Các mẹo và thủ thuật
OR ở trong JOIN, WHERE trên nhiều cột
SQL SERVER có thể lọc data 1 cách hiệu quả bằng việc sử dụng index thông qua mệnh đề WHERE hoặc bất cứ tổ hợp lọc nào được phân tách bằng toán tử AND. Bằng cách duy nhất, các hoạt động này lấy dữ liệu và cắt nó thành các phần nhỏ dần, cho đến khi chỉ còn tập dữ liệu của chúng ta.
OR là 1 câu chuyện khác. Vì nó là bao hàm, SQL SERVER không thể xử lí chúng ở trong 1 thực hiện. Thay vào đó thì mỗi thành phần OR phải được xử lí độc lập. Khi thực thi này được hoàn thành, kết quả sẽ được ghép nối lại và trả về cho chúng ta.
Kịch bản tồi tệ nhất xảy ra khi chúng ta sử dụng OR là có nhiều bảng hoặc cột được tham gia vào mệnh đề. Chúng ta không chỉ cần đánh giá từng thành phần của mệnh đề OR mà còn cần theo dõi thông qua bộ lọc và bảng khác ở trong truy vấn. Ngay cả khi chỉ có một vài bảng hoặc cột, hiệu suất của truy vấn cũng có thể tồi tệ đến mức khó tin.
Dưới đây là 1 ví dụ đơn giản về cách mà OR có thể khiến truy vấn trở nên chậm trễ nhiều so với bạn tưởng tượng:
1 2 3 4 5 6 7 8 | SELECT DISTINCT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.ProductID = DETAIL.ProductID OR PRODUCT.rowguid = DETAIL.rowguid; |
Truy vấn chỉ đơn giản là: ghép nối 2 bảng và kiểm tra ProductID và rowguid. Ngay cả khi không có một cột nào trong 2 cột này được đánh index, thì hi vọng của chúng ta là sẽ quét trên 2 bảng Product và SalesOrderDetail. Quá tốn kém, nhưng ít nhất có 1 cái gì đó chúng ta có thể hiểu. Đây sẽ là kết quả thực hiện của truy vấn này:
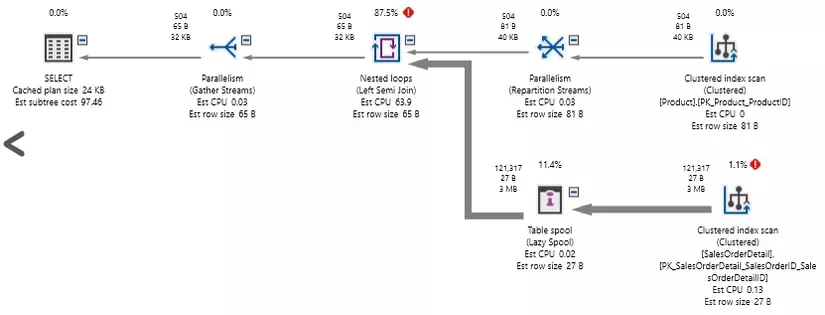

SQL SERVER đã quét cả 2 bảng, nhưng việc xử lí OR mất một lượng tính toán vô lí. 1,2 triệu lượt read đã được thực hiện ! Giả sử bảng Product chỉ chứa 504 bản ghi và SalesOrderDetail chứa 121317 bản ghi, chúng ta đã đọc nhiều hơn so với dữ liệu của 2 bảng này. Ngoài ra truy vấn mất khoảng 2 giây để thực hiện trên máy tính có SSD tương đối nhanh.
