1. Introduce
Image Segmentation – bài toán gán nhãn/label cho pixel luôn là một chủ đề hot trong Computer Vision – Deep learning. Trong đó, Image Segmentation chia làm 2 nhánh:
- Semantic segment: gán nhãn từng pixel với label là class mà đối tượng thuộc về.
- Instance Segment: là bài toán nâng cao hơn semantic segment – có thể phát hiện, phân biệt từng đối tượng riêng lẻ trong 1 nhóm các đối tượng cùng lớp.
Nếu định nghĩa hơi khó hiểu, bạn có thể nhìn ảnh dưới đây:

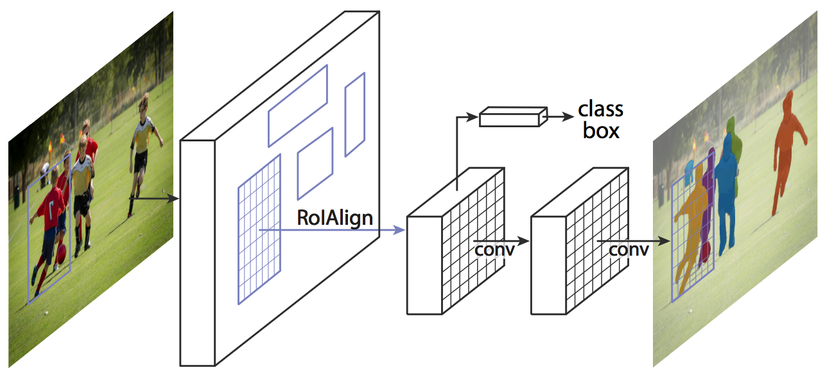
Hầu hết các phương pháp Instance Segment đang được sử dụng phổ biến hiện nay được xây dựng dựa trên các two-stage detector. Để dễ phân biệt, two-stage detector phổ biến là Fast RCNN, Faster RCNN; còn single-stage hay one-stage detector phổ biến là Yolo, SSD, Restina . Điển hình cho hướng đi two-stage based là Mask RCNN – hiện nay đang được sử dụng rất phổ biến trong cộng đồng bởi độ chính xác cao. Hãy quan sát hình dưới đây để hiểu rõ hơn về Mask RCNN. Tuy có độ chính xác cao nhưng nó vẫn có nhược điểm:
- Kiến trúc 2-stage khiến tốc độ chậm
- Có các bước ROI pool (ROI-align): đưa các vùng ROI vào model để predict ra mask, luồng xử lí “tuần tự”, rất khó để song song hoá tính toán để tăng tốc.
Yolact: Để giải quyết nhược điểm nêu trên, tác giả đã đề xuất YOLACT với kiến trúc one-stage, nâng cao tốc độ bằng cách chia model thành 2 sub module song song. Việc sinh ra instance segment cho từng đối tượng dựa trên 1 tập các Prototype Mask cùng 1 tập các hệ số tương ứng với từng đối tượng. Nghe vẫn khó hiểu nhỉ, hãy đọc phần tiếp theo để hiểu rõ hơn.
2. Yolact: Real-time Instance Segmentation
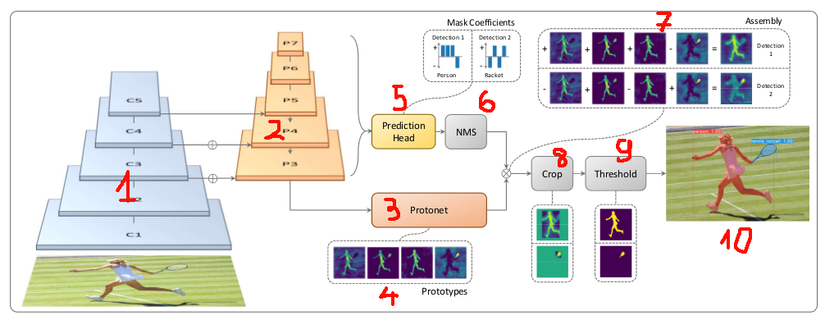
Trước hết, hãy quan sát hình dưới đây để có cái nhìn tổng quan về kiến trúc và luồng xử lí. Để dễ dàng mô tả mình đã đánh dấu từng phần trong hình.
