Ý tưởng
Hiện nay việc mua bán hàng online đang là xu hướng tất yếu của cuộc sống. Nhưng khi chúng ta mua hàng trên Lazada hay Tiki thì liệu chúng ta có an tâm về sản phẩm đó có đúng chất lượng như họ đã quảng cáo không ? Chúng ta không thể đọc hết tất cả bình luận để đánh giá sản phẩm được. Từ ý tưởng đó , mình tạo ra 1 hệ thống sử dụng AI ( trí tuệ nhân tạo ) để đánh giá sản phẩm trên Lazada , Tiki dựa trên bình luận.Từ đó sẽ đưa ra gợi ý cho người dùng có nên mua sản phẩm đó hay không ? , thống kê các bình luận tiêu cực,….
 Trong hệ thống này sẽ sử dụng các kĩ thuật sau đây :
Trong hệ thống này sẽ sử dụng các kĩ thuật sau đây :
- Kĩ thuật craw comment trên Lazada (Tiki ) sử dụng BeautifulSoup, Selenium
- Kĩ thuật xử lí dữ liệu
- Model BERT
- Train model
- Predict
Kĩ thuật craw comment trên Lazada( Tiki) sử dụng BeautifulSoup, Selenium:
1. Use BeautifulSoup :
Thư viện BeautifulSoup là một thư viện của Python cho phép chúng ta lấy dữ liệu từ HTML đơn giản và hiệu quả. Mình sẽ dùng Python 3 và BeautifulSoup 4 để thực hiện việc crawling đơn giản. Trang web được sử dụng là Lazada, việc craw dữ liệu đòi hỏi chúng ta phải biết cấu trúc html của trang web đó.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <span class="token keyword">def</span> <span class="token function">load_url</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Loading url="</span><span class="token punctuation">,</span> url<span class="token punctuation">)</span> page <span class="token operator">=</span> urllib<span class="token punctuation">.</span>request<span class="token punctuation">.</span>urlopen<span class="token punctuation">(</span>url<span class="token punctuation">)</span> soup <span class="token operator">=</span> BeautifulSoup<span class="token punctuation">(</span>page<span class="token punctuation">,</span><span class="token string">"html.parser"</span><span class="token punctuation">)</span> script <span class="token operator">=</span> soup<span class="token punctuation">.</span>find_all<span class="token punctuation">(</span><span class="token string">"script"</span><span class="token punctuation">,</span> attrs<span class="token operator">=</span><span class="token punctuation">{</span><span class="token string">"type"</span><span class="token punctuation">:</span> <span class="token string">"application/ld+json"</span><span class="token punctuation">}</span><span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> script <span class="token operator">=</span> <span class="token builtin">str</span><span class="token punctuation">(</span>script<span class="token punctuation">)</span> script <span class="token operator">=</span> script<span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"</script>"</span><span class="token punctuation">,</span><span class="token string">""</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"<script type="application/ld+json">"</span><span class="token punctuation">,</span><span class="token string">""</span><span class="token punctuation">)</span> csvdata <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token keyword">for</span> element <span class="token keyword">in</span> json<span class="token punctuation">.</span>loads<span class="token punctuation">(</span>script<span class="token punctuation">)</span><span class="token punctuation">[</span><span class="token string">"review"</span><span class="token punctuation">]</span><span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">"reviewBody"</span> <span class="token keyword">in</span> element<span class="token punctuation">:</span> csvdata<span class="token punctuation">.</span>append<span class="token punctuation">(</span><span class="token punctuation">[</span>element<span class="token punctuation">[</span><span class="token string">"reviewBody"</span><span class="token punctuation">]</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">return</span> csvdata |
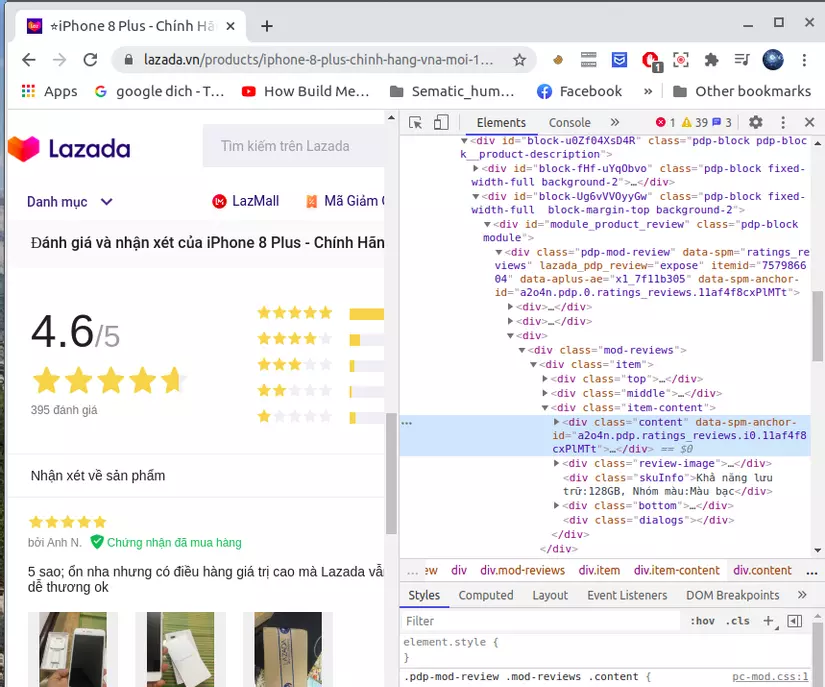
Tuy nhiên việc sử dụng BeautifulSoup chỉ craw được các trang web tĩnh, không thao tác được trên trang web đó. Ví dụ: ta chỉ craw được các comment trên url của trang đó thôi mà không thể next sang bình luận của trang khác ( hay comment của Youtobe chỉ load khi cuộn xuống nên không áp dụng được BeautifulSoup). Để khắc phục hạn chế đó ta sẽ sử dụng Selenium.
