
Giới thiệu
Bad programmers worry about the code. Good programmers worry about data structures and their relationships — Linus Torvalds
Thật là quá đúng. Đó là lý do tại sao mọi nhà tuyển dụng tìm kiếm một ứng viên có hiểu biết tốt về Cấu trúc dữ liệu trong các các buổi phỏng vấn. Điều này cũng đúng cho các Android developer.
Trong blog này, chúng ta sẽ đề cập đến tất cả các Data Structure cần thiết cho bất kỳ Android developer. Mặc dù còn nhiều điều cần tìm hiểu, chúng ta sẽ đề cập đến những câu hỏi được sử dụng nhiều nhất và thường xuyên nhất trong Phỏng vấn Android.
Nguồn: https://blog.mindorks.com/android-developer-should-know-these-data-structures-for-next-interview
Data Structure là gì?
Data Structure là định dạng tổ chức, quản lý và lưu trữ dữ liệu cho phép truy cập và sửa đổi hiệu quả.
Chính xác hơn, Data Structure là tập hợp các giá trị dữ liệu, mối quan hệ giữa chúng và các chức năng hoặc hoạt động có thể được áp dụng cho dữ liệu.
Ví dụ: chúng ta có một số dữ liệu của một người có name “ABC” và age 25. Ở đây, “ABC” có kiểu dữ liệu String và 25 là kiểu dữ liệu interger.
Chúng ta có thể sắp xếp dữ liệu này dưới dạng bản ghi giống như bản ghi User, sẽ có cả tên người dùng và tuổi trong đó. Bây giờ chúng ta có thể thu thập và lưu trữ các bản ghi người dùng trong một tệp hoặc cơ sở dữ liệu dưới dạng cấu trúc dữ liệu.
Bây giờ, hãy cùng tìm hiểu về cấu trúc dữ liệu được sử dụng nhiều nhất và thường được hỏi trong Android.
Cấu trúc dữ liệu được sử dụng nhiều nhất và được hỏi nhiều nhất trong Android
- Array
- Linked List
- Hash Table
- Stack
- Queue
- Tree
- Graph
Array
Mảng là cấu trúc dữ liệu được sử dụng nhiều nhất và dễ nhất được sử dụng để lưu trữ cùng loại dữ liệu. Mảng là một tập hợp các mục tương tự được lưu trữ ở các vị trí bộ nhớ liền kề.
Ví dụ: nếu bạn đang lưu trữ điểm của 10 sinh viên thì bạn có thể thực hiện việc này bằng cách tạo 10 biến số nguyên cho mỗi sinh viên và bạn có thể lưu trữ điểm trong các biến này. Nhưng bạn phải quản lý 10 biến khác nhau ở đây, đây là một nhiệm vụ rất khó khăn vì nếu trong tương lai bạn phải lưu trữ 1000 điểm của sinh viên, thì bạn phải tạo 1000 biến nếu bạn đang theo phương pháp này.
Vì vậy, chúng ta có thể sử dụng mảng cho mục đích này. Tất cả những gì bạn cần làm chỉ là tạo ra một mảng có tên là marks có kích thước 10 hoặc 1000 hoặc bất cứ thứ gì khác và sau đó lưu trữ các dấu trong mảng đó.
LƯU Ý: Trong hầu hết tất cả các ngôn ngữ lập trình, chúng ta sử dụng index dựa trên 0, tức là index của mảng sẽ bắt đầu từ 0 và đi đến n-1 trong đó, n n là kích thước của mảng.
