Trong bài viết trước viết về tổng quan về Tin sinh học, chúng ta đã có thể liệt kê một số ứng dụng của các phương pháp của khoa học máy tính khi áp dụng cho việc thu thập, lưu trữ, tổ chức, phân tích hoặc trực quan hóa dữ liệu Sinh học. Bài viết này sẽ nói về cách thể hiện, cấu trúc dữ liệu cũng như cách xử lý dữ liệu DNA. Cùng với đó, bài viết cũng cung cấp một ví dụ nhỏ về cách phân loại họ gen bằng phương pháp học máy đơn giản.
DNA là gì
DNA (Deoxyribonucleic Acid) hay còn được gọi với tên ADN (acide désoxyribonucléique) là một phân tử chứa các chỉ dẫn sinh học tạo nên sự đặc trưng của từng loài. DNA, cùng với các thông tin di truyền mà nó chứa, được truyền từ các sinh vật trưởng thành sang con cái của chúng trong quá trình sinh sản.
Bộ gen người có khoảng từ 20.000-25.0000 gen, được tập hợp bên trong các nhiễm sắc thể (NST) nằm trong nhân tế bào. Bộ gen người bao gồm khoảng 3 tỷ phân tử cặp base (bazơ), các cặp DNA của người được cấu tạo nên từ 4 loại nucleotide bao gồm “A”, “C”, “G”, “T”. Tất cả chúng ta đều có bộ gen riêng biệt tuy nhiên vẫn chia sẻ nhiều phần giống nhau.
Đối với dữ liệu DNA, các kĩ thuật học máy có thể được áp dụng ddeer:
- Nắm bắt quan hệ phụ thuộc trong dữ liệu
- Suy luận và phát hiện các giả thuyết sinh học mới
Vậy trong bài viết này, chúng ta sẽ tìm hiểu cách diễn giải cấu trúc DNA và cách các thuật toán học máy có thể được sử dụng để xây dựng mô hình dự đoán trên dữ liệu chuỗi DNA.
Cách các DNA được thể hiện
Phần lớn các phân tử DNA được cấu tạo từ hai mạch polyme sinh học xoắn đều quanh một trục tưởng tượng tạo thành chuỗi xoắn kép.

Hình minh họa từ trang https://biologydictionary.net/double-helix/
Hai mạch DNA này được gọi là các polynucleotide vì thành phần của chúng bao gồm các đơn phân nucleotide. Mỗi nucleotide được cấu tạo từ một trong bốn loại nucleobase chứa nitơ—hoặc là cytosine (C), guanine (G), adenine (A), hay thymine (T)—liên kết với đường deoxyribose và một nhóm phosphat. Các nucleotide liên kết với nhau thành một mạch DNA bằng liên kết cộng hóa trị giữa phân tử đường của nucleotide với nhóm phosphat của nucleotide tiếp theo, tạo thành “khung xương sống” đường-phosphat luân phiên vững chắc.
Thứ tự hoặc trình tự của các nucleobase xác định những chỉ dẫn sinh học nào được chứa trong một chuỗi DNA. Ví dụ như một vùng cụ thể trên nhiễm sắc thể thứ 15 có vai trò quan trọng trong việc quy định màu mắt.
Cách Python xử lý các dữ liệu DNA
Chúng ta đều biết rằng, Python có rất nhiều thư viện hỗ trợ cho việc xử lý cũng như trực quan hóa dữ liệu mà một phần trong số đó là dữ liệu sinh học. Hai trong số các thư viện có thể kể đến là Biopython và squiggle
Biopython là một tập hợp các module python cung cấp các chức năng để xử lý các hoạt động của chuỗi DNA, RNA và protein như bổ sung ngược lại chuỗi DNA, tìm các mô-đun trong chuỗi protein, v.v. Nó cung cấp rất nhiều trình phân tích cú pháp để đọc tất cả các cơ sở dữ liệu di truyền chính như GenBank , SwissPort, FASTA, v.v.,
Squiggle là một công cụ phần mềm tự động tạo ra các biểu diễn đồ họa hai chiều trên nền web của chuỗi DNA thô. Squiggle có cài đặt một số thuật toán trực quan hóa trình tự được công bố trước đó và giới thiệu các phương pháp trực quan hóa mới được thiết kế để tối đa hóa khả năng sử dụng của người dùng.
