Chắc hẳn nếu bạn có bạn bè làm về Data Science (Data Engineer, Data Scientist, ..) thì các cái tên Hadoop, Spark, … được nhắc lại nhiều lần và bạn có thể giống mình sẽ tự hỏi: Nó là gì?
Mình có tìm các khóa về Spark thì kiến thức cần có trước khi học cần đó là Big Data và Hadoop. Trong bài viết này mình sẽ trình bày một số nội dung lý thuyết liên quan đến Hadoop. Lét gô
Big data
- Big data là thuật ngữ được sử dụng để chỉ các tập dữ liệu lớn và phức tạp, có thể không thể được xử lý bằng các công cụ truyền thống.
- Các tập dữ liệu này thường có kích thước lớn, tốc độ cập nhật nhanh và đa dạng về định dạng.
- Big data thường được tạo ra bởi các nguồn dữ liệu khác nhau, bao gồm các trang web, cảm biến, thiết bị di động, máy chủ, v.v.
- Các ứng dụng của big data là rất đa dạng, bao gồm phân tích dữ liệu, dự đoán và dự báo, hỗ trợ quyết định, máy học, và nhiều hơn thế nữa.
Vậy Hadoop là gì và có liên quan thế nào?
- Hadoop là một hệ sinh thái mã nguồn mở được sử dụng để lưu trữ và xử lý Big Data
- Hadoop có liên quan chặt chẽ đến Big Data vì nó cho phép lưu trữ và xử lý các tập dữ liệu lớn. Hadoop có thể xử lý các tập dữ liệu lớn và phức tạp bằng cách phân tán chúng trên nhiều node khác nhau trong mạng và sử dụng MapReduce để xử lý các tác vụ phân tán. Hadoop cũng hỗ trợ các công cụ và kỹ thuật khác để quản lý, truy vấn và phân tích dữ liệu lớn, bao gồm Pig, Hive, HBase, Spark, v.v. (Những khái niệm mới kia mình sẽ giải thích sau)
- Đến đây thì có vẻ dễ hiểu hơn mối quan hệ giữa chúng rồi đó. Chúng ta cùng đi tìm hiểu sâu hơn về Hadoop nào
Hadoop 1.x và Hadoop 2.x
- Hadoop có 2 phiên bản chính là Hadoop 1.x và hadoop 2.x, trong đó Hadoop 2.x là phiên bản tiếp theo của Hadoop 1.x. Dưới đây là 1 số so sanh cải tiến của Hadoop 2.x so với Hadoop 1.x
Hadoop 2.x
| Hadoop 1.x | ||
|---|---|---|
| Sử dụng MapReduce và HDFS để lưu trữ và xử lý dữ liệu | Thành phần | Bổ sung thêm YARN để quản lý tài nguyên và cho phép các ứng dụng chạy trên Hadoop sử dụng tài nguyên một cách hiệu quả |
| Có 1 NameNode và nhiều Data Node để lưu trữ dữ liệu | Lưu trữ | Có 2 loại NameNode là NameNode chính và NameNode phụ để cải thiện hiệu suất và độ tin cậy hơn |
| Chạy một ứng dụng duy nhất trên mỗi cụm | Hỗ trợ | hỗ trợ nhiều ứng dụng khác nhau chạy trên cùng một cụm Hadoop |
| hạn chế về hiệu suất và khả năng mở rộng | Hiệu suất và khả năng mở rộng | Cải tiến hiệu suất và khả năng mở rộng, cho phép xử lý các tập dữ liệu lớn và phức tạp hơn |
Nhìn vào hình vẽ trên, có lẽ các bạn cũng đã biết các thành phần trong Hadoop. Ở đây mình sẽ phân tích các thành phần của Hadoop 2.x, đó là
- HDFS
- YARN
- MapReduce
HDFS
- HDFS (Hadoop Distributed File System) là một hệ thống tệp phân tán được sử dụng trong hệ sinh thái Hadoop để lưu trữ và quản lý các tập dữ liệu lớn.
- HDFS hoạt động bằng cách phân tán các tập dữ liệu thành các khối (block) nhỏ và lưu trữ chúng trên nhiều node khác nhau trong cụm máy tính.
- HDFS cũng sử dụng các cơ chế bảo vệ dữ liệu như sao lưu (replication) để đảm bảo tính toàn vẹn của dữ liệu.