2. Use Selenium:
Thư viện selenium là 1 thư viện của python cho phép ta mở 1 trình duyệt (chromedriver) và thao tác trên đó luôn. Ở đây mình sẽ craw comment trên Lazada và Tiki.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | <span class="token keyword">def</span> <span class="token function">load_url_selenium_lazada</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># Selenium</span> driver<span class="token operator">=</span>webdriver<span class="token punctuation">.</span>Chrome<span class="token punctuation">(</span>executable_path<span class="token operator">=</span><span class="token string">'/usr/bin/chromedriver'</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Loading url="</span><span class="token punctuation">,</span> url<span class="token punctuation">)</span> driver<span class="token punctuation">.</span>get<span class="token punctuation">(</span>url<span class="token punctuation">)</span> list_review <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token comment"># just craw 10 page</span> x<span class="token operator">=</span><span class="token number">0</span> <span class="token keyword">while</span> x<span class="token operator"><</span><span class="token number">10</span><span class="token punctuation">:</span> <span class="token keyword">try</span><span class="token punctuation">:</span> <span class="token comment">#Get the review details here</span> WebDriverWait<span class="token punctuation">(</span>driver<span class="token punctuation">,</span><span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">.</span>until<span class="token punctuation">(</span>EC<span class="token punctuation">.</span>visibility_of_all_elements_located<span class="token punctuation">(</span><span class="token punctuation">(</span>By<span class="token punctuation">.</span>CSS_SELECTOR<span class="token punctuation">,</span><span class="token string">"div.item"</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">except</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'No has comment'</span><span class="token punctuation">)</span> <span class="token keyword">break</span> product_reviews <span class="token operator">=</span> driver<span class="token punctuation">.</span>find_elements_by_css_selector<span class="token punctuation">(</span><span class="token string">"[class='item']"</span><span class="token punctuation">)</span> <span class="token comment"># Get product review</span> <span class="token keyword">for</span> product <span class="token keyword">in</span> product_reviews<span class="token punctuation">:</span> review <span class="token operator">=</span> product<span class="token punctuation">.</span>find_element_by_css_selector<span class="token punctuation">(</span><span class="token string">"[class='content']"</span><span class="token punctuation">)</span><span class="token punctuation">.</span>text <span class="token keyword">if</span> <span class="token punctuation">(</span>review <span class="token operator">!=</span> <span class="token string">""</span> <span class="token keyword">or</span> review<span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>review<span class="token punctuation">,</span> <span class="token string">"n"</span><span class="token punctuation">)</span> list_review<span class="token punctuation">.</span>append<span class="token punctuation">(</span>review<span class="token punctuation">)</span> <span class="token comment">#Check for button next-pagination-item have disable attribute then jump from loop else click on the next button</span> <span class="token keyword">if</span> <span class="token builtin">len</span><span class="token punctuation">(</span>driver<span class="token punctuation">.</span>find_elements_by_css_selector<span class="token punctuation">(</span><span class="token string">"button.next-pagination-item.next[disabled]"</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token operator">></span><span class="token number">0</span><span class="token punctuation">:</span> <span class="token keyword">break</span><span class="token punctuation">;</span> <span class="token keyword">else</span><span class="token punctuation">:</span> button_next<span class="token operator">=</span>WebDriverWait<span class="token punctuation">(</span>driver<span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">.</span>until<span class="token punctuation">(</span>EC<span class="token punctuation">.</span>visibility_of_element_located<span class="token punctuation">(</span><span class="token punctuation">(</span>By<span class="token punctuation">.</span>CSS_SELECTOR<span class="token punctuation">,</span> <span class="token string">"button.next-pagination-item.next"</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> driver<span class="token punctuation">.</span>execute_script<span class="token punctuation">(</span><span class="token string">"arguments[0].click();"</span><span class="token punctuation">,</span> button_next<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"next page"</span><span class="token punctuation">)</span> time<span class="token punctuation">.</span>sleep<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">)</span> x <span class="token operator">+=</span><span class="token number">1</span> driver<span class="token punctuation">.</span>close<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">return</span> list_review <span class="token keyword">def</span> <span class="token function">load_url_selenium_tiki</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span> driver<span class="token operator">=</span>webdriver<span class="token punctuation">.