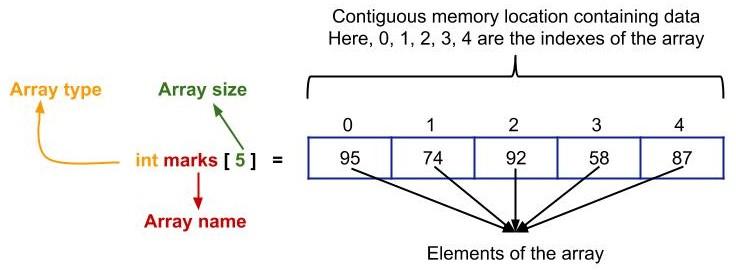
Bạn có thể truy cập các phần tử của mảng với sự trợ giúp của các chỉ mục của nó:
1 2 3 4 | marks<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token comment">// to access the 1st element i.e. element at index 0</span> marks<span class="token punctuation">[</span><span class="token number">2</span><span class="token punctuation">]</span> <span class="token comment">// to access the 3rd element i.e. element at index 2</span> marks<span class="token punctuation">[</span><span class="token number">4</span><span class="token punctuation">]</span> <span class="token comment">// to access the 5th element i.e. element at index 4</span> |
Một số thao tác cơ bản trên Mảng:
- Insertion: Chèn một phần tử đã cho vào một chỉ mục cụ thể của mảng
- Deletion: Xóa một phần tử đã cho khỏi mảng
- Searching: Tìm kiếm một phần tử cụ thể trong mảng
- Updation: Cập nhật một phần tử của một mảng tại một chỉ mục cụ thể
- Traversing: In hoặc duyệt toàn bộ mảng
Linked List
Một Linked List gần như tương tự với một mảng, tức là nó cũng là một cấu trúc dữ liệu tuyến tính để lưu trữ cùng loại dữ liệu. Ở đây, dữ liệu không được lưu trữ một cách liên tục. Dữ liệu được lưu trữ trong danh sách được liên kết ở dạng nodes và mỗi node có thể được kết nối với node khác với sự trợ giúp của một số con trỏ hoặc tham chiếu đến node tiếp theo.
Vì vậy, có hai phần của một node trong danh sách được liên kết, tức là phần dữ liệu và con trỏ hoặc phần tham chiếu. Phần dữ liệu lưu trữ dữ liệu của node, trong khi con trỏ hoặc phần tham chiếu lưu địa chỉ của node tiếp theo (nếu có).

Hình ảnh trên là một ví dụ về Linked List đơn lẻ, tức là ở đây chúng tôi chỉ có địa chỉ của node tiếp theo. Có một Linked list khác được gọi là “Doubly linked list”, trong đó địa chỉ của node trước và node tiếp theo được giữ bởi bất kỳ node nào. Ngoài hai loại danh sách được liên kết này, chúng ta còn có một “Circular linked list”.
Ở đây trong hình ảnh trên, Head đang chỉ vào node đầu tiên của linked list và node cuối cùng của linked list đang trỏ đến Null, tức là không có node nào xuất hiện sau node đó.
Một số thao tác cơ bản trên Linked List:
- Insertion: Tại đây, bạn có thể chèn node vào linked list. Bạn có thể chèn node vào bất kỳ nơi nào của linked list.
- Deletion: Trong thao tác xóa, bạn có xóa node từ bất kỳ node nào khỏi linked list.
- Searching: Bạn sẽ được cung cấp một yếu tố và bạn phải tìm kiếm yếu tố đó trong Linked list.
- Traversing: Di chuyển toàn bộ danh sách được liên kết để có được từng phần tử của Linked list.
Hash Table
Hash Table là một loại cấu trúc dữ liệu được sử dụng để lưu trữ dữ liệu dưới dạng cặp khóa Key-Value. Bạn sẽ có một số giá trị hoặc dữ liệu và dựa trên dữ liệu đó, bạn sẽ tạo một khóa và với sự trợ giúp của khóa đó, bạn sẽ lưu trữ giá trị trong Bảng Hash. Nếu đầu vào được phân phối đồng đều thì Bảng Hash sẽ thực hiện thao tác chèn, xóa và tìm kiếm trong thời gian O (1).
Quá trình tạo khóa và lưu trữ dữ liệu dựa trên khóa đó được gọi là Xóa Hashing. Để tạo khóa từ dữ liệu, chúng ta cần một hàm được gọi là Hàm Hash Hash. Hàm Hash sẽ lấy dữ liệu làm đầu vào và đưa khóa làm đầu ra.
