Giới thiệu đầu

Xin chào mọi người, hôm nay mình sẽ giới thiệu các bạn bài toán trigger word hay wake up word.
Vậy trigger word là gì? Trigger word là một tín hiệu kích hoạt thiết bị bằng giọng nói giống như “Ok Google” – “Hey Google” trong trợ lý ảo của Google, “Alexa” trợ lý ảo Alexa của Amazon. Còn đây là demo mình đã thực hiện tạo ra mô hình trigger word của riêng mình, mời các bạn cùng xem:
OK, chúng ta hãy cùng đi tìm hiểu về trigger word nào!!!!!!!
Tại sao phải sử dụng trigger word:
- Trigger word như một lời gọi tên, để thiết bị biết là người dùng đang gọi đến thiết bị đó chứ không phải người khác hay thiết bị khác
- Hạn chế request liên tục các mẫu giọng nói lên trên server
- Phần nào đó đảm bảo được quyền riêng tư của người dùng
Các yêu cầu của một module trigger word:
- Gọn nhẹ, chạy được trên các phần cứng cấu hình thấp
- Tín hiệu gọi cần gắn ngọn, dễ nói
- Tín hiệu gọi đặc trưng, tránh bắt gặp trong câu nói hằng ngày
- Độ chính xác cao, detect được giọng nam nữ, các độ tuổi khác nhau, vùng miền khác nhau
Dựa theo yêu cầu trên ta xác định đây là bài toán phân loại 2 lớp: positive và negative.
Lựa chọn phương pháp
Phương án 1: Sử dụng api của “Snowboy hotword detection” tham khảo tại trang: https://snowboy.kitt.ai/
Ưu điểm: api này đã build sẵn công cụ, việc của mình là đưa dữ liệu vào và nhận lấy model
Nhược điểm: Để có download được model “xịn” ta cần có ít nhất 500 người dùng đóng góp dữ liệu với dữ liệu tiếng anh và ít nhất 2000 người dùng đóng góp dữ liệu với dữ liệu các tiếng khác