</span>Chrome<span class="token punctuation">(</span>executable_path<span class="token operator">=</span><span class="token string">'/usr/bin/chromedriver'</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"Loading url="</span><span class="token punctuation">,</span> url<span class="token punctuation">)</span> driver<span class="token punctuation">.</span>get<span class="token punctuation">(</span>url<span class="token punctuation">)</span> list_review <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token punctuation">]</span> <span class="token comment"># just craw 10 page</span> x<span class="token operator">=</span><span class="token number">0</span> <span class="token keyword">while</span> x<span class="token operator"><</span><span class="token number">10</span><span class="token punctuation">:</span> <span class="token keyword">try</span><span class="token punctuation">:</span> <span class="token comment">#Get the review details here</span> WebDriverWait<span class="token punctuation">(</span>driver<span class="token punctuation">,</span><span class="token number">5</span><span class="token punctuation">)</span><span class="token punctuation">.</span>until<span class="token punctuation">(</span>EC<span class="token punctuation">.</span>visibility_of_all_elements_located<span class="token punctuation">(</span><span class="token punctuation">(</span>By<span class="token punctuation">.</span>CSS_SELECTOR<span class="token punctuation">,</span><span class="token string">"div.review-comment"</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">except</span> <span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'Not has comment!'</span><span class="token punctuation">)</span> <span class="token keyword">break</span> product_reviews <span class="token operator">=</span> driver<span class="token punctuation">.</span>find_elements_by_css_selector<span class="token punctuation">(</span><span class="token string">"[class='review-comment']"</span><span class="token punctuation">)</span> <span class="token comment"># Get product review</span> <span class="token keyword">for</span> product <span class="token keyword">in</span> product_reviews<span class="token punctuation">:</span> review <span class="token operator">=</span> product<span class="token punctuation">.</span>find_element_by_css_selector<span class="token punctuation">(</span><span class="token string">"[class='review-comment__content']"</span><span class="token punctuation">)</span><span class="token punctuation">.</span>text <span class="token keyword">if</span> <span class="token punctuation">(</span>review <span class="token operator">!=</span> <span class="token string">""</span> <span class="token keyword">or</span> review<span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>review<span class="token punctuation">,</span> <span class="token string">"n"</span><span class="token punctuation">)</span> list_review<span class="token punctuation">.</span>append<span class="token punctuation">(</span>review<span class="token punctuation">)</span> <span class="token comment">#Check for button next-pagination-item have disable attribute then jump from loop else click on the next button</span> <span class="token keyword">try</span><span class="token punctuation">:</span> <span class="token comment">#driver.find_element_by_xpath("//li[@class='btn next']/a").click()</span> button_next<span class="token operator">=</span>WebDriverWait<span class="token punctuation">(</span>driver<span class="token punctuation">,</span> <span class="token number">20</span><span class="token punctuation">)</span><span class="token punctuation">.</span>until<span class="token punctuation">(</span>EC<span class="token punctuation">.</span>visibility_of_element_located<span class="token punctuation">(</span><span class="token punctuation">(</span>By<span class="token punctuation">.</span>CSS_SELECTOR<span class="token punctuation">,</span> <span class="token string">"[class = 'btn next']"</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> driver<span class="token punctuation">.</span>execute_script<span class="token punctuation">(</span><span class="token string">"arguments[0].click();"</span><span class="token punctuation">,</span> button_next<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"next page"</span><span class="token punctuation">)</span> time<span class="token punctuation">.</span>sleep<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">)</span> x <span class="token operator">+=</span><span class="token number">1</span> <span class="token keyword">except</span> <span class="token punctuation">(</span>TimeoutException<span class="token punctuation">,</span> WebDriverException<span class="token punctuation">)</span> <span class="token keyword">as</span> e<span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'Load several page!'</span><span class="token punctuation">)</span> <span class="token keyword">break</span> driver<span class="token punctuation">.</span>close<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">return</span> list_review |
Kĩ thuật xử lí dữ liệu
1. Thu thập dữ liệu comment trên Lazada hoặc Tiki
Chúng ta sẽ sử dụng các kĩ thuật craw comment như đã trình bày ở trên để thu thập data. Sau đó gán nhãn cho chúng, ví dụ ở đây chỉ có 2 trạng thái comment : tốt-tích cực- trung gian :0, xấu- không tốt- tiêu cực : 1 ( nếu có nhiều hơn 2 trạng thái thì gán 0,1,2 ,3 ,..).
