Trong bài viết này, chúng ta sẽ cùng tìm hiểu về neo4j, các khái niệm cơ bản về cơ sở dữ liệu dạng đồ thị
I. Khái niệm về cơ sở dữ liệu đồ thị
1. Ví dụ về đồ thị
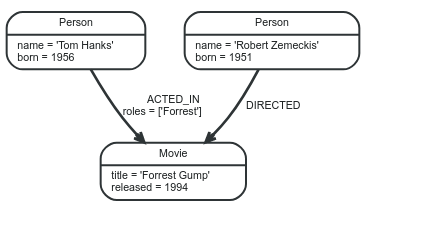
Ở đây chúng ta sẽ cùng nhau xem xét một ví dụ cơ bản về đồ thị (hình vẽ phía bên dưới) để hiểu rõ hơn về khái niệm cũng như là các thuộc tính đồ thị.
2. Nodes
Nodes thường được sử dụng để biểu diễn các thực thể (entities). Đồ thị đơn giản nhất là đồ thì mà trong đó chỉ có duy nhất một node. Quay trờ lại với hình vẽ phía trên chúng ta có thể coi
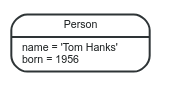
là một node cơ bản.
3. Labels
Labels có thể được sử dụng để mô hình hóa miền giá trị của các node lại với nhau, thông thường chúng ta sẽ gộp nhóm các node có cùng kiểu dữ liệu hoặc là thuộc tính thành một tập hợp rồi sau đó gắn label vào cho chúng.
Ví dụ, tất cả những nodes mà biểu diễn cho một đối tượng là users thì có thể được gắn labels là :Users. Lúc này bạn có thể thuận tiện làm việc với neo4j thông qua các nodes đã được gắn labels này, chẳng hạn như là tìm tất cả các users có tên khớp với ABC,….
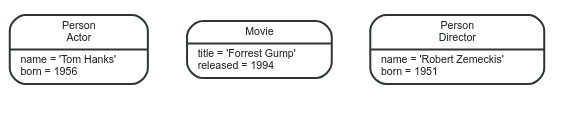
Mỗi một node thì có thể có một hoặc nhiều lables, ở hình vẽ ví dụ ban đầu, các nodes sẽ có các nhãn tương ứng là Person và Movie. Ta có thể thấy mỗi một nhãn lúc này sẽ biểu diễn một lớp đối tượng khác nhau. Nhưng trong những bài toán khác khi mà chúng ta muốn biểu diễn thêm những chiều khác nhau của dữ liệu(different dimensions of the data) thì sao? Lúc này bạn có thể thêm labels vào cho các nodes. Hình vẽ phía bên dưới sẽ minh họa rõ hơn cho việc sử dụng nhiều labels cho cùng một node.
4. Relationships
Relationships đúng như cái tên của nó đó là sẽ biểu mối quan hệ, hay liên kết giữa các node với nhau. Ngoài ra relationship còn có thể cấu trúc phân chia các nodes thành những cấu trúc khác nhau, biến đồ thị thành các dạng cấu trúc giống như là list, tree, map, hoặc có thể là thực thể phức hợp (compound entity). Thực thể phức hợp là thực thể có nhiều liên kết phức tạp liên kết với nhau.
Các relationships sẽ giúp cho đồ thị sẽ có ý nghĩa hơn, gẫn gũi với bài toán thực tế hơn.
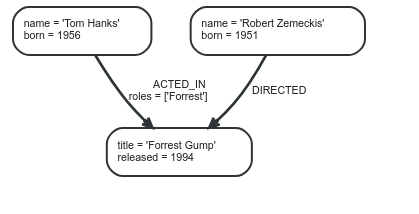
Ở đây ta có thể thấy có hai quan hệ (liên kết) ở trong đồ thị đó có 2 quan hệ liên kết, hai liên kết này giúp cho chúng ta có thể hiểu rõ hơn về dữ liệu mà chúng ta đang có.
5. Relationship types
Mỗi một relationship chỉ được phép có đúng một Relationship type. Ở ví dụ phần mở đầu chúng ta đã sử dụng ACTED_IN và DIRECTED như là 2 kiểu liên kết đến thực thể. Thuộc tính roles trong liên kết ACTED_IN có cấu trúc dữ liệu là một array với chỉ một phần tử trong nó.
Với việc sử dụng liên kết ACTED_IN, với node Tom Hanks ta có thể hiểu đây chính là source node và node Forrest Gump là target node

Ta có thể dễ dàng nhìn thấy được là node Tom Hanks đang hướng đến node Forrest Gump. Chú ý một điều là Relationships luôn luôn phải có hướng (direction).
Một node cũng có thể có Relationships đến chính nó. Nếu như chúng ta muốn biểu diễn Tom Hanks KNOWNS đến chính bản thân node đó, chúng ta có thể biểu diễn như sau:
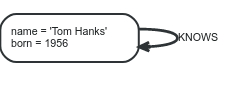
6. Properties
Properties là một cặp name-value, được dùng để biểu diễn cho các thuộc tính của các nodes cũng như là các relationships.
Trong ví dụ về đồ thị ban đầu chúng ta sử dụng các properties là name và born cho các nodes có labels là Person, title và released cho node Movie. Đồng thời ta cũng sử dụng property roles trong :ACTED_IN liên kết.
Các property có thể lưu trữ các kiểu dữ liệu đa dạng khác nhau như là number, string và boolean với các miền giá trị tương ứng. Để hiểu rõ hơn về vấn đề này chúng ta có thể tìm hiểu thêm phần Cypher manual
7. Traversals and paths
Traversals là cách để làm thế nào có thể truy vấn được cơ sở dữ liệu đồ thị. Traversals đồ thị có nghĩa là duyệt qua tất cả các nodes bằng cách “lần” theo các liên kết (following relationships) và phải tuân thủ theo một số luật nhất định. Trong hầu hết các trường hợp chúng ta sẽ chỉ phải duyệt qua các tập con của đồ thị mà không cần phải duyệt toàn bộ đồ thị.
Trong ví dụ phần mở đầu, nếu muốn tìm ra movie mà Tom Hanks đã acted , traversal sẽ bắt đầu từ node Tom Hanks, đi theo relationship ACTED_IN và nhận thấy relationship này có liên kết với một node….và cuối cùng Forrest Gump chính là kết quả mà chúng ta cần tìm kiếm. (Bạn có thể nhìn đường nét đứt để có thể hiểu rõ hơn)
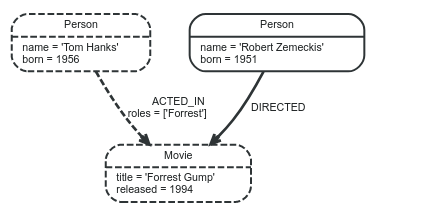
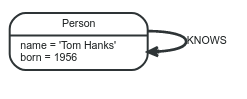
Ở đây ta dễ dàng thấy được rằng chi phí để tìm ra được kết quả là 1. Path ngắn nhất là path có độ dài bằng zero. Nó chính là 1 node đơn và không có relationship (như hình vẽ phía dưới).

Còn đây chính là path với độ dài là 1:
Nguồn tham khảo:
[1] https://neo4j.com/docs/getting-started/current/graphdb-concepts/#graphdb-properties