Ví dụ: Nếu dữ liệu được lưu trữ là: 1, 2, 3, 4, 5, 26, 17 và hàm băm được sử dụng là:
1 2 | <span class="token function">hashFunction</span><span class="token punctuation">(</span>k<span class="token punctuation">)</span><span class="token operator">:</span> k <span class="token operator">%</span> <span class="token number">10</span> |
Và dữ liệu sẽ được lưu trữ trong Bảng Hash theo cách sau:
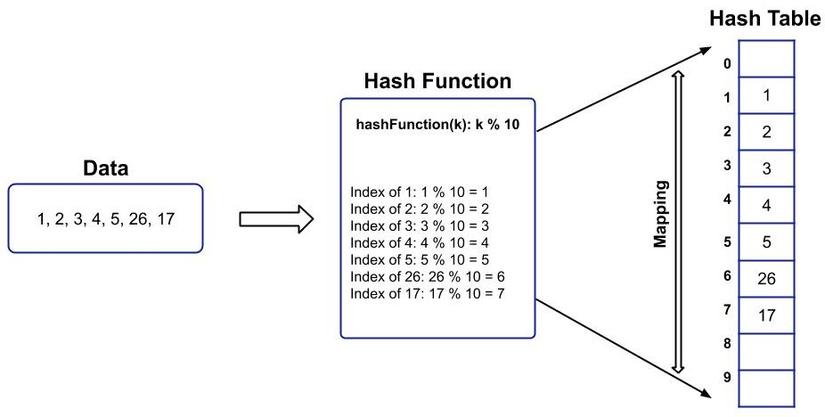
Những điểm cần suy nghĩ khi sử dụng Bảng Hash:
- Hàm Hash phải sao cho các khóa được tạo được phân phối đồng đều.
- Kích thước của Bảng Hash phụ thuộc vào Hàm Hash. Vì vậy, việc lựa chọn Hàm Hash nên được thực hiện hoàn hảo.
- Trong trường hợp va chạm trong Bảng Hash, hãy áp dụng kỹ thuật xử lý va chạm thích hợp.
Stack
Một Stack là một cấu trúc dữ liệu tuyến tính sử dụng thứ tự Last In First Out (LIFO), tức là phần tử được chèn cuối cùng sẽ được bật ra trước. Ví dụ: nếu bạn đặt một cuốn sách lên trên những cuốn sách khác và tiếp tục quá trình này trong 50 cuốn sách, thì cuốn sách trên cùng sẽ được tìm nạp trước. Ở đây bạn có thể nhận thấy rằng cuốn sách trên cùng là cuốn sách được đặt ở cuối hoặc được đặt gần đây.
Trong Stack, chúng ta có một biến Top mà biểu thị đỉnh của Stack. Điều này là cần thiết bởi vì tất cả các hoạt động của ngăn xếp được thực hiện với sự trợ giúp của biến Top .
Sau đây là một ví dụ về Stack:
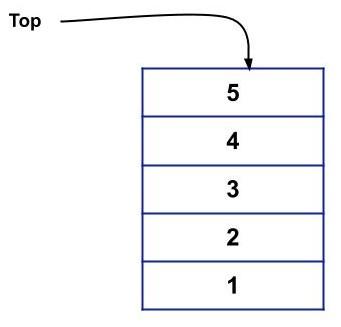
Nếu bạn muốn xóa các phần tử khỏi Stack ở trên, thì 5 sẽ bị xóa trước, tiếp theo là 4, 3, 2 và 1.
Một số thao tác cơ bản trên Stack:
- Push(): Push được sử dụng để chèn một phần tử ở đầu ngăn xếp.
- Pop(): Pop được sử dụng để xóa một phần tử khỏi đỉnh ngăn xếp.
- Top: Top được sử dụng để biểu thị phần tử trên cùng của ngăn xếp.
Queue
Queue là Cấu trúc dữ liệu tuyến tính sử dụng thứ tự First In First Out (FIFO), tức là phần tử đến trước trong Hàng đợi sẽ bị xóa đầu tiên khỏi Hàng đợi. Ví dụ: trong khi đứng xếp hàng để đặt vé, người đến trước sẽ đặt vé trước và người mới đến đặt vé phải đứng ở cuối Hàng đợi.
Trong Queue, chúng ta có các Front và Rear. Font được sử dụng để trỏ đến phần tử phía trước của Queue trong khi Rear được sử dụng để trỏ đến phần tử phía sau của Queue.
Sau đây là một ví dụ về Hàng đợi:
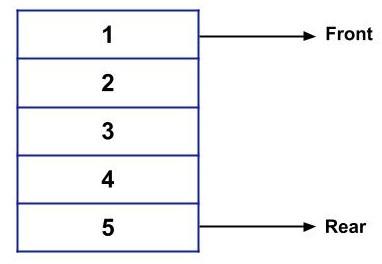
Vì vậy, nếu bạn muốn xóa các thành phần khỏi hàng đợi trên, thì 1 sẽ bị xóa trước, tiếp theo là 2, 3, 4 và 5.