Ở đây mình có chuẩn bị 1 file data gồm 132 comment đã gán nhãn . data.csv
2. Chuẩn hóa data
Chuẩn hóa data ở đây rất đơn giản : xóa đi các dấu câu như ( . ,? * “, …), xóa đi khoảng trống 2 đầu của comment. Sử dụng regex(Regular Expression)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <span class="token keyword">def</span> <span class="token function">standardize_data</span><span class="token punctuation">(</span>row<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># remove stopword</span> <span class="token comment"># Remove . ? , at index final</span> row <span class="token operator">=</span> re<span class="token punctuation">.</span>sub<span class="token punctuation">(</span><span class="token string">r"[.,?]+$-"</span><span class="token punctuation">,</span> <span class="token string">""</span><span class="token punctuation">,</span> row<span class="token punctuation">)</span> <span class="token comment"># Remove all . , " ... in sentences</span> row <span class="token operator">=</span> row<span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">","</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"."</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">";"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"“"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">":"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"”"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">'"'</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"'"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"!"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"?"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"-"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"?"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> row <span class="token operator">=</span> row<span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">return</span> row |
2. Word tokenizer
Work tokenizer chuyển 1 câu thành các word có nghĩa ( bao gồm cả từ đơn và từ ghép ). Ví dụ

1 2 3 4 5 6 | <span class="token keyword">from</span> underthesea <span class="token keyword">import</span> word_tokenize <span class="token comment"># Tokenizer</span> <span class="token keyword">def</span> <span class="token function">tokenizer</span><span class="token punctuation">(</span>row<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">return</span> word_tokenize<span class="token punctuation">(</span>row<span class="token punctuation">,</span> <span class="token builtin">format</span><span class="token operator">=</span><span class="token string">"text"</span><span class="token punctuation">)</span> |
Model BERT
1. Kiến trúc model BERT
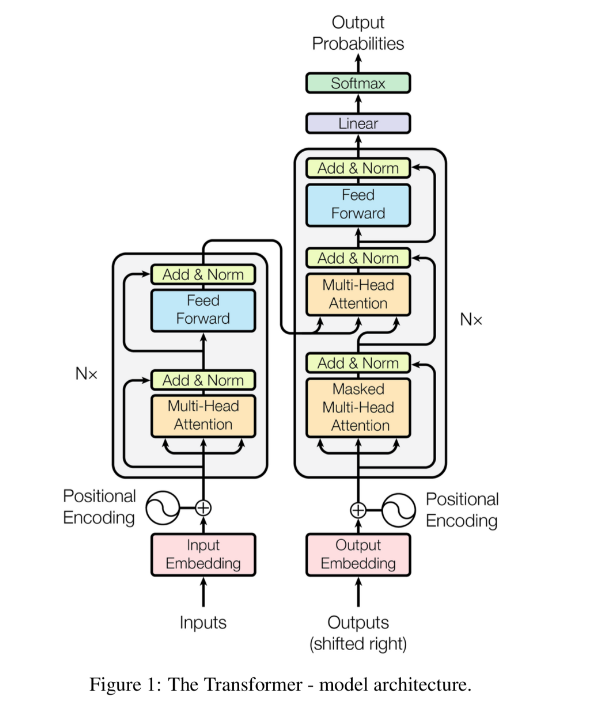
BERT là model hoạt động dựa trên cơ chế attention (chú trọng các đặc trưng ) nó sẽ khắc phục hoàn toàn các nhược điểm của các model như RNN, LSTM,.. ( bị giới hạn bộ nhớ ).
Các bạn có thể đọc tài liệu dưới đây để hiểu rõ về cấu trúc, cách thức hoạt động của model:
- https://phamdinhkhanh.github.io/2020/05/23/BERTModel.html
- https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
- https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Ở series sau mình sẽ ra bài hiểu sâu về kiến trúc model RNN, LSTM, Transformers , BERT,.. so sánh ưu điểm, nhược điểm của mỗi model với nhau.
