BERT: Mô hình ngôn ngữ hiện đại cho xử lý ngôn ngữ tự nhiên (NLP)
- Tram Ho
BERT (Đại diện bộ mã hóa hai chiều từ Transformers) là một bài báo gần đây được xuất bản bởi các nhà nghiên cứu tại Google AI Language. Nó đã gây xôn xao cộng đồng Machine Learning bằng cách trình bày các kết quả tiên tiến trong nhiều bài toán NLP, bao gồm Question Answering (SQuAD v1.1), suy luận ngôn ngữ tự nhiên (MNLI) và các bài toán khác.
Chìa khóa đột phá kỹ thuật quan trọng của BERT đang áp dụng là đào tạo thông qua ngữ cảnh hai chiều của Tranformer (một kiến trúc mạng thần kinh dựa trên cơ chế tự chú ý để hiểu ngôn ngữ), một mô hình chú ý phổ biến, cho mô hình hóa ngôn ngữ. Điều này trái ngược với những nỗ lực trước đó đã xem xét một chuỗi văn bản theo kiểu đào tạo từ trái sang phải hoặc kết hợp cả đào tạo từ trái sang phải và phải sang trái. Kết quả bài báo cho thấy một mô hình ngôn ngữ được đào tạo hai chiều có thể có ý thức sâu sắc hơn về bối cảnh so với các mô hình ngôn ngữ đào tạo theo một hướng. Trong bài báo, các nhà nghiên cứu mô tả chi tiết một kỹ thuật mới có tên Masked LM (MLM) cho phép đào tạo hai chiều trong các mô hình mà trước đây không thể thực hiện được.
Tổng quan
Trong lĩnh vực khoa học máy tính, các nhà nghiên cứu đã nhiều lần chỉ ra giá trị của việc chuyển đổi giữa học – đào tạo một mô hình mạng neural trên một bài toán đã biết, ví dụ ImageNet, và sau đó thực hiện tinh chỉnh – sử dụng mạng neural được đào tạo làm cơ sở của một mô hình mục đích cụ thể mới. Trong những năm gần đây, các nhà nghiên cứu đã chỉ ra rằng một kỹ thuật tương tự có thể hữu ích trong nhiều bài toán ngôn ngữ tự nhiên.
Một cách tiếp cận khác, cũng phổ biến trong các bài toán NLP và được minh họa trong bài báo ELMo gần đây, là đào tạo dựa trên tính năng. Theo cách tiếp cận này, một mạng neural được đào tạo trước tạo ra các embedding word sau đó được sử dụng làm các tính năng trong các mô hình NLP.
BERT hoạt động như thế nào?
Biểu đồ dưới đây là một mô tả cấp cao của bộ mã hóa Transformer. Đầu vào là một chuỗi các mã thông báo, đầu tiên được nhúng vào các vectơ và sau đó được xử lý trong mạng neural. Đầu ra là một chuỗi các vectơ có kích thước H, trong đó mỗi vectơ tương ứng với một mã thông báo đầu vào có cùng chỉ mục.
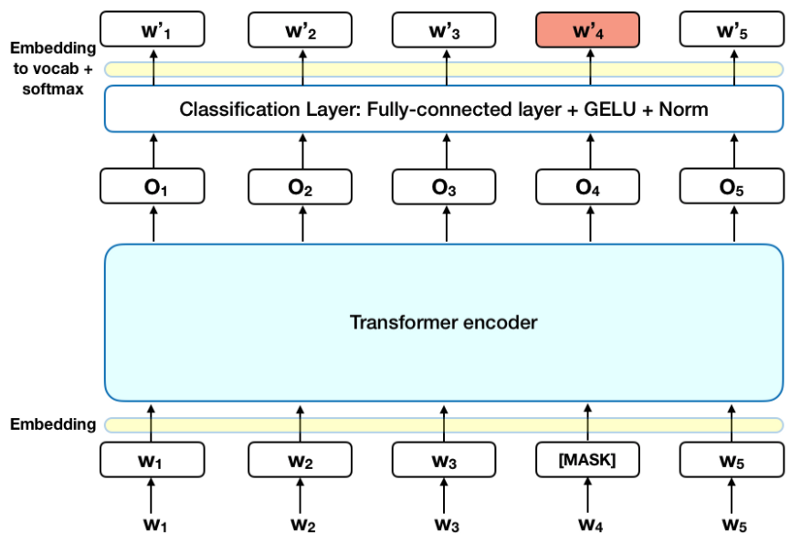
Khi đào tạo các mô hình ngôn ngữ, có một thách thức trong việc xác định mục tiêu dự đoán. Nhiều mô hình dự đoán từ tiếp theo theo trình tự (ví dụ: Đứa trẻ về nhà từ ___ ), một cách tiếp cận định hướng vốn đã hạn chế việc học theo ngữ cảnh. Để vượt qua thử thách này, BERT sử dụng hai chiến lược đào tạo:
Masked LM (MLM)
Trước khi cho các chuỗi từ vào BERT, 15% số từ trong mỗi chuỗi được thay thế bằng mã thông báo [MASK]. Mô hình sau đó cố gắng dự đoán giá trị ban đầu của các từ bị che, dựa trên ngữ cảnh được cung cấp bởi các từ khá không bị che ở trong chuỗi. Về mặt kỹ thuật, dự đoán của các từ đầu ra yêu cầu:
- Thêm một lớp phân loại ở đầu ra của bộ mã hóa.