Để cài đặt hai thư viện trên, bắt đầu với môi trường Jupyter Notebook chúng ta sử dụng các câu lệnh sau:
1 2 3 | !pip install biopython !pip install Squiggle |
Dữ liệu về gen thường được lưu ở một số định dạng và một trong số đó là FASTA. Khi mở một tệp FASTA, chúng ta có thể thấy nội dung sẽ tương tự như sau:
1 2 3 4 5 6 7 | >HSBGPG Human gene for bone gla protein (BGP) GGCAGATTCCCCCTAGACCCGCCCGCACCATGGTCAGGCATGCCCCTCCTCATCGCTGGGCACAGCCCAGAGGGT ATAAACAGTGCTGGAGGCTGGCGGGGCAGGCCAGCTGAGTCCTGAGCAGCAGCCCAGCGCAGCCACCGAGACACC ATGAGAGCCCTCACACTCCTCGCCCTATTGGCCCTGGCCGCACTTTGCATCGCTGGCCAGGCAGGTGAGTGCCCC CACCTCCCCTCAGGCCGCATTGCAGTGGGGGCTGAGAGGAGGAAGCACCATGGCCCACCTCTTCTCACCCCTTTG ...... |
Để xem toàn bộ nội dung tệp ví dụ trên mọi người có thể xem tại http://www.cbs.dtu.dk/services/NetGene2/fasta.php. Toàn bộ nội dung của tệp FASTA là phần in đậm ở trang web trên. Sao chép phần đó và lưu lại với định dạng .fa như file text thông thường chẳng hạn như example.fa, chúng có thể sử dụng file đó làm dữ liệu cho ví dụ với
Squiggle.
Để sử dụng tốt matplotlib với Jupyter Notebook chúng ta sử dụng câu lệnh magic muôn thủa
1 2 | <span class="token operator">%</span>matplotlib inline |
Tiếp đó, với thư viện Biopython chúng ta có thể đọc được thông tin của file dữ liệu bằng các câu lệnh sau:
1 2 3 4 5 6 7 | <span class="token keyword">from</span> Bio <span class="token keyword">import</span> SeqIO <span class="token keyword">for</span> sequence <span class="token keyword">in</span> SeqIO<span class="token punctuation">.</span>parse<span class="token punctuation">(</span><span class="token string">'./example.fa'</span><span class="token punctuation">,</span> <span class="token string">'fasta'</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>sequence<span class="token punctuation">.</span><span class="token builtin">id</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>sequence<span class="token punctuation">.</span>seq<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>sequence<span class="token punctuation">)</span><span class="token punctuation">)</span> |
Kết quả thu được như sau:
1 2 3 4 5 6 7 | HSBGPG GGCAGATTCCCCCTAGACCCGCCCGCACCATGGTCAGGCATGCCCCTCCTCATCGCTGGGCACAGCCCAGAGGGTATAAACAGTGCTGGAGGCTGGCGGGGCAGGCCAGCTGAGTCCTGAGCAGCAGCCCAGCGCAGCCACCGAGACACCATGAGAGCCCTCACACTCCTCGCCCTATTGGCCCTGGCCGCACTTTGCATCGCTGGCCAGGCAGGTGAGTGCCCCCACCTCCCCTCAGGCCGCATTGCAGTGGGGGCTGAGAGGAGGAAGCACCATGGCCCACCTCTTCTCACCCCTTTGGCTGGCAGTCCCTTTGCAGTCTAACCACCTTGTTGCAGGCTCAATCCATTTGCCCCAGCTCTGCCCTTGCAGAGGGAGAGGAGGGAAGAGCAAGCTGCCCGAGACGCAGGGGAAGGAGGATGAGGGCCCTGGGGATGAGCTGGGGTGAACCAGGCTCCCTTTCCTTTGCAGGTGCGAAGCCCAGCGGTGCAGAGTCCAGCAAAGGTGCAGGTATGAGGATGGACCTGATGGGTTCCTGGACCCTCCCCTCTCACCCTGGTCCCTCAGTCTCATTCCCCCACTCCTGCCACCTCCTGTCTGGCCATCAGGAAGGCCAGCCTGCTCCCCACCTGATCCTCCCAAACCCAGAGCCACCTGATGCCTGCCCCTCTGCTCCACAGCCTTTGTGTCCAAGCAGGAGGGCAGCGAGGTAGTGAAGAGACCCAGGCGCTACCTGTATCAATGGCTGGGGTGAGAGAAAAGGCAGAGCTGGGCCAAGGCCCTGCCTCTCCGGGATGGTCTGTGGGGGAGCTGCAGCAGGGAGTGGCCTCTCTGGGTTGTGGTGGGGGTACAGGCAGCCTGCCCTGGTGGGCACCCTGGAGCCCCATGTGTAGGGAGAGGAGGGATGGGCATTTTGCACGGGGGCTGATGCCACCACGTCGGGTGTCTCAGAGCCCCAGTCCCCTACCCGGATCCCCTGGAGCCCAGGAGGGAGGTGTGTGAGCTCAATCCGGACTGTGACGAGTTGGCTGACCACATCGGCTTTCAGGAGGCCTATCGGCGCTTCTACGGCCCGGTCTAGGGTGTCGCTCTGCTGGCCTGGCCGGCAACCCCAGTTCTGCTCCTCTCCAGGCACCCTTCTTTCCTCTTCCCCTTGCCCTTGCCCTGACCTCCCAGCCCTATGGATGTGGGGTCCCCATCATCCCAGCTGCTCCCAAATAAACTCCAGAAG <span class="token number">1231</span> HSGLTH1 CCACTGCACTCACCGCACCCGGCCAATTTTTGTGTTTTTAGTAGAGACTAAATACCATATAGTGAACACCTAAGACGGGGGGCCTTGGATCCAGGGCGATTCAGAGGGCCCCGGTCGGAGCTGTCGGAGATTGAGCGCGCGCGGTCCCGGGATCTCCGACGAGGCCCTGGACCCCCGGGCGGCGAAGCTGCGGCGCGGCGCCCCCTGGAGGCCGCGGGACCCCTGGCCGGTCCGCGCAGGCGCAGCGGGGTCGCAGGGCGCGGCGGGTTCCAGCGCGGGGATGGCGCTGTCCGCGGAGGACCGGGCGCTGGTGCGCGCCCTGTGGAAGAAGCTGGGCAGCAACGTCGGCGTCTACACGACAGAGGCCCTGGAAAGGTGCGGCAGGCTGGGCGCCCCCGCCCCCAGGGGCCCTCCCTCCCCAAGCCCCCCGGACGCGCCTCACCCACGTTCCTCTCGCAGGACCTTCCTGGCTTTCCCCGCCACGAAGACCTACTTCTCCCACCTGGACCTGAGCCCCGGCTCCTCACAAGTCAGAGCCCACGGCCAGAAGGTGGCGGACGCGCTGAGCCTCGCCGTGGAGCGCCTGGACGACCTACCCCACGCGCTGTCCGCGCTGAGCCACCTGCACGCGTGCCAGCTGCGAGTGGACCCGGCCAGCTTCCAGGTGAGCGGCTGCCGTGCTGGGCCCCTGTCCCCGGGAGGGCCCCGGCGGGGTGGGTGCGGGGGGCGTGCGGGGCGGGTGCAGGCGAGTGAGCCTTGAGCGCTCGCCGCAGCTCCTGGGCCACTGCCTGCTGGTAACCCTCGCCCGGCACTACCCCGGAGACTTCAGCCCCGCGCTGCAGGCGTCGCTGGACAAGTTCCTGAGCCACGTTATCTCGGCGCTGGTTTCCGAGTACCGCTGAACTGTGGGTGGGTGGCCGCGGGATCCCCAGGCGACCTTCCCCGTGTTTGAGTAAAGCCTCTCCCAGGAGCAGCCTTCTTGCCGTGCTCTCTCGAGGTCAGGACGCGAGAGGAAGGCGC <span class="token number">1020</span> |
Tất nhiên bên cạnh việc chỉ in ra như trên chúng ta có thể sử dụng thư viện Squiggle đã nhắc đến ở trên để trực quan hóa dữ liệu.