2. Load data
Import các thư viện cần thiết :
1 2 3 4 5 6 7 8 9 10 11 | <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np <span class="token keyword">import</span> pandas <span class="token keyword">as</span> pd <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>model_selection <span class="token keyword">import</span> train_test_split <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>linear_model <span class="token keyword">import</span> LogisticRegression <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>model_selection <span class="token keyword">import</span> GridSearchCV <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>model_selection <span class="token keyword">import</span> cross_val_score <span class="token keyword">import</span> torch <span class="token keyword">import</span> transformers <span class="token keyword">from</span> transformers <span class="token keyword">import</span> BertModel<span class="token punctuation">,</span> BertTokenizer <span class="token keyword">from</span> sklearn<span class="token punctuation">.</span>externals <span class="token keyword">import</span> joblib |
Load data
1 2 3 4 5 | df <span class="token operator">=</span> pd<span class="token punctuation">.</span>read_csv<span class="token punctuation">(</span><span class="token string">'data_crawler.csv'</span><span class="token punctuation">,</span> delimiter<span class="token operator">=</span><span class="token string">'t'</span><span class="token punctuation">,</span> header<span class="token operator">=</span><span class="token boolean">None</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>df<span class="token punctuation">.</span>shape<span class="token punctuation">)</span> <span class="token comment"># get all rows</span> <span class="token comment"># print(df[0])</span> |
3. Load pretrain model BERT
1 2 3 4 5 6 7 8 9 10 11 12 | <span class="token triple-quoted-string string">''' Load pretrain model/ tokenizers '''</span> model <span class="token operator">=</span> BertModel<span class="token punctuation">.</span>from_pretrained<span class="token punctuation">(</span><span class="token string">'bert-base-uncased'</span><span class="token punctuation">)</span> tokenizer <span class="token operator">=</span> BertTokenizer<span class="token punctuation">.</span>from_pretrained<span class="token punctuation">(</span><span class="token string">'bert-base-uncased'</span><span class="token punctuation">)</span> <span class="token comment">#encode lines</span> tokenized <span class="token operator">=</span> df<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">.</span><span class="token builtin">apply</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token keyword">lambda</span> x<span class="token punctuation">:</span> tokenizer<span class="token punctuation">.</span>encode<span class="token punctuation">(</span>x<span class="token punctuation">,</span> add_special_tokens <span class="token operator">=</span> <span class="token boolean">True</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'encode'</span><span class="token punctuation">,</span>tokenized<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token comment"># decode</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'decode'</span><span class="token punctuation">,</span>tokenizer<span class="token punctuation">.</span>decode<span class="token punctuation">(</span>tokenized<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span> |
4. Fine-tuning model và save model
Fine-tuning có nghĩa là huấn luyện tiếp trọng số (weights, bias ) của model. Kết quả thu được lưu vào file save_model.pkl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | <span class="token comment">#get all label </span> labels <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros<span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>df<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token builtin">len</span><span class="token punctuation">(</span>df<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">:</span> labels<span class="token punctuation">[</span>i<span class="token punctuation">]</span> <span class="token operator">=</span> df<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">[</span>i<span class="token punctuation">]</span><span class="token punctuation">[</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">]</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'labels shape:'</span><span class="token punctuation">,</span> labels<span class="token punctuation">.</span>shape<span class="token punctuation">)</span> <span class="token comment"># get lenght max of tokenized</span> max_len <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> tokenized<span class="token punctuation">.</span>values<span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token builtin">len</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span> <span class="token operator">></span> max_len<span class="token punctuation">:</span> max_len <span class="token operator">=</span> <span class="token builtin">len</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'max len:'</span><span class="token punctuation">,</span> max_len<span class="token punctuation">)</span> <span class="token comment"># if lenght of tokenized not equal max_len , so padding value 0</span> padded <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span><span class="token punctuation">[</span>i <span class="token operator">+</span> <span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token operator">*</span><span class="token punctuation">(</span>max_len<span class="token operator">-</span><span class="token builtin">len</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> tokenized<span class="token punctuation">.