- HDFS cũng cung cấp các tính năng như đọc/ghi dữ liệu từ xa và phân quyền truy cập dữ liệu để quản lý việc truy cập vào tập dữ liệu trong cụm máy tính.
HDFS đọc ghi thế nào?
- Để phân tích quá trình đọc và ghi trên HDFS, chúng ta sẽ cùng đến với một ví dụ sau: Giả sử chúng ta có một tập dữ liệu lớn được chia thành 4 phân vùng và lưu trữ trên HDFS với cấu trúc phân tán như sau:
- Phân vùng 1: Chứa 2 khối dữ liệu, lưu trữ trên DataNode 1 và DataNode 2.
- Phân vùng 2: Chứa 3 khối dữ liệu, lưu trữ trên DataNode 2, DataNode 3 và DataNode 4.
- Phân vùng 3: Chứa 1 khối dữ liệu, lưu trữ trên DataNode 3.
- Phân vùng 4: Chứa 4 khối dữ liệu, lưu trữ trên DataNode 4, DataNode 5 và DataNode 6.
- Trong quá trình đọc tập dữ liệu:
- Xác định vị trí lưu trữ của dữ liệu: Ứng dụng đọc dữ liệu sẽ truy vấn HDFS để xác định vị trí lưu trữ của các khối dữ liệu cần đọc.
- Lấy dữ liệu từ các node lưu trữ: HDFS sẽ lấy các khối dữ liệu từ các node lưu trữ và trả về cho ứng dụng đọc dữ liệu.
- Ghép các khối dữ liệu lại với nhau: Sau khi dữ liệu được lấy từ các node lưu trữ, các khối dữ liệu sẽ được ghép lại với nhau để tạo thành các tập tin gốc ban đầu.
- Đọc dữ liệu: Dữ liệu được trả về cho ứng dụng để xử lý hoặc hiển thị cho người dùng.
- Xác nhận: Sau khi dữ liệu được đọc, HDFS sẽ trả về một thông báo xác nhận cho ứng dụng để cho biết dữ liệu đã được đọc thành công hoặc không.
- Trong quá trình ghi tập dữ liệu:
- Xác định vị trí lưu trữ: Hệ thống băm HDFS sẽ tính toán các vị trí lưu trữ cho từng khối dữ liệu, dựa trên hệ thống tên miền phân tán (Distributed Namespace) của HDFS.
- Sao chép dữ liệu: Mỗi khối dữ liệu được sao chép sang ít nhất hai node khác nhau trong cụm để đảm bảo tính toàn vẹn dữ liệu. Số lượng sao chép này có thể được cấu hình.
- Ghi dữ liệu: Dữ liệu được ghi vào HDFS tại các vị trí lưu trữ đã được xác định. Nếu có nhiều tập tin được ghi vào HDFS, các khối dữ liệu của chúng được lưu trữ trên các node khác nhau trong cụm Hadoop.
- Xác nhận: Sau khi dữ liệu đã được ghi vào HDFS, HDFS sẽ trả về một thông báo xác nhận cho ứng dụng để cho biết dữ liệu đã được ghi thành công hoặc không.
- Ghi nhật ký (WAL): HDFS sử dụng một bản ghi nhật ký để đảm bảo tính toàn vẹn dữ liệu. Mỗi khi dữ liệu được ghi vào HDFS, HDFS sẽ ghi một bản ghi nhật ký (gọi là Write Ahead Log – WAL) để đảm bảo rằng dữ liệu đã được ghi đúng và đầy đủ.
Sẽ ra sao nếu một DataNode bị hỏng
Khi một DataNode trong HDFS bị hỏng hoặc không thể truy cập được, HDFS có các** cơ chế xử lý lỗi tự động** nhằm đảm bảo tính tin cậy của dữ liệu:
- Replication: HDFS sử dụng cơ chế sao lưu (replication) để đảm bảo tính tin cậy của dữ liệu. Khi một DataNode bị hỏng, các khối dữ liệu trên DataNode đó sẽ không thể truy cập được. Tuy nhiên, các bản sao của các khối dữ liệu đó được lưu trữ trên các DataNode khác nhau. HDFS sẽ tự động sao chép các bản sao này đến các DataNode khác để thay thế cho các khối dữ liệu bị hỏng.
