
Hey yoo,chào mọi người,hôm nay mình sẽ giới thiệu về cách lưu data sau khi Scrape vào mongoDB,chi tiết về project mình đã giới thiệu trong bài trước .
Link
Giới thiệu MongoDB
- MongoDB là một loại cơ sở dữ liệu mã nguồn mở,thuộc loại NoSQL.
- Là một loại cơ sở dữ liệu hướng document,data được lưu vào một nơi gọi là Collection,tương tự như bảng ở các hệ cơ sở dữ liệu như MySQL,PostgreSQL.
- So với RDBMS thì trong MongoDB collection ứng với table, còn document sẽ ứng với row , MongoDB sẽ dùng các document thay cho row trong RDBMS.
Viết code cho pipeline
Chúng ta viết lại code cho pipeline,sử dụng pymongo(Một công cụ giúp tương tác với MongoDB qua Python.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | import pymongo from scrapy.exceptions import DropItem class MongoDBPipeline(object): def __init__(self): connection = pymongo.MongoClient( 'localhost', 27017 ) db = connection["Mac"] self.collection = db["Item"] def process_item(self, item, spider): valid = True for data in item: if not data: valid = False raise DropItem("Missing {0}!".format(data)) if valid: self.collection.insert(dict(item)) return item |
Class MongoDBPipeline khởi tạo với hàm khởi tạo Init ra một đối tượng MongoClient có thuộc tính “localhost” và connect ở port 27017,chúng ta đặt tên cho database là “Mac” và tên của Collection và “Item”
Sau khi thêm đoạn code vừa rồi,ta thay tên của pipeline trong file settings thành :
1 2 3 4 | ITEM_PIPELINES = { 'code9to5mac.pipelines.MongoDBPipeline': 300, } |
Chạy lại project,và sau đó kiểm tra trong MongoDB,ta chạy lệnh.
1 2 | mongo |
sau đó :
1 2 | show dbs |
Ta có thể thấy database Mac đã được tạo
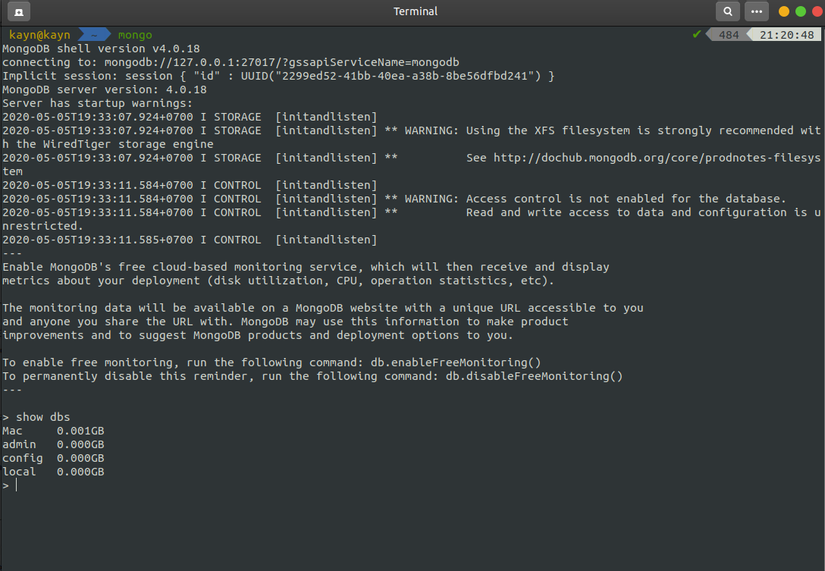
Okay,query nào.Đầu tiên là :
1 2 | use Mac |
và sau đó :
1 2 | db.Item.find().pretty() |
Data đã được lưu như hình dưới :
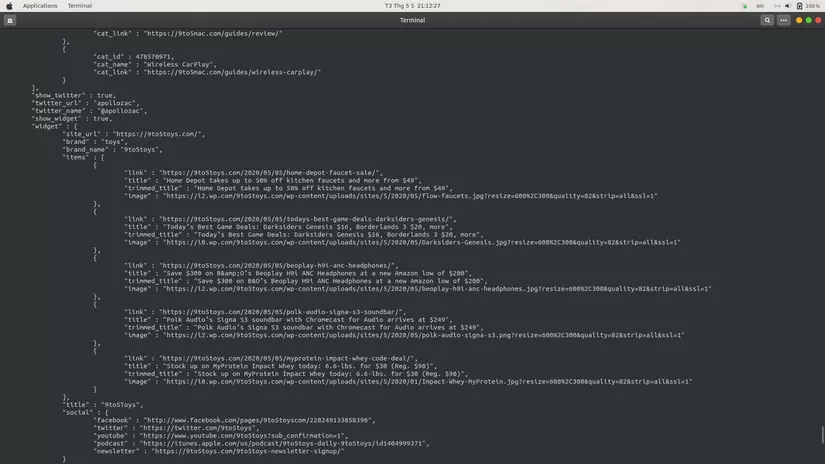
Kết luận
Bài viết này mình đã giới thiệu về cách import data vào trong MongoDB từ Scrapy,bài tiếp theo mình sẽ giới thiệu về Scrapy Cluster,cảm ơn mọi người đã quan tâm.