Điểm nổi bật trong cái demo đáng sợ này là SQL SERVER có thể dễ dàng xử lí một điều kiện OR trên nhiều cột. Cách tốt nhất để đối phó với OR là loại bỏ nó (nếu có thể) hoặc chia nó ra thành các truy vấn nhỏ hơn. Việc chia 1 truy vấn ngắn thành một truy vấn dài hơn, không phải là một việc tối ưu cho lắm, nhưng nó thường là lựa chọn tốt nhất:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.ProductID = DETAIL.ProductID UNION SELECT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.rowguid = DETAIL.rowguid |
Trong lần viết lại này, chúng ta đã lấy từng thành phần của OR và biến nó thành câu lệnh SELECT riêng rẽ. UNION ghép nối kết quả và loại bỏ trùng lặp. Đây là hiệu suất kết quả:
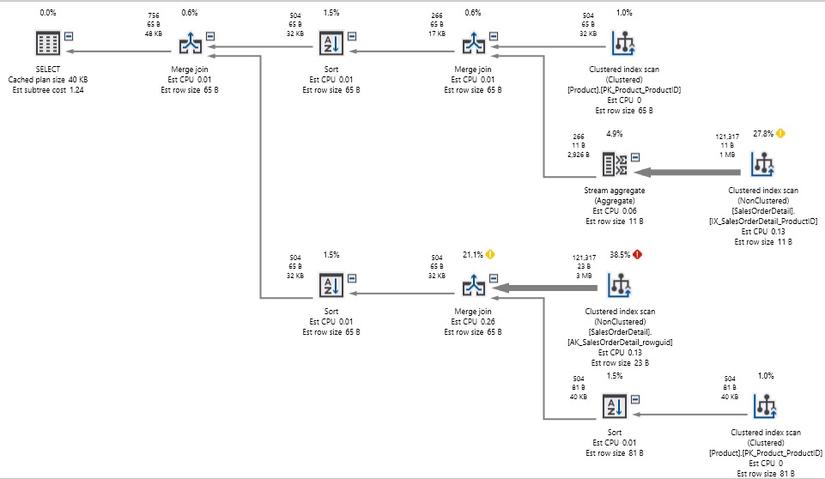

Kế hoạch thực hiện trở nên phức tạp hơn đáng kể, vì chúng ta đang truy vấn mỗi bảng 2 lần, thay vì một lần, nhưng kết quả đã cắt giảm từ 1,2 triệu xuống còn 750 và truy vấn được thực hiện tốt trong 1 giây, thay vì trong 2 giây.
Lưu ý rằng vẫn còn 1 lượng lớn các lần quét index trong thực hiện, nhưng mặc dù phải quét các bảng 4 lần để đáp ứng truy vấn của chúng ta, hiệu suất vẫn tốt hơn nhiều so với trước đây.
Hãy thận trọng khi viết truy vấn với OR. Kiểm tra và xác minh rằng hiệu suất thực thi là tốt và bạn sẽ không vô tình giới thiệu 1 quả bom như những gì đã quan sát ở ví dụ trên.
Tìm kiếm chuỗi kí tự đại diện
Tìm kiếm chuỗi có thể trở nên là một thách thức. Đối với các cột string được tìm kiếm thường xuyên, chúng ta phải đảm bảo rằng:
- Đánh index cho các cột tìm kiếm
- Những index có thể được sử dụng
- Nếu không, chúng ta có thể sử dụng index full-text
- Nếu không, chúng ta có thể sử dụng hash, n-gram, hay các giải pháp khác ?
Với điều kiện không sử dụng các feature bổ sung hoặc cân nhắc thiết kế, SQL SERVER thực hiện fuzzy search là không tốt. Đó là, nếu bạn muốn phát hiện sự hiện diện của một chuỗi ở bất kì vị trí nào trong một cột, việc lấy dữ liệu sẽ không hiệu quả:
1 2 3 4 5 6 7 8 | SELECT Person.BusinessEntityID, Person.FirstName, Person.LastName, Person.MiddleName FROM Person.Person WHERE Person.LastName LIKE '%For%'; |
Trong việc tìm kiếm chuỗi ở trên, chúng ta sẽ kiểm tra LastName xem có sự xuất hiện của từ “For” ở bất kì vị trí nào trong chuỗi. Khi % được đặt ở đầu chuỗi, chúng ta không thể sử dụng bất kì một index tăng dần nào khác. Tương tự như vậy, khi một % được đặt ở cuối chuỗi, chúng ta cũng không thể sử dụng index giảm dần. Dưới đây là hiệu suất của truy vấn trên:
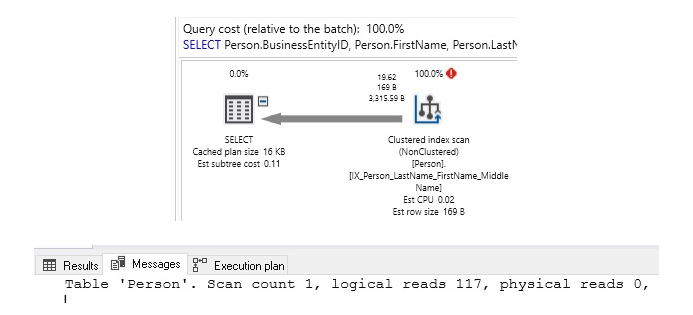
Như mong đợi, kết quả truy vấn trên sẽ quét trên bảng Person. Cách duy nhất để biết liệu 1 chuỗi có tồn tại trong 1 văn bản hay không là lướt qua từng kí tự trong mỗi văn bản, tìm kiếm sự xuất hiện của chuỗi đó. Trên 1 bảng nhỏ, điều này có thể được chấp nhận, nhưng đối với bất kì một tập dữ liệu lớn nào, điều này sẽ rất chậm và chúng ta phải chờ đợi kết quả rất lâu.