- Block replication: Nếu một khối dữ liệu bị hỏng và không thể sao chép lại được, HDFS sẽ sử dụng cơ chế block replication để tạo ra các bản sao mới của khối dữ liệu đó và lưu trữ trên các DataNode khác nhau.
- Balancing: HDFS sử dụng cơ chế cân bằng tải (balancing) để đảm bảo rằng dữ liệu được phân phối đồng đều trên các DataNode. Khi một DataNode bị hỏng, HDFS sẽ tự động cân bằng lại dữ liệu trên các DataNode khác nhau để đảm bảo tính tin cậy của dữ liệu.
- Replication factor: HDFS sử dụng replication factor để đảm bảo tính tin cậy của dữ liệu. Khi một DataNode bị hỏng, HDFS sẽ tăng replication factor lên để tạo ra thêm các bản sao của các khối dữ liệu trên các DataNode khác nhau để đảm bảo tính tin cậy của dữ liệu.
- Heartbeat: HDFS sử dụng cơ chế heartbeat để kiểm tra tính khả dụng của các DataNode. Khi một DataNode không phản hồi trong khoảng thời gian quy định, HDFS sẽ coi DataNode đó là bị hỏng và thực hiện các cơ chế xử lý lỗi như đã nêu trên.
YARN
- Trong khi HDFS được sử dụng để lưu trữ và quản lý dữ liệu, YARN được sử dụng để quản lý tài nguyên và thực thi các ứng dụng trên cụm máy chủ Hadoop.
- YARN là một hệ thống quản lý tài nguyên phân tán được thiết kế để quản lý tài nguyên của các ứng dụng Hadoop. YARN giúp chia nhỏ các ứng dụng lớn thành các tác vụ nhỏ hơn, được gọi là container, và phân phối chúng trên các Node Manager để thực thi.
- YARN cung cấp các cơ chế độc lập ngôn ngữ, cho phép các ứng dụng được viết bằng nhiều ngôn ngữ khác nhau, chẳng hạn như Java, Python, Scala và R. YARN cũng cung cấp các cơ chế quản lý tài nguyên linh hoạt, cho phép quản lý tài nguyên dựa trên nhu cầu của các ứng dụng.
- Sự liên kết giữa YARN và HDFS là rất quan trọng trong việc xử lý dữ liệu lớn trên Hadoop. Khi một ứng dụng Hadoop được chạy trên YARN, YARN sẽ cung cấp các tài nguyên phần cứng và phần mềm cần thiết cho ứng dụng đó. Ứng dụng này có thể truy cập dữ liệu được lưu trữ trên HDFS để xử lý.
- Điều này có nghĩa là YARN sẽ xác định các tài nguyên phần cứng và phần mềm cần thiết để chạy ứng dụng, sau đó YARN sẽ yêu cầu HDFS để truy cập dữ liệu cần thiết để xử lý. Sau đó, HDFS sẽ cung cấp các khối dữ liệu cho ứng dụng để xử lý.
MapReduce
- MapReduce là một mô hình lập trình được sử dụng để xử lý dữ liệu lớn song song và phân tán trên các cụm máy tính
- MapReduce bao gồm 2 hàm chính được định nghĩa bởi người dùng
- Map: bộ lọc (filter) và phân loại (sort) trên dữ liệu.
- Reduce:quá trình tổng hợp toàn bộ dữ liệu
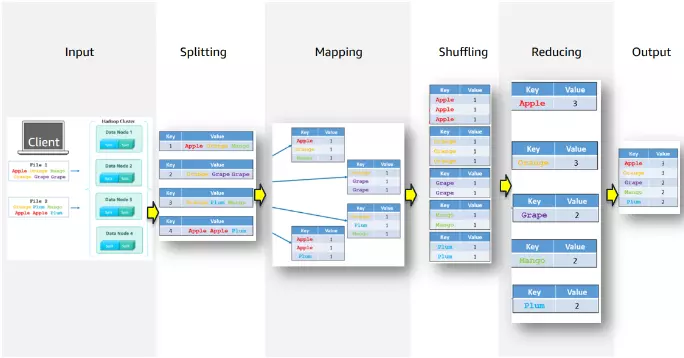
- Ví dụ cho hình vẽ trên: Bài toán đặt ra là tính tổng số lượng các loại hoa quả với dữ liệu nằm trong các file khác nhau (2 files)
- Input: Các tập tin được lưu trữ trong HDFS
- Splitting: Các tập tin được chia thành nhiều phần nhỏ hơn – gọi là input splits (ở đây mỗi input split là một dòng dữ liệu)
- Mapping: Các input splittings được chuyển đến các máy tính trong cụm Hadoop để được xử lý. Các mapper sẽ chuyển đổi input split thành các cặp key-value
- Shuffling: Sau khi các mapper đã tạo ra các cặp key-value, các cặp này sẽ được sắp xếp lại dựa trên key của chúng
- Reducing: Các reducer sẽ lấy các cặp key-value và thực hiện phép tính trên chúng để tạo ra kết quả cuối cùng (ở đây là cộng để tính tổng số lượng)
- Output: Kết quả xử lý sẽ được lưu trữ trong một tập tin đầu ra
Combiner và Partitioner
- Trong MapReduce, Combiner và Partitioner là hai thành phần quan trọng để tối ưu hóa hiệu suất xử lý.