Sử dụng câu lệnh đưới đây, Squiggle sẽ mở một trang web trực quan hóa dữ liệu mà trên đó chúng ta có thể di chuyển, phóng to, và tương tác với dữ liệu.
1 2 | !squiggle <span class="token punctuation">.</span><span class="token operator">/</span>example<span class="token punctuation">.</span>fa |
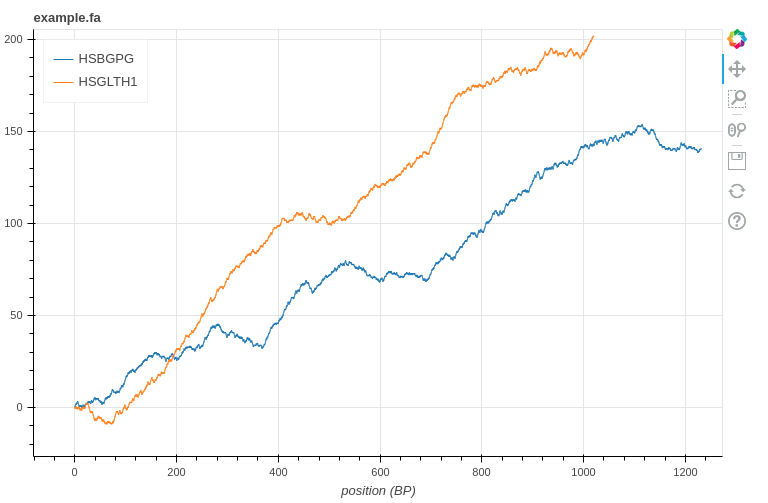
Ngoài ra còn nhiều tùy chọn của
Squigglemà chúng ta có thể tìm hiểu thêm tại trang document của thư viện này.
Dự đoán họ gen dựa trên các phương pháp học máy
Họ gen là một tập hợp của một số gen giống nhau, được hình thành bằng cách nhân đôi của một gen ban đầu, nhìn chung có chức năng sinh hóa tương tự. Các gen được phân loại thành các họ dựa trên trình tự nucleotide hoặc protein được chia sẻ.
Biết được trình tự của protein được mã hóa bởi một gen có thể cho phép các nhà nghiên cứu áp dụng các phương pháp tìm kiếm sự tương đồng giữa các trình tự protein cung cấp nhiều thông tin hơn là sự tương đồng hoặc khác biệt giữa các trình tự DNA.
Nội dụng trên tham khảo ở 7.15A: Gene Families
Chuẩn bị dữ liệu
Trong ví dụ này, chúng ta sẽ sử dụng dữ liệu về DNA của người, tinh tinh và loài chó, ví dụ này được thực hiện dựa trên repo của tác giả Nagesh Singh Chauhan vậy nên dữ liệu được sử dụn của ba loài trên cũng có sẵn trong repo DNA-Sequence-Machine-learning.