Có nhiều cách khác nhau để khắc phục tình trạng này, bao gồm:
- Đánh giá lại ứng dụng. Chúng ta có thực sự phải thực hiện tìm kiếm kí tự đại diện theo cách này không ? Người dùng có thực sự muốn tìm kiếm tất cả các phần của cột này cho chuỗi đó không ? Nếu không, thì vấn đề này chắc chắn sẽ biến mất, vì chúng ta không cần phải thực hiện tìm kiếm
- Chúng ta có thể áp dụng bất cứ một bộ lọc nào khác cho truy vấn đẻ giảm kích thước của dữ liệu trước khi thực hiện tìm kiếm chuỗi không? Nếu chúng ta có thể lọc ngày, thời gian, trạng thái…có lẽ chúng ta có thể giảm dữ liệu cần thực hiện phép tìm kiếm xuống 1 lượng đủ nhỏ để hiệu suất có thể ở mức chấp nhận được
- Chúng ta có thể sử dụng tìm kiếm chuỗi leading, thay vì tìm kiếm kí tự đại diện. Có thể thay
%For%bằng%Forhay không ? - Lập index toàn bộ văn bản có sẵn?
- Chúng ta có thể thực hiện truy vấn bảng băm (Hash) hoặc n-gram cho trường hợp đó hay không ?
3 giải pháp đầu tiên là việc cân nhắc cho thiết kế / kiến trúc vì chúng là giải pháp đầu tiên giúp tối ưu hóa ứng dụng của bạn. Chúng hỏi: ta có thể giả định, thay đổi hoặc hiểu gì về truy vấn này để thực hiện nó tốt? Tất cả đều ở mức độ kiến thức ứng dụng hoặc khả năng thay đổi dữ liệu trả về của 1 truy vấn. Đây không phải là các giải pháp lúc nào cũng có thể thực hiện được, nhưng quan trọng là phải đưa tất cả các bên liên quan vào để giải quyết đầu tiên. Nếu 1 bảng có hàng tỉ record và người dùng muốn tìm kiếm thường xuyên ở cột có type là NVARCHAR(MAX), thì cần thảo luận nghiêm túc rằng tại sao người dùng muốn làm điều này và nếu các phương án sẵn có. Nếu chức năng đó thực sự quan trọng thì chúng ta phải tính đến mức độ tiêu thụ tài nguyên, điều này cực kì quan trọng.
Đánh index cho full-text là một tính năng trong SQL SERVER có thể tạo ra các index cho phép tìm kiếm chuỗi linh hoạt trên các văn bản. Điều này bao gồm cả tìm kiếm kí tự đại diện. Mặc dù linh hoạt, nhưng nó là một tính năng bổ sung cần phải cài đặt, cấu hình và sửa đổi. Đối với ứng dụng tập trung vào tìm kiếm chuỗi, nó có thể là giải pháp hoàn hảo nhất.