YOLACT được xây dựng trên kiến trúc (backbone) của Restina: ResNet + FPN (Feature Pyramid Network) – tương ứng với 2 phần “kim tự tháp” 1 và 2 trong hình. Sau đó việc Instance Segment được tách thành 2 nhánh song song, đơn giản và riêng biệt: nhánh prototype net (phần 3) và nhánh prediction head (phần 5). Việc phân chia thành 2 nhánh thế này giúp tối ưu và song song hoá tính toán, giúp YOLACT đạt được tốc độ Real-time, nhanh gấp 3 – 5 lần Mask RCNN
Prototype net là 1 mạng FCN (Fully Convolution), trả về output là các Prototype Mask (phần 4). Các prototype mask này được coi là các thành phần cơ bản, khi kết hợp với các tỷ lệ khác nhau sẽ cho ra các mask tương ứng cho từng đối tượng. Để dễ hiểu, bạn hãy nghĩ prototype mask giống như 1 tập nguyên liệu: rau muống, tỏi, mắm, muối, nước lọc … Khi kết hợp (chế biến) các nguyên liệu này với tỷ lệ thích hợp, kết quả mong muốn là đĩa rau muống xào – là phần 10 trong ảnh.
Prediction head làm việc còn lại: tìm ra tỷ lệ kết hợp nguyên liệu cho từng đối tượng. Module này sẽ detect vị trí / bounding box các đối tượng. Với từng đối tượng, mạng sẽ predict ra 1 tập hệ số. Quan sát trong hình, ta thấy prediction head xác định được 2 object là Person, Racket cùng 2 tập hệ số tương ứng là [1,1,1,−1][1,1,1, -1 ][1,1,1,−1] và [−1,1−1,1][-1,1-1,1][−1,1−1,1].
Các Bounding box từ bước 5 được đưa qua Non-maximum suppression (bước 6) để loại đi các Bounding box bị trùng và có xác suất thấp.
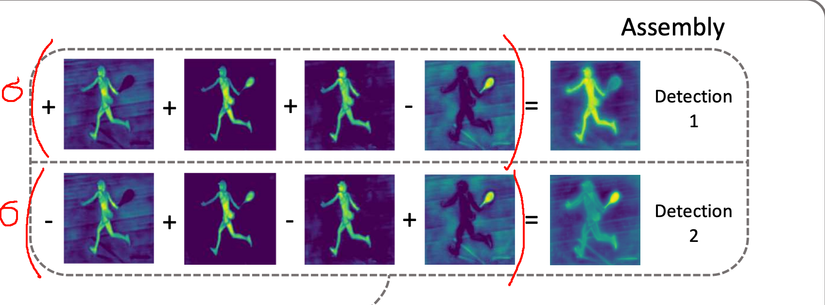
Để sinh ra Mask cho 2 đối tượng Person và Racket tại bước 7, ta cộng Prototype Mask theo hệ số của từng đối tượng. Giả sử có 4 prototype mask là M1, M2, M3, M4. Như vậy:
- Mask_person = (1∗M1+1∗M2+1∗M3−1∗M4)(1*M1 + 1*M2 + 1*M3 – 1*M4)(1∗M1+1∗M2+1∗M3−1∗M4)
- Mask_racket = (−1∗M1+1∗M2−1∗M3+1∗M4)(-1*M1 + 1*M2 – 1*M3 + 1*M4)(−1∗M1+1∗M2−1∗M3+1∗M4)
Như vậy, với cùng nguyên liệu là các prototype mask nhưng với tỷ lệ khác nhau và loại bỏ các giá trị nằm ngoài bounding box, ta đã thu được 2 mask cho 2 đối tượng person và racket tại bước 8. Tại bước 9, sử dụng các thuật toán xử lí ảnh (threshold) để tăng độ chính xác, loại nhiễu cho các mask. Kết hợp các mask của từng đối tượng với nhau ta được mask cho toàn ảnh (phần 10). Và đó là luồng xử lí của Yolact, giờ bạn đã hiểu hơn rồi, mình sẽ đi vào chi tiết từng module.
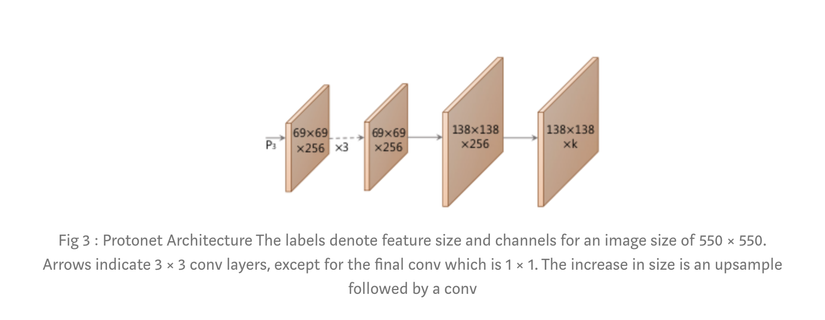
2.1 Prototype Net
Prototype net là 1 Full-Conv xây dựng trên các feature FPN-P3 của FPN, trả về K prototype mask có kích thước được upsample gấp đôi.