Dữ liệu bao gồm các nhóm gen được gán nhãn như sau:
| Gene Family | Class label |
|---|---|
| G protein coupled receptors | 0 |
| Tyrosine kinase | 1 |
| Tyrosine phosphatase | 2 |
| Synthetase | 3 |
| Synthase | 4 |
| Ion channel | 5 |
| Transcription factor | 6 |
Sau khi tải về các dữ liệu trên, đầu tiên như thường lệ, chúng ta import các thư viện cần sử dungj:
1 2 3 4 5 6 | <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np <span class="token keyword">import</span> pandas <span class="token keyword">as</span> pd <span class="token keyword">import</span> matplotlib<span class="token punctuation">.</span>pyplot <span class="token keyword">as</span> plt <span class="token keyword">from</span> functools <span class="token keyword">import</span> partial |
Tiếp theo đó bằng thư viện pandas chúng ta đọc dữ liệu đã tải về như sau:
1 2 3 4 | humandf <span class="token operator">=</span> pd<span class="token punctuation">.</span>read_table<span class="token punctuation">(</span><span class="token string">'data/human_data.txt'</span><span class="token punctuation">)</span> chimpdf <span class="token operator">=</span> pd<span class="token punctuation">.</span>read_table<span class="token punctuation">(</span><span class="token string">'data/chimp_data.txt'</span><span class="token punctuation">)</span> dogdf <span class="token operator">=</span> pd<span class="token punctuation">.</span>read_table<span class="token punctuation">(</span><span class="token string">'data/dog_data.txt'</span><span class="token punctuation">)</span> |
Chuyển đổi dữ liệu chuỗi DNA thành ma trận đặc trưng bằng k-mer
Kĩ thuật k-mer counting có thể hiểu là chuỗi thành các “word” có độ dài k trùng lấp nhau. Trong ví dụ này, ta sẽ sử dụng k = 6. Hàm sau được sử dụng để áp dụng kĩ thuật k-mer:
1 2 3 | <span class="token keyword">def</span> <span class="token function">Kmers_funct</span><span class="token punctuation">(</span>seq<span class="token punctuation">,</span> size<span class="token operator">=</span><span class="token number">4</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">return</span> <span class="token punctuation">[</span>seq<span class="token punctuation">[</span>x<span class="token punctuation">:</span>x<span class="token operator">+</span>size<span class="token punctuation">]</span><span class="token punctuation">.</span>lower<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>seq<span class="token punctuation">)</span> <span class="token operator">-</span> size <span class="token operator">+</span> <span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">]</span> |
Tiếp đến ta có hàm sentencize để tạo các “câu” k-mer
1 2 3 4 5 6 7 8 9 10 | <span class="token keyword">def</span> <span class="token function">sentencize</span><span class="token punctuation">(</span>df<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token triple-quoted-string string">'''Generate a df into kmers sentences and target vectors'''</span> seq_list <span class="token operator">=</span> df<span class="token punctuation">[</span><span class="token string">'sequence'</span><span class="token punctuation">]</span><span class="token punctuation">.</span>tolist<span class="token punctuation">(</span><span class="token punctuation">)</span> y_gt <span class="token operator">=</span> df<span class="token punctuation">[</span><span class="token string">'class'</span><span class="token punctuation">]</span><span class="token punctuation">.</span>tolist<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token comment"># apply Kmer-counting to seq-list</span> kmers_list <span class="token operator">=</span> <span class="token builtin">map</span><span class="token punctuation">(</span>partial<span class="token punctuation">(</span>Kmers_funct<span class="token punctuation">,</span> size<span class="token operator">=</span><span class="token number">6</span><span class="token punctuation">)</span><span class="token punctuation">,</span> seq_list<span class="token punctuation">)</span> <span class="token comment">#k-mer words of length 6</span> sentences <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token string">' '</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span>seq<span class="token punctuation">)</span> <span class="token keyword">for</span> seq <span class="token keyword">in</span> kmers_list<span class="token punctuation">]</span> <span class="token keyword">return</span> sentences<span class="token punctuation">,</span> y_gt |