Một giải pháp sẵn có cuối cùng và là giải pháp tuyệt vời cho các cột chuỗi ngắn. N-Gram là các phân đoạn chuỗi có thể được lưu trữ riêng biệt với chuỗi dữ liệu tìm kiếm và có thể cung cấp việc tìm các chuỗi con mà không cần phải quét một bảng lớn. Trước khi thảo luận về vấn đề này, điều quan trọng là phải hiểu đầy đủ các quy tắc tìm kiếm được sử dụng trong ứng dụng. Ví dụ:
- Có lượng kí tự tối thiểu hoặc tối đa được phép có trong tìm kiếm hay không?
- Các tìm kiếm trống (quét bảng) có được phép hay không ?
- Có nhiều cụm từ/cú pháp hay không ?
- Chúng ta có cần lưu chuỗi con bắt đầu 1 chuỗi hay không ? Nó có thể thu thập với index nếu cần thiết
Khi những giải pháp này được đánh giá, chúng ta có thể lấy một cột và chia nó thành các phân đoạn chuỗi. Ví dụ: hãy xem xét một hệ thống tìm kiếm trong đó độ dài tìm kiếm tối thiểu là 3 kí tự và được lưu trữ. Dưới đây là các chuỗi con của từ “Dinosaur” được lưu ino, inos, inosa, inosau, inizard, nos, nosa, nosau, nizard, osa, osau, osaur, sau, saur, aur.
Nếu chúng ta tạo ra 1 bảng riêng biệt lưu trữ các chuỗi này (còn gọi là n-gram), chúng ta có thể liên kết các n-gram đó với bản ghi mà có cột chứa từ “Dinosaur”. Thay vì quét 1 bảng lớn để tìm ra kết quả, chúng ta có thể tìm kiếm trên bảng n-gram. Ví dụ ta tìm kiếm kí tự đại diện “dino”, thì tìm kiếm có thể được chuyển hướng qua câu query sau:
1 2 3 4 5 6 | SELECT n_gram_table.my_big_table_id_column FROM dbo.n_gram_table WHERE n_gram_table.n_gram_data = 'Dino'; |
Giả sử n-gram được đánh index, sau đó sẽ nhanh chóng trả lại id của bảng lớn có chữ “dino” ở bất cứ đâu trong đó. Bảng n-gram chỉ yêu cầu 2 cột và chúng ta có thể ràng buộc kích thước của chuỗi n-gram bằng cách sử dụng các quy tắc đã nêu ở trên. Ngay cả khi bảng này trở nên lớn, nó vẫn có khả năng tìm kiếm rất nhanh
Quên đánh indexes
SQL SERVER cung cấp giao diện để cho chúng ta biết khi có các index bị thiếu:

Cảnh báo này cho chúng ta biết rằng có cách để cải thiện hiệu suất truy vấn. Văn bản mày xanh lá cây cung cấp cho chúng ta các thi tiết của các index mới nhưng chúng ta cần thực hiện một số công việc trước khi xem xét lời khuyên từ SQL SERVER.
- Đã có index nào tương tự như index này có thể cover được trường hợp này hay không ?
- Chúng ta có cần index tất cả các cột? Hay chỉ cần index trên các mục sắp xếp ?
- Tác động của việc đánh index ? Nó cải thiện hiệu suất của truy vấn như thế nào ?
- Có phải index này đã tồn tại, nhưng vì 1 số lí do, trình tối ưu hóa của SQL SERVER không chọn nó ?
Thông thường, các index được đề xuất ra là nhiều. Ví dụ, đây là câu lệnh index được tạo ra cho kế hoạch từng phần ở hiển thị trên:
1 2 3 4 | CREATE NONCLUSTERED INDEX <Name of Missing Index, sysname,> ON Sales.SalesOrderHeader (Status,SalesPersonID) INCLUDE (SalesOrderID,SubTotal) |
Trong trường hợp này, đã có index ở trên SalesPersonID. Trạng thái xảy ra là một cột trong đó bảng chủ yếu chỉ chứ 1 giá trị, có nghĩa là dưới dạng cột được sắp xếp, nó sẽ không cung cấp nhiều giá trị. 19% tác động không có giá trị gì. Chúng ta sẽ cần hỏi liệu truy vấn có đủ quan trọng để đảm bảo cho cải tiến này không. Nếu nó được thực hiện 1 triệu lần 1 ngày, thì 20% cải thiện query là điều nên làm.