- Nhân các vectơ đầu ra với ma trận nhúng, chuyển đổi chúng thành các chiều từ vựng.
- Tính xác suất của mỗi từ trong từ vựng với hàm softmax.
 Hàm mất mát (loss function) BERT chỉ xem xét dự đoán các giá trị bị che và bỏ qua dự đoán của các từ không bị che. Kết quả là, mô hình hội tụ chậm hơn các mô hình định hướng nhưng được bù đắp bởi nhận thức ngữ cảnh tăng lên của nó. *Lưu ý: Trong thực tế, việc triển khai BERT phức tạp hơn một chút và không thay thế tất cả các từ được che dấu 15%. Xem Phụ lục A để biết thêm thông tin. *
Hàm mất mát (loss function) BERT chỉ xem xét dự đoán các giá trị bị che và bỏ qua dự đoán của các từ không bị che. Kết quả là, mô hình hội tụ chậm hơn các mô hình định hướng nhưng được bù đắp bởi nhận thức ngữ cảnh tăng lên của nó. *Lưu ý: Trong thực tế, việc triển khai BERT phức tạp hơn một chút và không thay thế tất cả các từ được che dấu 15%. Xem Phụ lục A để biết thêm thông tin. *
 Hàm mất mát (loss function) BERT chỉ xem xét dự đoán các giá trị bị che và bỏ qua dự đoán của các từ không bị che. Kết quả là, mô hình hội tụ chậm hơn các mô hình định hướng nhưng được bù đắp bởi nhận thức ngữ cảnh tăng lên của nó. *Lưu ý: Trong thực tế, việc triển khai BERT phức tạp hơn một chút và không thay thế tất cả các từ được che dấu 15%. Xem Phụ lục A để biết thêm thông tin. *
Hàm mất mát (loss function) BERT chỉ xem xét dự đoán các giá trị bị che và bỏ qua dự đoán của các từ không bị che. Kết quả là, mô hình hội tụ chậm hơn các mô hình định hướng nhưng được bù đắp bởi nhận thức ngữ cảnh tăng lên của nó. *Lưu ý: Trong thực tế, việc triển khai BERT phức tạp hơn một chút và không thay thế tất cả các từ được che dấu 15%. Xem Phụ lục A để biết thêm thông tin. *Dự đoán câu tiếp theo (Next Sentence Prediction (NSP))
Trong quy trình đào tạo BERT, mô hình nhận các cặp câu làm đầu vào và học cách dự đoán nếu câu thứ hai trong cặp là câu tiếp theo trong tài liệu gốc. Trong quá trình đào tạo, 50% đầu vào là một cặp trong đó câu thứ hai là câu tiếp theo trong tài liệu gốc, trong khi 50% còn lại, một câu ngẫu nhiên từ kho văn bản được chọn làm câu thứ hai. Giả định là câu ngẫu nhiên sẽ bị ngắt kết nối từ câu đầu tiên.