Từ đó ta thu được sents_human và y_human qua câu lệnh sau:
1 2 | sents_human<span class="token punctuation">,</span> y_human <span class="token operator">=</span> sentencize<span class="token punctuation">(</span>humandf<span class="token punctuation">)</span> |
Tiếp tục vectorize bằng cách sử dụng BOW cũng như chia tập train và test:
1 2 3 4 5 6 7 | tf <span class="token operator">=</span> CountVectorizer<span class="token punctuation">(</span>ngram_range<span class="token operator">=</span><span class="token punctuation">(</span><span class="token number">4</span><span class="token punctuation">,</span><span class="token number">4</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># 4-gram </span> x_human <span class="token operator">=</span> tf<span class="token punctuation">.</span>fit_transform<span class="token punctuation">(</span>sents_human<span class="token punctuation">)</span> <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>model_selection <span class="token keyword">import</span> train_test_split x_train<span class="token punctuation">,</span> x_test<span class="token punctuation">,</span> y_train<span class="token punctuation">,</span> y_test <span class="token operator">=</span> train_test_split<span class="token punctuation">(</span>x_human<span class="token punctuation">,</span> y_human<span class="token punctuation">,</span> test_size<span class="token operator">=</span><span class="token number">0.2</span><span class="token punctuation">,</span> random_state<span class="token operator">=</span><span class="token number">42</span><span class="token punctuation">)</span> |
Phân lớp
Phân lớp bằng Multinomial Naive Bayes
Khởi tạo mô hình và huấn luyện bằng câu lệnh sau:
1 2 3 4 5 6 7 8 | <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>naive_bayes <span class="token keyword">import</span> MultinomialNB <span class="token comment">#create a model</span> clf_bayes <span class="token operator">=</span> MultinomialNB<span class="token punctuation">(</span>alpha<span class="token operator">=</span><span class="token number">0.1</span><span class="token punctuation">)</span> <span class="token comment">#train on data</span> clf_bayes<span class="token punctuation">.</span>fit<span class="token punctuation">(</span>x_train<span class="token punctuation">,</span> y_train<span class="token punctuation">)</span> |
Sau đó sử dụng mô hình vừa huấn luyện để đoán trên tập test, ta thu được y_pred
1 2 | y_pred <span class="token operator">=</span> clf_bayes<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>x_test<span class="token punctuation">)</span> |
Từ kết quả đó, chúng ta có thể đánh giá bằng các phương pháp phổ biến hiện nay như sau:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <span class="token comment">#look at model performance: confusion matrix, accuracy, precision, recall, f1 score</span> <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>metrics <span class="token keyword">import</span> accuracy_score<span class="token punctuation">,</span> f1_score<span class="token punctuation">,</span> precision_score<span class="token punctuation">,</span> recall_score <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Confusion matrix for predictions on human test DNA sequencen"</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>pd<span class="token punctuation">.</span>crosstab<span class="token punctuation">(</span>pd<span class="token punctuation">.</span>Series<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> name<span class="token operator">=</span><span class="token string">'Actual'</span><span class="token punctuation">)</span><span class="token punctuation">,</span> pd<span class="token punctuation">.