Ngoài ra, mình vẫn có thể có download model test chỉ với 3 mẫu dữ liệu cá nhân. Nhưng hiệu quả của model với 3 mẫu dữ này không cao. Do vậy mình không chọn phương án này.
Nhưng nếu bạn muốn dùng thử thì có thể làm theo các bước như sau:
Bước 1: Vào trang https://snowboy.kitt.ai/
Bước 2: Tạo một tài khoản login
Bước 3: Sau khi đăng nhập vào, các bạn sẽ thấy giao diện như thấy này:
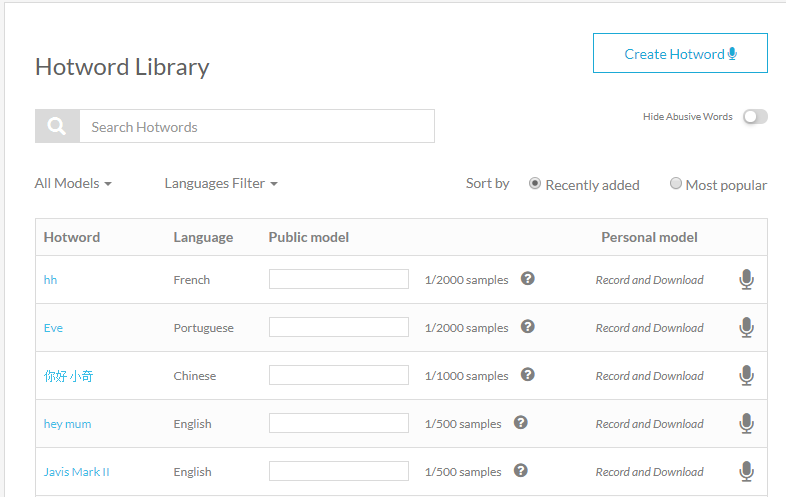
Như các bạn thấy, ở bên dưới là danh sách mà nhiều người dùng đã tạo model trigger word của riêng mình, với những model đã đủ số lượng sample thì bạn có thể download về để sử dụng. Với những model chưa đủ sample bạn có thể vào để đóng góp dữ liệu. Để tạo model của riêng mình, các bạn click vào Button: Create Hotword
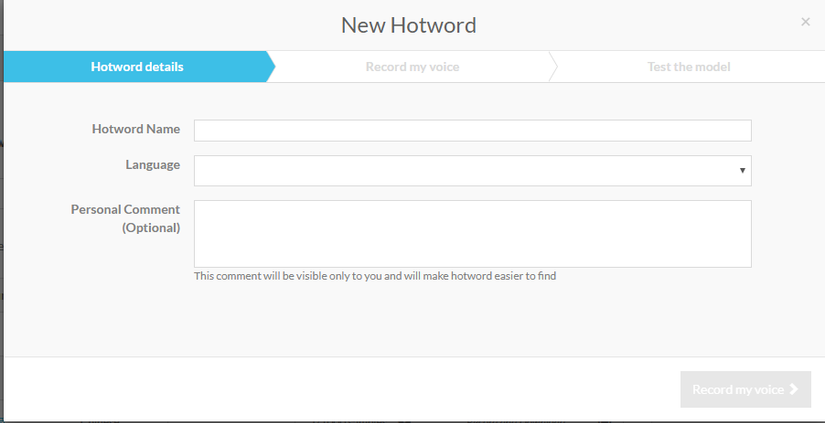
Ở trường Hotword Name các bạn điền tên model, nên đặt tên trùng với từ khóa cần gọi, để các user khác biết và đóng góp dữ liệu. Tại trường language, các bạn chọn ngôn ngữ dùng để tạo model, nếu ngôn ngữ bạn dùng không có trong danh sách, các bạn chọn mục other. Tiếp theo các bạn viết một vài mô tả để người user khác hiểu và cũng để tiện tìm kiếm.
Bước 4: Record mẫu data:
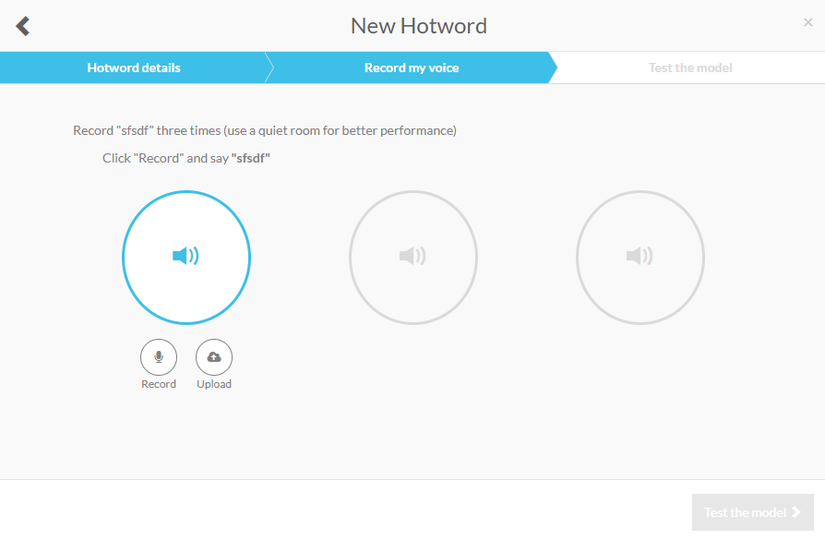
Một user được đóng góp 3 mẫu dữ liệu, các bạn thu đủ 3 mẫu thì mới test và download model được nhé
Phương án 2: Làm theo phương pháp mà bác Andrew Ng dạy trong bài giảng về deeplearning.

