Giới Thiệu Chung
Hôm nay mình sẽ hướng dẫn tất cả mọi người crawl dữ liệu trang web trường Đại Học mà mình đã từng học Đại học Khoa Học – Đại Học Huế. Mình sẽ giới thiệu đến tất cả mọi người về puppeteer, headless browser và puppeteer nó dùng để làm gì.
Headless Browser Là Gì?
Headless Browser là một trình duyệt web không có giao diện người dùng. Các headless browser cung cấp tương tác tự động một trang web trong một môi trường giống như các trình duyệt web phổ biến khác, nhưng nó được thực hiện thông qua giao diện dòng lệnh hoặc qua một mạng truyền thông. Các bạn có thể tham khảo thêm tại đây.
Ở đây mình có tóm gọn lại một câu đơn giản là headless Browser thay vì dùng để duyệt web thì nó sử dụng để cào dữ liệu, chụp ảnh màn hình của các trang web,…
Puppeteer Là Gì?
Puppeteer là thư viện của NodeJS, giúp bạn điều khiển headless Chrome. Các bạn tìm hiểu thêm tại đây nha
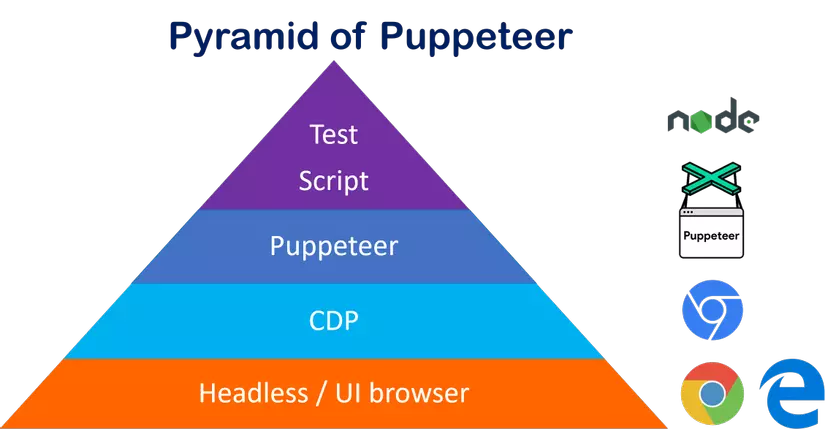
Bắt Đầu Làm Thôi Nào
Lên Ý Tưởng
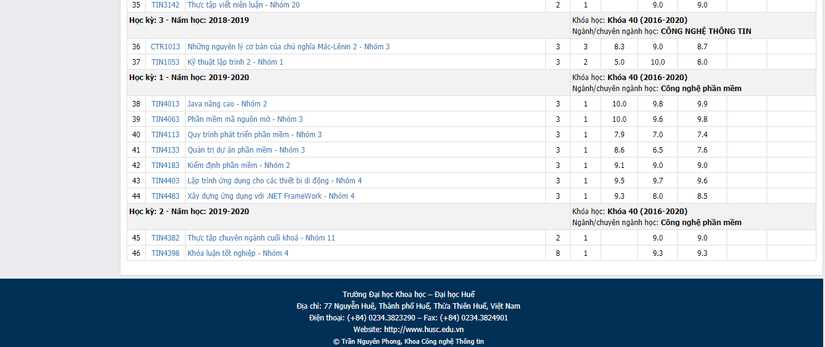
Ý tưởng thì mình sẽ crawl dữ liệu trang web đào tạo tín chỉ Đại Học Khoa Học. Vậy mình sẽ crawl cái gì từ trang này, mình sẽ crawl tất cả tên môn học số tín chỉ cùng với điểm của môn học đó, từ dữ liệu này chúng ta có thể biết được tình hình học tập hiện tại. Các chức năng có thể phát triển: Vẽ đồ thị, tính điểm trung bình, tính số điểm những môn học còn lại cần đạt được để đủ tiêu chí là sinh viên Giỏi, Khá, Trung Bình…
Những chức năng này hoàn toàn có thể phát triển trên nền tảng website hoặc mobile và đây là điều cần thiết, đáp ứng được nhu cầu của hầu hết sinh viên.