</span>values<span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'padded:'</span><span class="token punctuation">,</span> padded<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'len padded:'</span><span class="token punctuation">,</span> padded<span class="token punctuation">.</span>shape<span class="token punctuation">)</span> <span class="token comment">#get attention mask ( 0: not has word, 1: has word)</span> attention_mask <span class="token operator">=</span> np<span class="token punctuation">.</span>where<span class="token punctuation">(</span>padded <span class="token operator">==</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'attention mask:'</span><span class="token punctuation">,</span> attention_mask<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token comment"># Convert input to tensor</span> padded <span class="token operator">=</span> torch<span class="token punctuation">.</span>tensor<span class="token punctuation">(</span>padded<span class="token punctuation">)</span> attention_mask <span class="token operator">=</span> torch<span class="token punctuation">.</span>tensor<span class="token punctuation">(</span>attention_mask<span class="token punctuation">)</span> <span class="token comment"># Train model</span> <span class="token keyword">with</span> torch<span class="token punctuation">.</span>no_grad<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> last_hidden_states <span class="token operator">=</span> model<span class="token punctuation">(</span>padded<span class="token punctuation">,</span> attention_mask <span class="token operator">=</span>attention_mask<span class="token punctuation">)</span> <span class="token comment"># print('last hidden states:', last_hidden_states)</span> features <span class="token operator">=</span> last_hidden_states<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">]</span><span class="token punctuation">.</span>numpy<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'features:'</span><span class="token punctuation">,</span> features<span class="token punctuation">)</span> X_train<span class="token punctuation">,</span> X_test<span class="token punctuation">,</span> y_train<span class="token punctuation">,</span> y_test <span class="token operator">=</span> train_test_split<span class="token punctuation">(</span>features<span class="token punctuation">,</span> labels<span class="token punctuation">)</span> cl <span class="token operator">=</span> LogisticRegression<span class="token punctuation">(</span><span class="token punctuation">)</span> cl<span class="token punctuation">.</span>fit<span class="token punctuation">(</span>X_train<span class="token punctuation">,</span> y_train<span class="token punctuation">)</span> <span class="token comment"># Save model</span> joblib<span class="token punctuation">.</span>dump<span class="token punctuation">(</span>cl<span class="token punctuation">,</span> <span class="token string">'save_model.pkl'</span><span class="token punctuation">)</span> sc <span class="token operator">=</span> cl<span class="token punctuation">.</span>score<span class="token punctuation">(</span>X_test<span class="token punctuation">,</span> y_test<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'score:'</span><span class="token punctuation">,</span> sc<span class="token punctuation">)</span> |
Predict
1 . Nhập đường dẫn url đến của sản phẩm cần đánh giá
Thay đổi url tới sản phẩm cần đánh giá :
1 2 | predict<span class="token punctuation">(</span>url <span class="token operator">=</span> <span class="token string">'https://www.lazada.vn/products/iphone-8-plus-chinh-hang-vna-moi-100-chua-kich-hoat-chua-qua-su-dung-bao-hanh-12-thang-tai-ttbh-apple-tra-gop-lai-suat-0-qua-the-tin-dung-man-hinh-retina-hd-55-inch-3d-touch-chip-a11-ios11-i757986604-s1985088475.html?spm=a2o4n.searchlistcategory.list.4.46d0bdd5OzWEVE&search=1'</span><span class="token punctuation">)</span> |
2. Tiền xử lí, word tokenizer
- Chuẩn hóa data, tokenizer:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | <span class="token keyword">def</span> <span class="token function">standardize_data</span><span class="token punctuation">(</span>row<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># remove stopword</span> <span class="token comment"># Remove . ? , at index final</span> row <span class="token operator">=</span> re<span class="token punctuation">.</span>sub<span class="token punctuation">(</span><span class="token string">r"[.,?]+$-"</span><span class="token punctuation">,</span> <span class="token string">""</span><span class="token punctuation">,</span> row<span class="token punctuation">)</span> <span class="token comment"># Remove all . , " ... in sentences</span> row <span class="token operator">=</span> row<span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">","</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"."</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">";"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"“"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">":"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"”"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">'"'</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"'"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"!"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"?"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> <span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"-"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span><span class="token punctuation">.