</span>Series<span class="token punctuation">(</span>y_pred<span class="token punctuation">,</span> name<span class="token operator">=</span><span class="token string">'Predicted'</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">calculate_metrics</span><span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> y_predicted<span class="token punctuation">)</span><span class="token punctuation">:</span> accuracy <span class="token operator">=</span> accuracy_score<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> y_predicted<span class="token punctuation">)</span> precision <span class="token operator">=</span> precision_score<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> y_predicted<span class="token punctuation">,</span> average<span class="token operator">=</span><span class="token string">'weighted'</span><span class="token punctuation">)</span> recall <span class="token operator">=</span> recall_score<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> y_predicted<span class="token punctuation">,</span> average<span class="token operator">=</span><span class="token string">'weighted'</span><span class="token punctuation">)</span> f1 <span class="token operator">=</span> f1_score<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> y_predicted<span class="token punctuation">,</span> average<span class="token operator">=</span><span class="token string">'weighted'</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"accuracy = %.3f nprecision = %.3f nrecall = %.3f nf1 = %.3f"</span> <span class="token operator">%</span> <span class="token punctuation">(</span>accuracy<span class="token punctuation">,</span> precision<span class="token punctuation">,</span> recall<span class="token punctuation">,</span> f1<span class="token punctuation">)</span><span class="token punctuation">)</span> calculate_metrics<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> y_pred<span class="token punctuation">)</span> |
Từ đó ta thu được kết quả như sau
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Confusion matrix <span class="token keyword">for</span> predictions on human <span class="token builtin class-name">test</span> DNA sequence Predicted <span class="token number">0</span> <span class="token number">1</span> <span class="token number">2</span> <span class="token number">3</span> <span class="token number">4</span> <span class="token number">5</span> <span class="token number">6</span> Actual <span class="token number">0</span> <span class="token number">99</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">1</span> <span class="token number">0</span> <span class="token number">2</span> <span class="token number">1</span> <span class="token number">0</span> <span class="token number">104</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">2</span> <span class="token number">2</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">78</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">3</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">124</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">1</span> <span class="token number">4</span> <span class="token number">1</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">143</span> <span class="token number">0</span> <span class="token number">5</span> <span class="token number">5</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">51</span> <span class="token number">0</span> <span class="token number">6</span> <span class="token number">1</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">1</span> <span class="token number">0</span> <span class="token number">0</span> <span class="token number">263</span> accuracy <span class="token operator">=</span> <span class="token number">0.984</span> precision <span class="token operator">=</span> <span class="token number">0.984</span> recall <span class="token operator">=</span> <span class="token number">0.984</span> f1 <span class="token operator">=</span> <span class="token number">0.984</span> |
Máy vector tựa
Đoạn mã sau được sử dụng để huấn luyện cũng như đánh giá kết quả của mô hình
1 2 3 4 5 6 7 8 9 10 | <span class="token keyword">from</span> sklearn <span class="token keyword">import</span> svm clf_svm <span class="token operator">=</span> svm<span class="token punctuation">.</span>SVC<span class="token punctuation">(</span>C<span class="token operator">=</span><span class="token number">100</span><span class="token punctuation">,</span> gamma<span class="token operator">=</span><span class="token number">0.001</span><span class="token punctuation">,</span> kernel<span class="token operator">=</span><span class="token string">'rbf'</span><span class="token punctuation">)</span> <span class="token comment">#train</span> clf_svm<span class="token punctuation">.</span>fit<span class="token punctuation">(</span>x_train<span class="token punctuation">,</span> y_train<span class="token punctuation">)</span> <span class="token comment">#predict and eval</span> calculate_metrics<span class="token punctuation">(</span>y_test<span class="token punctuation">,</span> clf_svm<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>x_test<span class="token punctuation">)</span><span class="token punctuation">)</span> |