Cài Đặt Và Thiết Lập
Trước tiên các bạn tạo cho mình một folder trong folder đó là nơi chứa các thư mục dùng để crawl dữ liệu.
Khởi tạo ứng dụng với file package.json
Trong thư mục gốc của ứng dụng của bạn và nhập npm init để khởi tạo ứng dụng của bạn với tệp package.json.
npm init
Sau đó các bạn cài đặt module puppeteer để crawl dữ liệu nha.
Để mà cài đặt puppeteer trước hết các bạn phải cài đặt NodeJS tại đây.
npm install puppeteer
Sau khi cài đặt module xong các bạn tạo cho mình file index.js để mình viết chương trình crawl dữ liệu.
Bắt Đầu Code Thôi Nào
Trong file index.js các bạn require thư viện vào nha:
const puppeteer = require('puppeteer');
Tiếp đến, chúng ta sẽ khởi tạo một browser sử dụng phương thức launch() và truy cập vào trang đào tạo tín chỉ ĐH Khoa Học như sau:
1 2 3 4 5 6 7 8 9 10 | const puppeteer = require('puppeteer'); let dhhUrl = 'https://student.husc.edu.vn/Statistics/HistoryOfStudying'; (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.goto(dhhUrl); ......... })(); |
Để có thể crawl dữ liệu của trang web các bạn cần gọi đến API page.evaluate. Là một API rất quan trọng cho phép chúng ta chạy script để lấy nội dung trả về.
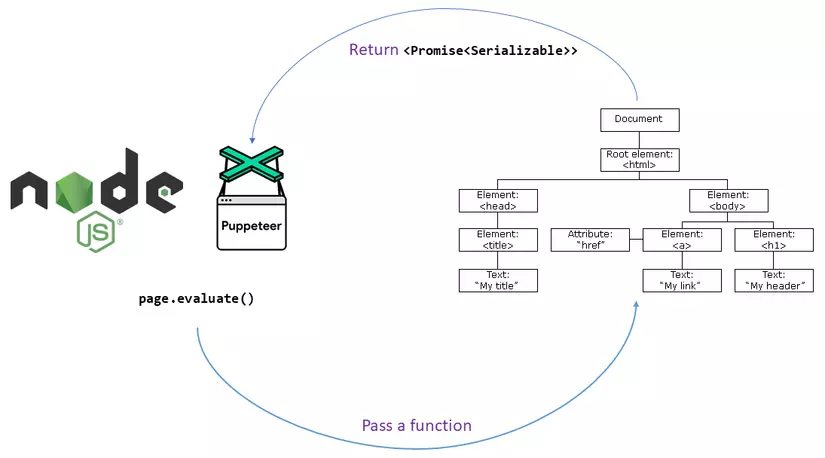
Bây giờ mình sẽ vào trang web để xem cấu trúc HTML của nó như thế nào nha. Để phân tích, bóc tách data dễ dàng nhé.
Cấu trúc chủ yếu chứa điểm từng môn học là 1 table gồm nhiều hàng tr, nhiều cột td.
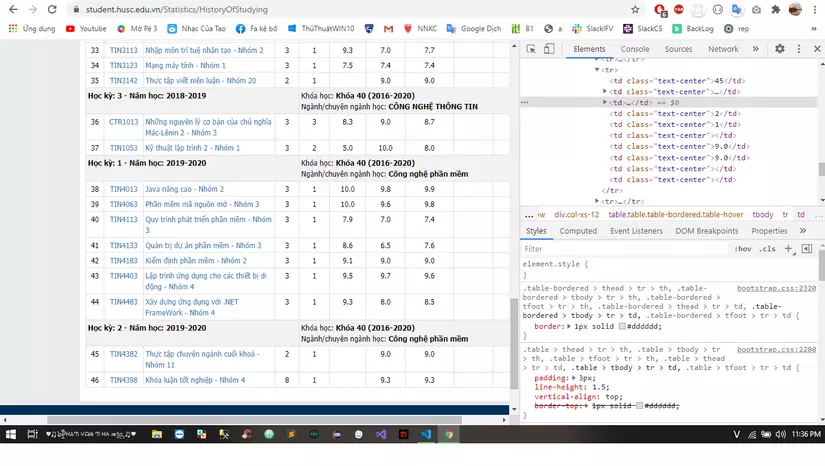
Điểm mấu chốt ở đây là chúng ta phải phân biệt được đâu là dòng tiêu đề ( Học kỳ: 1 – Năm học: 2019-2020 ) và đâu là dòng dữ liệu chứa điểm mà chúng ta cần lấy. Và sự khác biệt mà mình tìm ra được đó chính là thuộc tính colspan của các td trên từng tr:
- Dòng chứa tiêu đề sẽ bao gồm 1 thẻ
<tr><td colspan="4"></td><td colspan="12"></td></tr> - Dòng chứa dữ liệu điểm thì td không có attribute col-span.
