ liệu trên Web và có thể được hiểu bởi máy móc, đó chính là RDF.
RDF (viết tắt từ Resource Description Framework, tạm dịch là Framework Mô tả Tài nguyên) có nguồn gốc tạo ra từ đầu năm 1999 bởi tổ chức W3C như là 1 tiêu chuẩn để mã hóa siêu dữ liệu (metadata). Tên RDF được giới thiệu chính thức trong các tài liệu đặc tả của W3C với nội dung sơ lược.
2.2 Các đặc tính
RDF là 1 ngôn ngữ thể hiện thông tin về các tài nguyên web. (theo tài liệu RDF Primer)
RDF là 1 framework cho việc thể hiện thông tin trên web (theo tài liệu RDF Concept)
RDF là 1 ngôn ngữ mục đích chung cho việc thể hiện thông tin trên Web (theo tài liệu RDF Syntax và tài liệu RDF Schema);
RDF là 1 ngôn ngữ xác nhận được dùng để diễn tả các giới từ dùng các từ vựng chính thức chính xác, đặc biệt là những từ được đặc tả dùng RDFS, để truy cập và sử dụng trên Web, và có ý định để cung cấp 1 nền tảng cơ bản cho các ngôn ngữ xác nhận nâng cao với mục đích tương tự (theo tài liệu RDF Semantics).
Tóm gọn lại Ontology chính là cơ sở các từ vựng của cơ sở nghữ nghĩa, và ngôn ngữ để mô tả ontology có thể dùng RDF.
Dưới đây là ví dụ một tập Ontology về sách , được mô tả bằng ngôn ngữ RDF
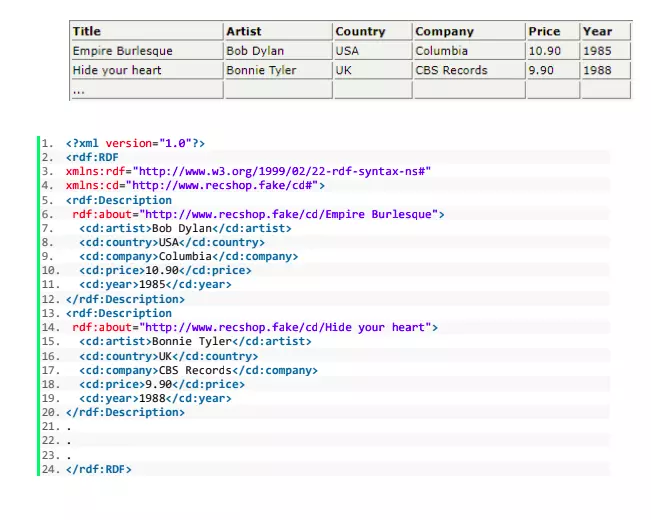
Trong phần tới, mình sẽ nói rõ hơn về graph data , thứ sẽ tạo khác biệt về lưu trữ làm nên sức mạnh suy luận của cơ sở ngữ nghĩa 