</span>replace<span class="token punctuation">(</span><span class="token string">"?"</span><span class="token punctuation">,</span> <span class="token string">" "</span><span class="token punctuation">)</span> row <span class="token operator">=</span> row<span class="token punctuation">.</span>strip<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">return</span> row <span class="token comment"># Tokenizer</span> <span class="token keyword">def</span> <span class="token function">tokenizer</span><span class="token punctuation">(</span>row<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">return</span> word_tokenize<span class="token punctuation">(</span>row<span class="token punctuation">,</span> <span class="token builtin">format</span><span class="token operator">=</span><span class="token string">"text"</span><span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">analyze</span><span class="token punctuation">(</span>result<span class="token punctuation">)</span><span class="token punctuation">:</span> bad <span class="token operator">=</span> np<span class="token punctuation">.</span>count_nonzero<span class="token punctuation">(</span>result<span class="token punctuation">)</span> good <span class="token operator">=</span> <span class="token builtin">len</span><span class="token punctuation">(</span>result<span class="token punctuation">)</span> <span class="token operator">-</span> bad <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"No of bad and neutral comments = "</span><span class="token punctuation">,</span> bad<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">"No of good comments = "</span><span class="token punctuation">,</span> good<span class="token punctuation">)</span> <span class="token keyword">if</span> good<span class="token operator">></span>bad<span class="token punctuation">:</span> <span class="token keyword">return</span> <span class="token string">"Good! You can buy it!"</span> <span class="token keyword">else</span><span class="token punctuation">:</span> <span class="token keyword">return</span> <span class="token string">"Bad! Please check it carefully!"</span> |
- Processing data:
1 2 3 4 5 6 7 8 9 10 11 12 13 | <span class="token keyword">def</span> <span class="token function">processing_data</span><span class="token punctuation">(</span>data<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 1. Standardize data</span> data_frame <span class="token operator">=</span> pd<span class="token punctuation">.</span>DataFrame<span class="token punctuation">(</span>data<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'data frame:'</span><span class="token punctuation">,</span> data_frame<span class="token punctuation">)</span> data_frame<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">=</span> data_frame<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">.</span><span class="token builtin">apply</span><span class="token punctuation">(</span>standardize_data<span class="token punctuation">)</span> <span class="token comment"># 2. Tokenizer</span> data_frame<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">=</span> data_frame<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">.</span><span class="token builtin">apply</span><span class="token punctuation">(</span>tokenizer<span class="token punctuation">)</span> <span class="token comment"># 3. Embedding</span> X_val <span class="token operator">=</span> data_frame<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token keyword">return</span> X_val |
3. Đưa các comment vào model để predict
- Đưa các comment sau khi được xử lí vào model:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | <span class="token keyword">def</span> <span class="token function">load_pretrainModel</span><span class="token punctuation">(</span>data<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token triple-quoted-string string">''' Load pretrain model/ tokenizers Return : features '''</span> model <span class="token operator">=</span> BertModel<span class="token punctuation">.</span>from_pretrained<span class="token punctuation">(</span><span class="token string">'bert-base-uncased'</span><span class="token punctuation">)</span> tokenizer <span class="token operator">=</span> BertTokenizer<span class="token punctuation">.</span>from_pretrained<span class="token punctuation">(</span><span class="token string">'bert-base-uncased'</span><span class="token punctuation">)</span> <span class="token comment">#encode lines</span> tokenized <span class="token operator">=</span> data<span class="token punctuation">.</span><span class="token builtin">apply</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token keyword">lambda</span> x<span class="token punctuation">:</span> tokenizer<span class="token punctuation">.</span>encode<span class="token punctuation">(</span>x<span class="token punctuation">,</span> add_special_tokens <span class="token operator">=</span> <span class="token boolean">True</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># get lenght max of tokenized</span> max_len <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> tokenized<span class="token punctuation">.</span>values<span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token builtin">len</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span> <span class="token operator">></span> max_len<span class="token punctuation">:</span> max_len <span class="token operator">=</span> <span class="token builtin">len</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'max len:'</span><span class="token punctuation">,</span> max_len<span class="token punctuation">)</span> <span class="token comment"># if lenght of tokenized not equal max_len , so padding value 0</span> padded <span class="token operator">=</span> np<span class="token punctuation">.