Tương tự, nếu bạn muốn chèn một phần tử trong hàng đợi ở trên thì nó sẽ được chèn từ Rear chứ không phải từ Front.
Một số thao tác cơ bản trên Queue:
- Enqueue(): Enqueue được sử dụng để chèn một phần tử vào cuối Queue.
- Dequeue(): Dequeue được sử dụng để xóa một phần tử từ phía trước Queue.
- Front: Nó được sử dụng để biểu thị thành phần phía trước của Queue.
- Rear: Nó được sử dụng để biểu thị thành phần Phía sau của Queue.
Tree
Tree là một cấu trúc dữ liệu phi tuyến tính, phân cấp, được sử dụng để lưu trữ dữ liệu dưới dạng các node. Ở đây, chúng ta có node và tất cả các node được kết nối với nhau với sự trợ giúp của các cạnh được vẽ giữa chúng. Một node cha có thể không có con hoặc một con hoặc nhiều hơn một con. Nhưng node con không thể có nhiều hơn một cha.
Sau đây là một ví dụ đơn giản về Tree:
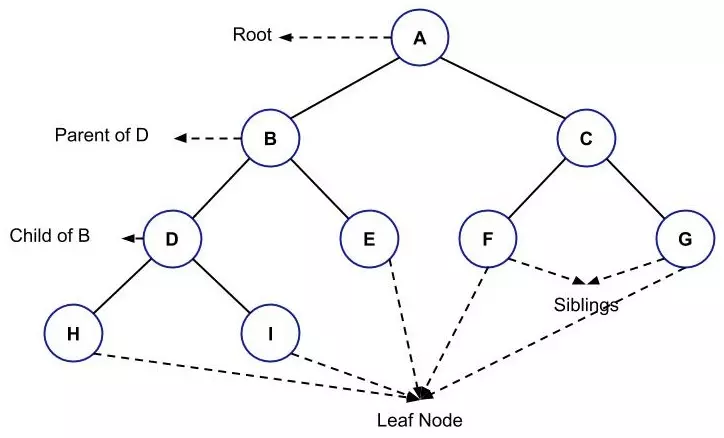
Một số thuật ngữ liên quan đến Tree là:
Root: Root là node có mặt ở đầu tree. Chỉ có thể có một gốc của một tree cụ thể.
Parent: Tất cả các node có ít nhất một con được gọi là node cha.
Child: node bên dưới node cha được gọi là node con của node cha.
Leaf: node không có con được gọi là node Leaf.
Một số loại cây là:General Tree
Binary Tree
Binary Search Tree
AVL Tree
Red-Black Tree
N-ary Tree
Graph
Graph tương tự như Tree, tức là nó cũng là cấu trúc dữ liệu phi tuyến tính lưu trữ dữ liệu dưới dạng các node và tất cả các node được kết nối với nhau với sự trợ giúp của các cạnh. Sự khác biệt giữa Tree và Graph là có một chu kỳ trong Graph nhưng không có chu trình như vậy trong trường hợp của Tree.
Graph bao gồm một tập hợp các node hữu hạn và một tập hợp các cạnh hữu hạn chịu trách nhiệm kết nối các node.
Sau đây là một ví dụ về đồ thị:
Sau đây là các loại biểu đồ:
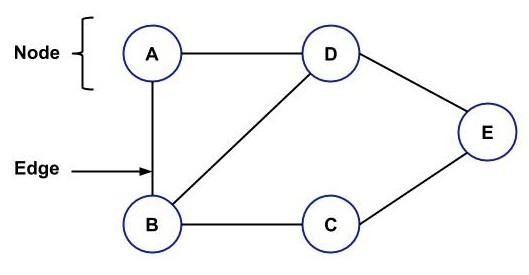
Directed Graph: Ở đây các cạnh sẽ trỏ đến một số node, tức là bạn sẽ có một mũi tên chỉ vào một node từ một node.
Undirected Graph: Ở đây không có mũi tên nào ở giữa các node. Ví dụ trên là một ví dụ về đồ thị vô hướng.
Một số kỹ thuật truyền tải đồ thị phổ biến là:Depth-First Search(DFS)
Breadth-First Search(BFS)
Kết luận
Trên đây là một số kiến thức về Data Structure, hi vọng bài viết này sẽ giúp bạn có 1 buổi phỏng vấn thành công 