- Combiner giúp giảm lượng dữ liệu cần được xử lý bởi Reducer bằng cách kết hợp các giá trị giống nhau và loại bỏ các giá trị trùng lặp.
- Partitioner giúp phân phối dữ liệu đầu vào đến các Reducer theo cách tối ưu để giảm thời gian xử lý. Partitioner sẽ ánh xạ các cặp khóa-giá trị được tạo ra bởi Mapper đến các Reducer theo một cách nhất định, thông qua hàm hash. Quá trình phân vùng này giúp đảm bảo rằng các khóa giống nhau sẽ được gửi đến cùng một Reducer, giúp giảm thời gian xử lý và tối ưu hóa hiệu suất của hệ thống MapReduce.
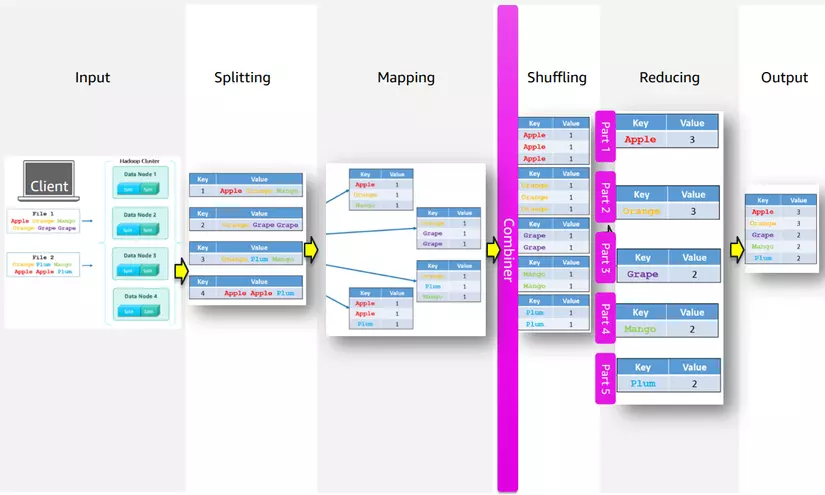
Ví dụ về cách 3 thành phần này tương tác với nhau
- Giả sử bạn cần xử lý một tập dữ liệu lớn (ví dụ: 1TB) trên một cụm máy tính Hadoop gồm 20 node.
- HDFS sẽ chia tập dữ liệu thành các khối nhỏ (ví dụ: 128MB/khối) và lưu trữ chúng trên các node khác nhau trong cụm máy tính. Các khối dữ liệu được sao chép trên nhiều node để đảm bảo tính toàn vẹn của dữ liệu.
- Sau đó, YARN sẽ phân phối các tác vụ xử lý dữ liệu (ví dụ: MapReduce) trên các node khác nhau trong cụm máy tính. YARN sẽ phân phối các tài nguyên (bộ nhớ, CPU) cho các tác vụ xử lý dữ liệu và quản lý việc thực hiện các tác vụ này trên các node khác nhau.
- Cuối cùng, MapReduce sẽ thực hiện các tác vụ xử lý dữ liệu trên các khối dữ liệu được lưu trữ trên các node khác nhau. MapReduce sẽ tải các khối dữ liệu vào bộ nhớ, xử lý chúng và ghi kết quả vào HDFS. MapReduce sẽ chia tập dữ liệu thành các phần nhỏ hơn để xử lý song song trên nhiều node khác nhau và tổng hợp kết quả cuối cùng.