Để giúp mô hình phân biệt giữa hai câu trong đào tạo, đầu vào được xử lý theo cách sau trước khi vào mô hình: 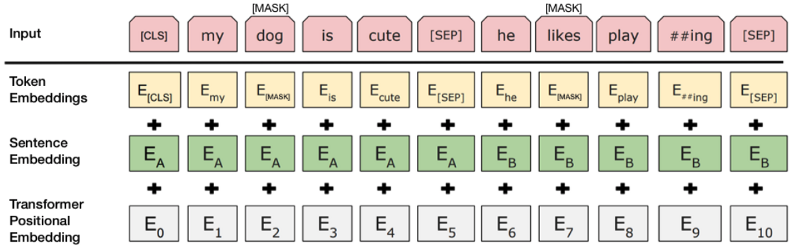 Source: BERT [Devlin et al., 2018], with modification
Source: BERT [Devlin et al., 2018], with modification
Để dự đoán nếu câu thứ hai thực sự được kết nối với câu đầu tiên, các bước sau đây được thực hiện:
1 2 3 | 1. Toàn bộ chuỗi đầu vào đi qua mô hình Transformer. 2. Đầu ra của mã thông báo [CLS] được chuyển thành vectơ dạng 2 × 1, sử dụng lớp phân loại đơn giản (ma trận đã học về trọng số và độ lệch). 3. Tính xác suất của câu tiếp theo với softmax. |
Khi thực hiện huấn luyện mô hình BERT, Masked LM và Dự đoán câu tiếp theo (NSP) được huấn luyện cùng nhau, với mục tiêu tối giản hóa sự kết hợp hàm mất mát của hai chiến lược.
Cách sử dụng BERT (Tinh chỉnh)
Sử dụng BERT cho một bài toán cụ thể là tương đối đơn giản:
BERT có thể được sử dụng cho nhiều bài toán ngôn ngữ, trong khi chỉ thêm một lớp nhỏ vào mô hình lõi:
- Các bài toán phân loại như phân tích tình cảm được thực hiện tương tự như phân loại Câu tiếp theo, bằng cách thêm một lớp phân loại trên đầu ra của Transfomer cho mã thông báo [CLS].
- Trong bài toán Trả lời Câu hỏi (Question Answering) (ví dụ: SQuAD v1.1), phần mềm nhận được một câu hỏi liên quan đến chuỗi văn bản và được yêu cầu đánh dấu câu trả lời trong chuỗi. Sử dụng BERT, một mô hình Hỏi và Đáp có thể được đào tạo bằng cách học thêm hai vectơ đánh dấu điểm bắt đầu và kết thúc của câu trả lời.
- Trong Nhận dạng thực thể được đặt tên (Named Entity Recognition (NER)), phần mềm nhận được một chuỗi văn bản và được yêu cầu đánh dấu các loại thực thể khác nhau (Người, Tổ chức, Ngày, v.v.) xuất hiện trong văn bản. Sử dụng BERT, một mô hình NER có thể được đào tạo bằng cách cung cấp vectơ đầu ra của mỗi mã thông báo vào một lớp phân loại dự đoán nhãn NER.
Trong đào tạo tinh chỉnh, hầu hết các siêu tham số giữ nguyên như trong đào tạo BERT và bài báo đưa ra hướng dẫn cụ thể (Phần 3.5) về các siêu tham số cần điều chỉnh. Nhóm BERT đã sử dụng kỹ thuật này để đạt được kết quả tốt trên nhiều bài toán ngôn ngữ tự nhiên đầy thách thức, được nêu chi tiết trong Phần 4 của bài nghiên cứu.
Những điều cần lưu ý
- Về vấn đề kích thước mô hình, thậm chí ở quy mô lớn. BERT_large, với 345 triệu tham số, là mô hình lớn nhất của loại hình này. Nó cực kỳ vượt trội so với các bài toán quy mô nhỏ so với BERT_base, sử dụng cùng kiến trúc với chỉ 110 triệu tham số.
- Với đủ dữ liệu đào tạo, nhiều bước đào tạo hơn tương ứng độ chính xác cao hơn. Chẳng hạn, trên tác vụ MNLI, độ chính xác của BERT_base cải thiện thêm 1% khi được đào tạo với 1 triệu bước (cỡ 128.000 từ) so với 500 nghìn bước.
- Cách tiếp cận hai chiều của BERT (MLM) hội tụ chậm hơn so với cách tiếp cận từ trái sang phải (vì chỉ có 15% từ được dự đoán trong mỗi đợt) nhưng đào tạo hai chiều vẫn vượt trội so với đào tạo từ trái sang phải.