Bây giờ các bạn mở tab console trong chrome dev tools để có thể cào dữ liệu bằng cách viết code JavaScript
1 2 3 4 5 6 7 8 9 10 11 12 13 | const table = document.getElementsByTagName('table') const lines = table[0].children[1].children //Lấy mảng tr nằm trong tbody [...lines].map(line => { if(![...line.children].find(td => td.getAttribute('colspan'))){ const data = line // dòng dữ liệu chứa điểm của chúng ta ở đây rồi. const name = data.children[2].children[0].innerText const stc = data.children[3].innerText const total = data.children[7].innerText console.log(`Tên môn học: ${name} - Số tín chỉ ${stc} - Tổng điểm ${total}`) } }) |
Và đây là kết quả khi chúng ta test trong console:
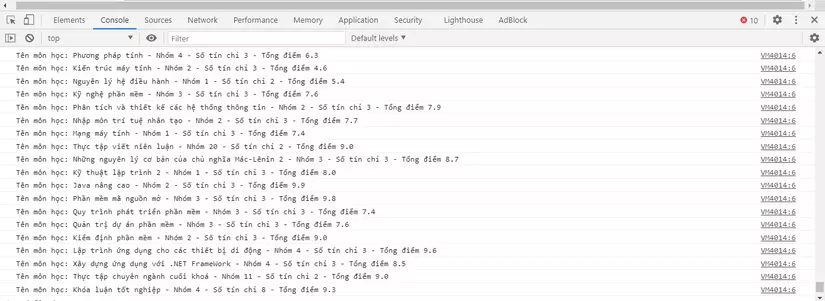
Sau khi test ok chúng ta vào file index.js và đây là code hoàn chỉnh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | const puppeteer = require('puppeteer'); let dhhUrl = 'https://student.husc.edu.vn/Statistics/HistoryOfStudying'; (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.goto(dhhUrl); let dhhData = await page.evaluate(() => { let result = []; const table = document.getElementsByTagName('table') const lines = table[0].children[1].children //Lấy mảng tr nằm trong tbody [...lines].map(line => { if(![...line.children].find(td => td.getAttribute('colspan'))){ const data = line // dòng dữ liệu chứa điểm của chúng ta ở đây rồi. const name = data.children[2].children[0].innerText const stc = data.children[3].innerText const total = data.children[7].innerText console.log(`Tên môn học: ${name} - Số tín chỉ ${stc} - Tổng điểm ${total}`) result.push({name, stc, total}) } }) return result; }); await browser.close(); })(); |
Tiếp đến các bạn mở terminal trong VScode hoặc trong cửa sổ cmd các bạn gõ cho mình node index.js. Và để xem nó crawl dữ liệu như thế nào nha.
Lời Kết
Vậy Là Xong bài Hướng Dẫn Crawl Dữ Liệu Với Puppeteer Và Nodejs rồi nhé. Mình mong muốn sau bài viết này các bạn có thể biết và hiểu thêm về puppeteer, các bạn có thể mở rộng thêm ý tưởng mới. Và có thể tự tay mình làm những project không cần phải quá đặc biệt nhưng nó do chính bạn làm thì cũng coi như là thành quả trong quá trình bạn học được.