Theo phương pháp này thì trên mỗi frame của 1 mẫu dữ liệu đầu vào, ta sẽ phân loại được frame đó có thuộc nhãn positive hay negative
Cấu trúc mô hình deep learning theo phương án này như sau:
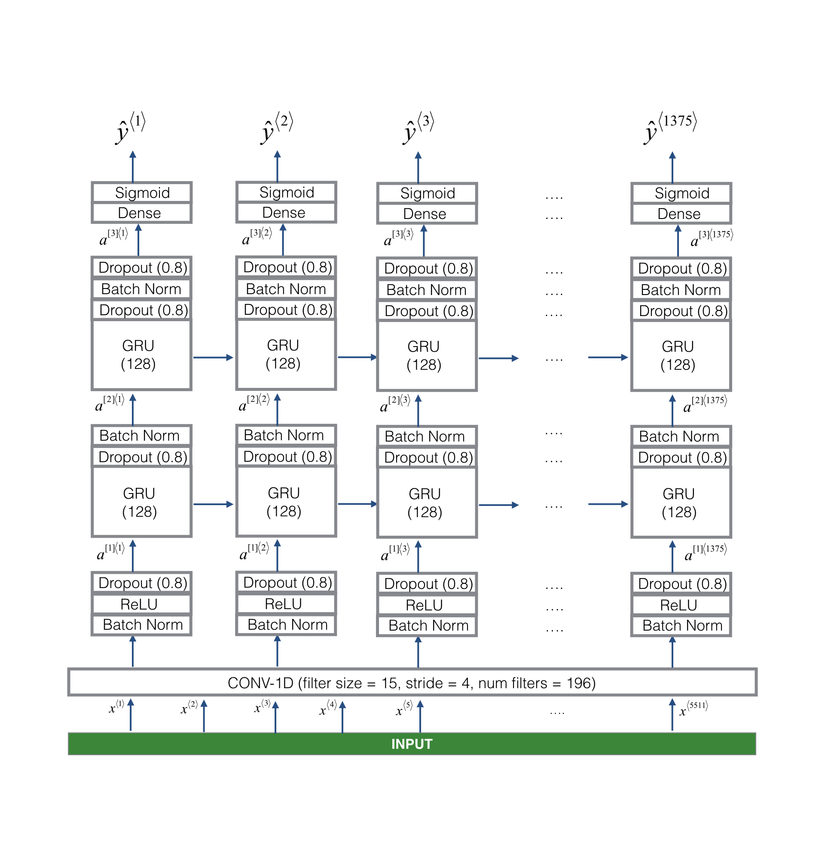
Mô hình này có hơn 500000 parameter, sử dụng một layer Convolution 1D ở đầu vào và hai layer GRU, theo mình cấu trúc mô hình này vẫn còn khá lớn để chạy trên thiết bị phần cứng thấp.
Phương án 3: Build model với kiến trúc đơn giản
Chuẩn bị dữ liệu
Để thực hiện bước này các bạn cần thu thập dữ liệu của 3 loại:
- Positive: dữ liệu audio từ khóa để kích hoạt
- Negative: dữ liệu audio giọng nói không phải từ để kích hoạt
- Background: âm thanh của môi trường nơi ta sẽ đặt thiết bị
Giai đoạn thu thập dữ liệu sẽ tốn thời gian và nhàm chán. Thực tế mình đã dùng điện thoại để đi “ăn mày” dữ liệu từ các bạn của mình. Cố gắng thu thập các dữ liệu positive càng đa dạng càng tốt, nhờ mọi người nói với ngữ điệu khác nhau. Với dữ liệu negative, mình nhờ các bạn đọc một đoạn văn bất kì không chứa từ khóa kích hoạt. Nếu thu thập negative từ những bạn cho dữ liệu positive thì ta có tập dữ liệu rất tốt. Ngoài ra ta có thể thu thập dữ liệu negative từ các audio đọc truyện, thời sự ….
Với dữ liệu cho cho background thì dễ dàng thu thập hơn, nếu thiết bị của bạn đặt ở 1 không gian cố định, ta nên thu âm ở nơi đó để làm background.
Tiền xử lý
Bước 1: Giảm nhiễu trắng:
Nhiễu trắng là nhiễu do thiết bị thu âm sinh ra, nhiễu trắng nhiều hay ít phụ thuộc vào chất lượng microphone và việc cài đặt độ nhạy của microphone.