</span>array<span class="token punctuation">(</span><span class="token punctuation">[</span>i <span class="token operator">+</span> <span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token operator">*</span><span class="token punctuation">(</span>max_len<span class="token operator">-</span><span class="token builtin">len</span><span class="token punctuation">(</span>i<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> tokenized<span class="token punctuation">.</span>values<span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'padded:'</span><span class="token punctuation">,</span> padded<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'len padded:'</span><span class="token punctuation">,</span> padded<span class="token punctuation">.</span>shape<span class="token punctuation">)</span> <span class="token comment">#get attention mask ( 0: not has word, 1: has word)</span> attention_mask <span class="token operator">=</span> np<span class="token punctuation">.</span>where<span class="token punctuation">(</span>padded <span class="token operator">==</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">,</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'attention mask:'</span><span class="token punctuation">,</span> attention_mask<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token comment"># Convert input to tensor</span> padded <span class="token operator">=</span> torch<span class="token punctuation">.</span>tensor<span class="token punctuation">(</span>padded<span class="token punctuation">)</span> attention_mask <span class="token operator">=</span> torch<span class="token punctuation">.</span>tensor<span class="token punctuation">(</span>attention_mask<span class="token punctuation">)</span> <span class="token comment"># Load model</span> <span class="token keyword">with</span> torch<span class="token punctuation">.</span>no_grad<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> last_hidden_states <span class="token operator">=</span> model<span class="token punctuation">(</span>padded<span class="token punctuation">,</span> attention_mask <span class="token operator">=</span>attention_mask<span class="token punctuation">)</span> <span class="token comment"># print('last hidden states:', last_hidden_states)</span> features <span class="token operator">=</span> last_hidden_states<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token punctuation">:</span><span class="token punctuation">]</span><span class="token punctuation">.</span>numpy<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'features:'</span><span class="token punctuation">,</span> features<span class="token punctuation">)</span> <span class="token keyword">return</span> features |
- Predict:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <span class="token keyword">def</span> <span class="token function">predict</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 1. Load URL and print comments</span> <span class="token keyword">if</span> url<span class="token operator">==</span> <span class="token string">""</span><span class="token punctuation">:</span> url <span class="token operator">=</span> <span class="token string">"https://tiki.vn/dien-thoai-samsung-galaxy-m31-128gb-6gb-hang-chinh-hang-p58259141.html"</span> data <span class="token operator">=</span> load_url_selenium_lazada<span class="token punctuation">(</span>url<span class="token punctuation">)</span> <span class="token comment"># data = load_url_selenium_tiki(url)</span> data <span class="token operator">=</span> processing_data<span class="token punctuation">(</span>data<span class="token punctuation">)</span> features <span class="token operator">=</span> load_pretrainModel<span class="token punctuation">(</span>data<span class="token punctuation">)</span> <span class="token comment"># 2. Load weights</span> model <span class="token operator">=</span> joblib<span class="token punctuation">.</span>load<span class="token punctuation">(</span><span class="token string">'save_model.pkl'</span><span class="token punctuation">)</span> <span class="token comment"># 3. Result</span> result <span class="token operator">=</span> model<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>features<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>result<span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>analyze<span class="token punctuation">(</span>result<span class="token punctuation">)</span><span class="token punctuation">)</span> |
4. Kết quả
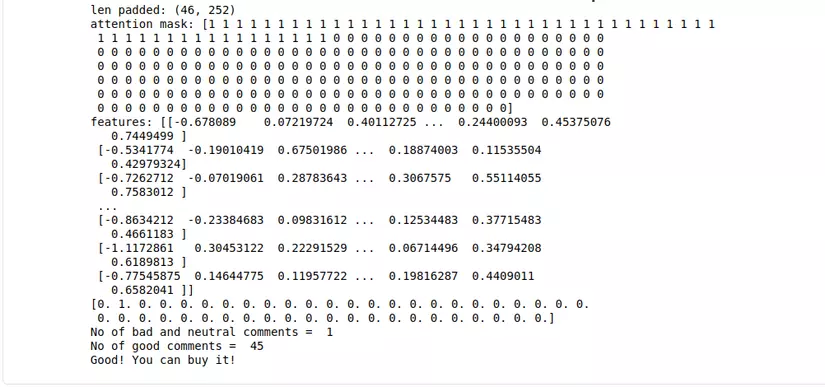
Qua kết quả trên ta thấy có 45 comments tốt về sản phẩm, 1 comment xấu. Nên chúng ta có thể mua nó
Kết luận
Toàn bộ code : https://github.com/trungtruc123/Review_Product_Lazada
Chúng ta có thể sử dụng các model khác như SVM, logistic Regression thay cho BERT. Nhưng độ chính xác của model SVC ~ 0.84, còn model BERT ~ 0.91 ( tại sao lại vậy ? đơn giản vì model BERT kiến trúc phức tạp hơn và sử dụng nhiều trick như attention ,…)
Thông qua project nhỏ này, chúng ta nắm rõ 1 số phương pháp kĩ thuật cơ bản trong xử lí ngôn ngữ tự nhiên, cũng như cách craw dữ liệu trên web, sử dụng model BERT,…. Bên cạnh đó chúng ta có thể áp dụng nhiều hơn 2 trạng thái comment như : bùn, vui, giận dữ, khó chịu , thỏa mãn, thất vọng ,… và viết thành 1 project hoàn chỉnh để làm đề tài tốt nghiệp, luận văn tốt nghiệp,..
Bài viết này còn sơ xài do mình hơi bận, nếu các bạn thấy hay để lại comment mình sẽ ra series 2 hướng dẫn viết hệ thống này một cách hoàn chỉnh.
Cảm ơn các bạn đã tới đây ! Hẹn các bạn trong series 2