Số K không phụ thuộc vào số class, mà được tối ưu và chọn sau nhiều lần thử nghiệm. Một điểm lưu ý rằng không phải K càng lớn thì chất lượng output càng tốt, vì chỉ 1 số Prototype Mask đầu có ảnh hưởng tới Mask của các object, số Prototype mask dư thừa còn lại không có tác động nhiều, chỉ là nhiễu.Trong quá trình thử nghiệm, tác giả nhận thấy K = 32 cho chất lượng tốt nhất.
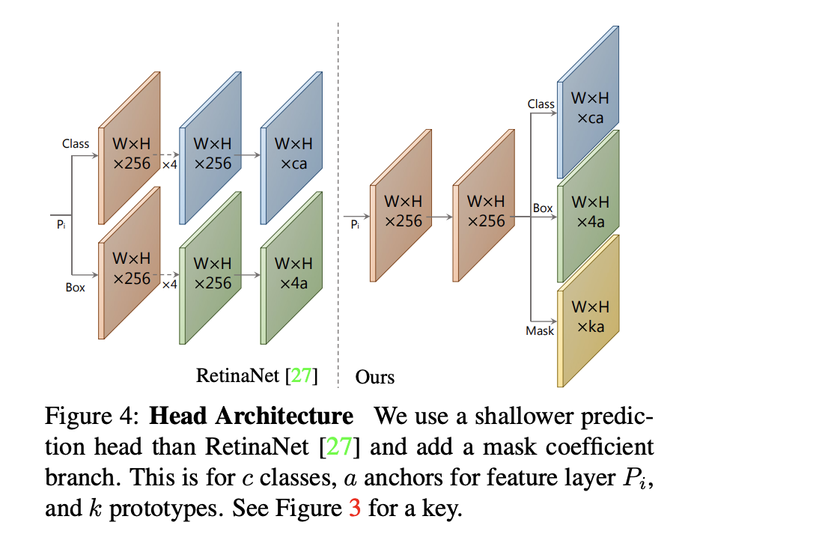
2.2 Prediction head, Mask Coefficients
Như đã nói qua ở phần trên, prediction head có nhiệm vụ detect các object và các tập hệ số tương ứng với từng object. Ta gọi tập hệ số này là mask coeficients.
Quan sát vào RestinaNet dưới đây, các object detector như Faster-RCNN, RestinaNet thường tách thành 2 nhánh predict:
- Predict C class confidences – phân bố xác suất để phân loại
- Predict bounding 4 offset cho mỗi anchor box. (Tại mỗi vị trí pixel, model phải predict a Bbox-offsets tương ứng a Anchor box)
Yolact thêm 1 nhánh thứ 3 để predict ra K mask coeficients cho từng anchor box, nhánh này có activation là Tanh function, cho phép giá trị thuộc khoảng [−1,1][-1, 1][−1,1]. Như vậy, thay vì chỉ predict ra 4 + C số tại mỗi anchor box, model phải predict 4 + C + K số.
2.3 Kết hợp prototype mask và mask coeficients.
Sau khi trải qua Non-maximum suppression, ta đã loại bỏ được các bbox bị trùng, lựa ra được các bbox tốt nhất cùng mask coeficients tương ứng. Để sinh ra Mask cho từng object, thuật toán sẽ “kết hợp tuyến tính” K mask prototypes với K mask coeficients (như đã mô tả ở trên). Sau đó đưa qua hàm sigmoid, cuối cùng sẽ thu được các Mask cho từng object.
2.4 Một vài bổ sung
Trong paper, tác giả có đề xuất 1 phương pháp Fast NMS, tức Fast Non maximum suppression – 1 phương pháp tính toán kiểu ma trận giúp tăng tốc độ cho NMS 1 cách đáng kể. Do hơi phức tạp và khó diễn tả nên mình xin phép không mô tả trong bài này :p
3. Kết luận
Như vậy qua bài viết này, mình đã cung cấp cho bạn cái nhìn tổng quan về Yolact – 1 phương pháp Instance segment real-time rất hữu hiệu và đang trở lên phổ biến.
Github: YOLACT real-time instance segmentation.
Ngoài lề:
- Mình mới lập group Vietnam AI Link Sharing Community nhằm xây dựng 1 cộng đồng chuyên chia sẻ, trao đổi chuyên sâu về các paper, thuật toán, author, competition hay. Tại đây cộng đồng sẽ được tiếp cận các kiến thức chuyên sâu hơn, không bị loãng, trôi, lack mất bài viết trong các group thường thấy.
- Ad sẽ không duyệt các bài mang tính hỏi đáp cơ bản như “tại sao code em không chạy”, “em muốn”, “em phải làm thế nào” để tránh loãng bài, giúp mọi người dễ dàng tìm được bài đăng có chất lượng . Rất mong được mọi người tham gia và xây dựng cộng đồng.
- Link: Vietnam AI Link Sharing Community