Để giảm nhiễu trắng, mình ghi âm 1 đoạn audio trong môi trường yên tĩnh để làm mẫu. Mẫu này sẽ như 1 mặt nạ ngưỡng, để khử nhiễu trong các audio sau này. Chú ý, khi ta đổi thiết bị thu âm, hay cài đặt độ nhạy microphone khác đi thì nên thu âm lại file này. Về thuật toán giảm nhiễu các bạn tham khảo tại đây để biết thêm nhé: https://github.com/timsainb/noisereduce
Code thực hiện giảm nhiễu như sau:
1 2 3 4 5 6 7 8 | import noisereduce as nr import librosa y, sr = librosa.load("positive.wav") noise, sr = librosa.load("audio/train_sunnie/test/noise.wav") reduced_noise = nr.reduce_noise(audio_clip=y, noise_clip=noise, verbose=False) librosa.output.write_wav("positive_reducenoise.wav", reduced_noise, sr, norm=False) |
Bước 2: Chia file dữ liệu sau khi giảm nhiễu từng mẫu độ dài mình đặt là 1.5 giây
Bước 3: Sinh thêm dữ liệu với data hiện có
Do dữ liệu cho nhãn positive của mình có rất ít, nên việc sinh thêm dữ liệu cho nhãn này rất cần thiết. Mình sử dụng các phương pháp sau:
- Shifting Time: Dịch chuyển tín hiệu sang trái, phải
- Changing Pitch: Thay đổi cao độ
- Changing Speed: Thay đổi tốc độ
Code thực hiện:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | import numpy as np import librosa def shifting(data): shift_max = int(len(data)*0.05) shift_min = int(len(data)*0.02) shift = np.random.randint(shift_min, shift_max) if np.random.randint(0,2,1)[0]: shift = -shift augmented_data = np.roll(data, shift) return augmented_data def change_pitch(data, sampling_rate, pitch_factor): return librosa.effects.pitch_shift(data, sampling_rate, pitch_factor) def change_speed(data, speed_factor): return librosa.effects.time_stretch(data, speed_factor) path_voice = "positive/" path_save = "positive_aug/" for i in range(5): for file_name in tqdm_notebook(os.listdir(path_voice)): try: y, sr = librosa.load(path_voice+file_name, sr=16000) y = shifting(y) rate = np.random.uniform(-3, 3, 1)[0] y = change_pitch(y, sr, rate) rate = np.random.uniform(0.8, 1.5, 1)[0] y = change_speed(y, rate) librosa.output.write_wav(path_save + str(np.random.randint(1000000)) + file_name, y, sr) except Exception as e: print(e) print("Num sample: ", len(os.listdir(path_save))) |
Trích xuất đặc trưng
Dữ liệu âm thanh có nhiều hướng để trích xuất dữ liệu và tùy thuộc vào từng bài toán. Với bài toán này mình chọn trích xuất dữ liệu dạng phổ melspectrogram.
Code trích xuất dữ liệu melspectrogram:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | import numpy as np import librosa def extract_feature(path_file): y, sr = librosa.load(path_file, sr=16000) sr = 16000 num_step = int(sr*1.5) if len(y) > num_step: y = y[0: num_step] pad_width = 0 else: pad_width = num_step - len(y) y = np.pad(y, (0, int(pad_width)), mode='constant') D = np.abs(librosa.core.stft(y=y, n_fft=2048))**2 S = librosa.feature.melspectrogram(S=D, sr=sr, n_fft=256) S_dB = librosa.power_to_db(S, ref=np.max) return S_dB.T path_positive = "positive_aug/" path_negative = "negative_aug/" sample_data = extract_feature("test_1.wav") num_sample = len(os.listdir(path_negative)) + len(os.listdir(path_positive)) x = np.zeros((num_sample, sample_data.shape[0], sample_data.shape[1])) y = np.zeros((num_sample, 2)) i = 0 for file_name in tqdm_notebook(os.listdir(path_positive)): feature = extract_feature(path_positive+file_name) x[i, :, :] = feature y[i, :] = np.array([1, 0]) i += 1 for file_name in tqdm_notebook(os.listdir(path_negative)): feature = extract_feature(path_negative+file_name) x[i, :, :] = feature y[i, :] = np.array([0, 1]) i += 1 print("Num sample: ", num_sample) print("Time: ", time.time()-start) np.save("Xtrain", np.asarray(x)) np.save("Ytrain", np.asarray(y)) |
Khởi tạo model và trainning
Cấu trúc model mình khởi tạo khá đơn giản nhằm đảm bảo cho model nhẹ và thời gian dự đoán nhanh. Trong thời gian tới mình có thể cập nhật lại phần này để đưa ra model tốt nhất có thể.