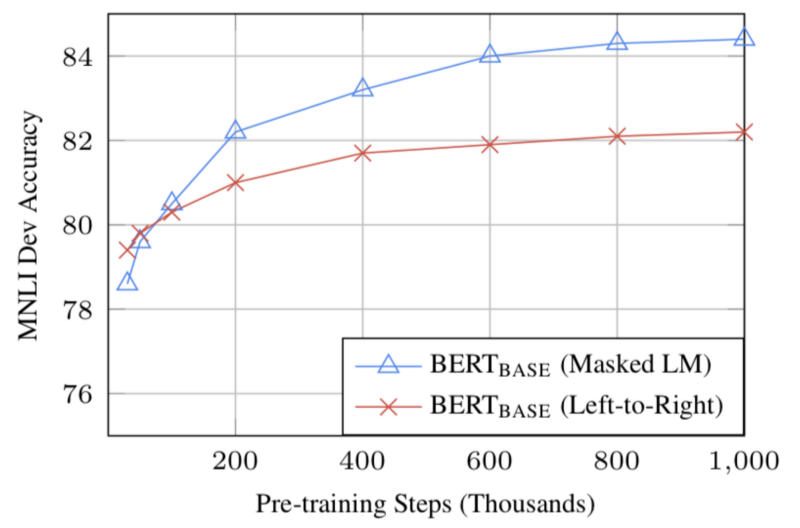
Source: BERT [Devlin et al., 2018], **
Cân nhắc tính toán (đào tạo và áp dụng)

Kết luận
BERT chắc chắn là một bước đột phá trong việc sử dụng Machine Learning để xử lý ngôn ngữ tự nhiên. Thực tế là nó có thể tiếp cận và cho phép tinh chỉnh nhanh sẽ có khả năng cho phép một loạt các ứng dụng thực tế trong tương lai. Trong bản tóm tắt này, chúng tôi đã cố gắng mô tả các ý chính của bài báo trong khi không đắm chìm trong các chi tiết kỹ thuật quá mức. Đối với những người muốn hiểu sâu hơn, chúng tôi khuyên bạn nên đọc toàn bộ bài viết và các bài viết phụ trợ được tham khảo trong đó. Một tài liệu tham khảo hữu ích khác là mã nguồn và mô hình BERT, bao gồm 103 ngôn ngữ và được nhóm nghiên cứu phát hành rộng rãi dưới dạng nguồn mở.
Phụ lục A – Mặt nạ từ (Word Masking)
Đào tạo mô hình ngôn ngữ trong BERT được thực hiện bằng cách dự đoán 15% mã thông báo trong đầu vào, được chọn ngẫu nhiên. Các mã thông báo này được xử lý trước như sau – 80% được thay thế bằng mã thông báo [[MASK]], 10% với một từ ngẫu nhiên và 10% sử dụng từ gốc. Trực giác khiến các tác giả chọn cách tiếp cận này như sau (Cảm ơn Jacob Devlin từ Google về cái nhìn sâu sắc):
- Nếu chúng tôi sử dụng [MASK] 100% thời gian thì mô hình sẽ nhất thiết phải tạo ra các biểu diễn mã thông báo tốt cho các từ không bị che. Các mã thông báo không đeo mặt nạ vẫn được sử dụng cho ngữ cảnh, nhưng mô hình đã được tối ưu hóa để dự đoán các từ bị che.
- Nếu chúng tôi sử dụng [MASK] 90% thời gian và các từ ngẫu nhiên 10% thời gian, điều này sẽ dạy cho mô hình rằng từ observe không bao giờ đúng.
- Nếu chúng tôi sử dụng [MASK] 90% thời gian và giữ nguyên từ trong 10% thời gian, thì mô hình có thể sao chép phi ngữ cảnh.
Không cắt bỏ được thực hiện trên các tỷ lệ của phương pháp này, và nó có thể đã làm việc tốt hơn với các tỷ lệ khác nhau. Ngoài ra, hiệu suất mô hình đã không thử nghiệm với che giấu 100% mã thông báo được chọn
Tài liệu tham khảo
- https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
- https://arxiv.org/abs/1810.04805
- https://vi.wikipedia.org/wiki/Hàm_softmax
Nguồn bài viết : viblo.asia