Kết quả thu được như sau:
1 2 3 4 5 | accuracy <span class="token operator">=</span> <span class="token number">0.893</span> precision <span class="token operator">=</span> <span class="token number">0.921</span> recall <span class="token operator">=</span> <span class="token number">0.893</span> f1 <span class="token operator">=</span> <span class="token number">0.896</span> |
Dự đoán từ dữ liệu trình tự DNA của các loài khác
Tương tự với khi xử lý dữ liệu gen người, chúng ta tiến hành trên dữ liệu DNA của các loài khác như sau:
1 2 3 4 5 6 | sents_chimp<span class="token punctuation">,</span> y_chimp <span class="token operator">=</span> sentencize<span class="token punctuation">(</span>chimpdf<span class="token punctuation">)</span> sents_dog<span class="token punctuation">,</span> y_dog <span class="token operator">=</span> sentencize<span class="token punctuation">(</span>dogdf<span class="token punctuation">)</span> x_chimp <span class="token operator">=</span> tf<span class="token punctuation">.</span>transform<span class="token punctuation">(</span>sents_chimp<span class="token punctuation">)</span> x_dog <span class="token operator">=</span> tf<span class="token punctuation">.</span>transform<span class="token punctuation">(</span>sents_dog<span class="token punctuation">)</span> |
Tiếp theo đó định nghĩa hàm evaluate_classifier như sau:
1 2 3 4 5 6 7 8 9 10 11 | <span class="token keyword">def</span> <span class="token function">evaluate_classifier</span><span class="token punctuation">(</span>model<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment">#predict</span> y_pred_chimp <span class="token operator">=</span> model<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>x_chimp<span class="token punctuation">)</span> y_pred_dog <span class="token operator">=</span> model<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>x_dog<span class="token punctuation">)</span> <span class="token comment">#eval</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Performance on Chimpanzee test DNA"</span><span class="token punctuation">)</span> calculate_metrics<span class="token punctuation">(</span>y_chimp<span class="token punctuation">,</span> y_pred_chimp<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"----nPerformance on Dog test DNA"</span><span class="token punctuation">)</span> calculate_metrics<span class="token punctuation">(</span>y_dog<span class="token punctuation">,</span> y_pred_dog<span class="token punctuation">)</span> |
Từ đó sử dụng hàm evaluate_classifier với hai mô hình được huấn luyện với dữ liệu DNA của người chúng ta thu được:
- Sử dụng mô hình Multinomial Naive Bayes
- Dự đoán trên dữ liệu DNA của tinh tinh
- accuracy = 0.993
- precision = 0.994
- recall = 0.993
- f1 = 0.993
- Dự đoán trên dữ liệu DNA của loài chó
- accuracy = 0.926
- precision = 0.934
- recall = 0.926
- f1 = 0.925
- Dự đoán trên dữ liệu DNA của tinh tinh
- Sử dụng mô hình máy vector tựa:
- Dự đoán trên dữ liệu DNA của tinh tinh
- accuracy = 0.968
- precision = 0.971
- recall = 0.968
- f1 = 0.969
- Dự đoán trên dữ liệu DNA của loài chó
- accuracy = 0.493
- precision = 0.803
- recall = 0.493
- f1 = 0.436
- Dự đoán trên dữ liệu DNA của tinh tinh
Từ kết quả trên có thể thấy rằng mô hình SVM chỉ rõ ra rằng loài người và tinh tinh có quan hệ gần hơn rất nhiều so với loài chó khi mà kết quả đáng giá khi dùng mô hình đoán nhận với dữ liệu DNA loài chó thấp hơn rất nhiều khi dùng đoán nhận DNA của tinh tinh.
Kết luận
Tin sinh học – ngành nghiên cứu tích hợp dữ liệu sinh học thông lượng cao và mô hình thống kê thông qua tính toán chuyên sâu, đã thu hút được sự quan tâm lớn trong thời gian gần đây và giải trình tự DNA là một trong những vấn đề cốt lõi của nó. Lượng lớn thông tin thu được từ việc giải trình tự đã giúp chúng ta hiểu sâu hơn và kiến thức cơ bản về sinh vật. Bài viết trên trình bày sơ qua những hiểu biết cơ bản về DNA, giới thiệu một số thư viện được sử dụng để trực quan hóa cũng như xử lý dữ liệu và cuối cùng là một ví dụ nhỏ ứng dụng các phương pháp của khoa học máy tính mà cụ thể hơn là các phương pháp học máy để xử lý và trích rút một số hiểu biết về dữ liệu chuỗi DNA của một số loài.