Code khởi tạo model:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from keras.models import Sequential from keras.layers import Dense, GRU from keras.layers import Activation from keras.models import load_model from keras import optimizers import keras num_hidden = 2 model = Sequential() model.add(Dense(128, input_shape=(x.shape[1], x.shape[2]))) model.add(Activation("relu")) for _ in range(num_hidden): model.add(Dense(128)) model.add(Activation("relu")) model.add(GRU(128)) model.add(Dense(2, activation = "softmax")) adam = optimizers.Adam(lr=0.000125) model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy']) model.summary() |
Kết quả:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | Model: "sequential_5" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_17 (Dense) (None, 47, 128) 16512 _________________________________________________________________ activation_13 (Activation) (None, 47, 128) 0 _________________________________________________________________ dense_18 (Dense) (None, 47, 128) 16512 _________________________________________________________________ activation_14 (Activation) (None, 47, 128) 0 _________________________________________________________________ dense_19 (Dense) (None, 47, 128) 16512 _________________________________________________________________ activation_15 (Activation) (None, 47, 128) 0 _________________________________________________________________ gru_5 (GRU) (None, 128) 98688 _________________________________________________________________ dense_20 (Dense) (None, 2) 258 ================================================================= Total params: 148,482 Trainable params: 148,482 Non-trainable params: 0 _________________________________________________________________ |
Tiếp theo, mình chia bộ dữ liệu thành 2 phần: 85% cho tập train và 15% cho tập validation :
1 2 3 | from sklearn.model_selection import train_test_split x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.15, random_state=42) |
Trainning model:
1 2 3 | model.fit(x_train, y_train, validation_data=(x_valid, y_valid), batch_size=32, epochs=12, shuffle=True) model.save('model.h5') |
Kết quả:
1 2 3 4 5 6 7 | Epoch 10/12 4764/4764 [==============================] - 17s 4ms/step - loss: 0.1363 - accuracy: 0.9536 - val_loss: 0.1304 - val_accuracy: 0.9548 Epoch 11/12 4764/4764 [==============================] - 17s 4ms/step - loss: 0.1274 - accuracy: 0.9582 - val_loss: 0.1301 - val_accuracy: 0.9548 Epoch 12/12 4764/4764 [==============================] - 17s 4ms/step - loss: 0.1112 - accuracy: 0.9633 - val_loss: 0.1225 - val_accuracy: 0.9655 |
Chúng ta cùng test model chạy realtime để kiểm tra lại kết quả:
Mình sử dụng pyaudio để stream dữ liệu audio thu từ microphone, việc chạy một thread để thu âm dữ liệu, một thread để detect sẽ giúp ta không bỏ sót dữ liệu:
Code khởi tạo audio stream:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | def get_audio_input_stream(callback): stream = pyaudio.PyAudio().open( format=pyaudio.paInt16, channels=1, rate=fs, input=True, frames_per_buffer=chunk_samples, input_device_index=0, stream_callback=callback) return stream def callback(in_data, frame_count, time_info, status): global run, timeout, data, silence_threshold data0 = np.frombuffer(in_data, dtype='int16') data = np.append(data, data0) if len(data) > feed_samples: data = data[-feed_samples:] q.put(data) return (in_data, pyaudio.paContinue) |
Code dectect trigger word:
1 2 3 4 5 6 7 8 9 10 11 12 | while True: data = q.get() save_audio(data, "temp/temp.wav") feature = extract_feature("temp/temp.wav") x_t = np.zeros((1, feature.shape[0], feature.shape[1])) x_t[0, : , :] = feature r = model.predict(x_t) if r[0][0] > 0.5: print("trigger word detected!") print(r[0][0]) time.sleep(0.001) |
Hướng cải tiến:
- Bổ xung thêm dữ liệu
- Thử các trích xuất đặc trưng khác
- Cải tiến cấu trúc model
- Sử dụng model pruning để làm model nhẹ và nhanh hơn
Kết luận:
Trên mình đã giới thiệu phương pháp xây dựng model trigger word của mình. Nếu có ý kiến đóng góp, xin các bạn hãy comment bên dưới. Cảm ơn các bạn đã đọc!