5 lỗi thiết kế cơ sở dữ liệu đơn giản cần tránh
- Linh Le
Anith tiếp nối bài báo thành công trước đó có tên “Các sự thật và Hiểu nhầm về Dạng chuẩn 1 (1NF)” bằng một cuộc thảo luận đầy lôi cuốn về 5 lỗi thiết kế CSDL phổ biến vẫn cứ xảy ra mặc cho những hậu quả chẳng mấy hay ho của chúng đều đã được mọi người biết đến quá nhiều. Đây chính là lời nhắc nhở cần thiết cho bất kỳ ai khi thiết kế CSDL.
Hầu hết mọi người trong ngành đều nhận thức được sự nguy hại của việc thiết kế CSDL không đạt tiêu chuẩn nhưng lại bỏ qua chúng trong những CSDL thực tế. Những sai lầm thiết kế tai hại thường bị bỏ ngơ. Trong một số trường hợp, những hạn chế của hệ thống quản trị CSDL hay ngôn ngữ SQL có thể góp phần tạo nên những vấn đề này. Trong những trường hợp khác, có thể là do người thiết kế CSDL thiếu kinh nghiệm, chỉ tập trung vào việc viết ra những đoạn code kì lạ mà lại không tập trung vào việc xây dựng một mô hình dữ liệu thật tốt.
Nói đơn giản, thiết kế CSDL chính là quá trình chuyển những dữ liệu của thế giới thực vào một mô hình logic (logical model). Sau đó mô hình này sẽ được thực thi, thường là cùng với CSDL quahệ (relational database). Mặc dù các CSDL quan hệ có cơ sở logic và toán học tập hợp vững chắc, nhưng sự nghiêm ngặt về mặt khoa học của quá trình thiết kế CSDL cũng liên quan tới thẩm mỹ và trực giác, tất nhiên là nó cũng bao gồm cả khuynh hướng chủ quan của người thiết kế. Tuy nhiên điều này ảnh hưởng tới thiết kế ra sao? Trong bài viết này, tôi sẽ cố gắng giải thích 5 lỗi thiết kế phổ biến mà mọi người phạm phải trong quá trình mô hình hóa các bảng và đưa ra vài chỉ dẫn cách làm thế nào để tránh các lỗi đó.
(1) Lookup table (bảng tra cứu) phổ biến
Cách đây vài năm, Don Peterson đã viết một bài báo cho SQL Server Central có đề cập chi tiết về cách tạo một bảng tra cứu phổ biến cho các loại dữ liệu khác nhau được gọi là bảng mã (code table) hay “bảng giá trị cho phép” (AVT). Các bảng này thường khá đồ sộ và có nhiều dữ liệu không liên quan. Cũng khá phù hợp khi Don gọi những bảng này với cái tên là bảng mã khóa hợp nhất to lớn (Massively Unified Code-Key – MUCK). Mặc dù đã có nhiều người khác viết về nó trong suốt những năm qua nhưng cái tên này có vẻ phù hợp nhất với sự rối rắm của một cấu trúc bảng như thế.
Trong nhiều trường hợp, dữ liệu trong những bảng này thuộc kiểu VARCHAR(n) mặc dù kiểu dữ liệu thực tế của những giá trị này có thể thuộc bất kì kiểu nào từ INTERGER cho đến DAETTIME. Hầu hết chúng được biểu diễn qua 3 cột với một số hình thức như bảng ví dụ (Hình 1)
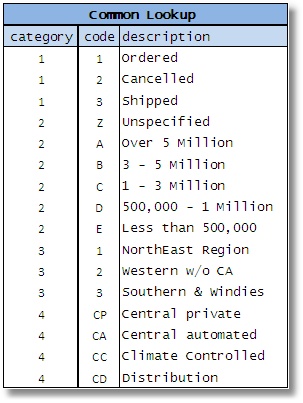
Hình 1
Cách sắp xếp ở đây chính là mỗi phần tử trong ví dụ đều có một bộ các thuộc tính tương tự nhau và vì thế có thể đưa vào cùng một bảng. Sau cùng sẽ thu được ít bảng hơn, giúp cho CSDL đơn giản hơn phải không nào?
Trong suốt quá trình xử lý thiết kế, người thiết kế CSDL có thể gặp phải một số bảng nhỏ hơn (ví dụ những bảng thể hiện những kiểu phân biệt của các phần tử như “trạng thái đặt hàng” (status of orders), “độ ưu tiên của tài sản tài chính” (priority of financial assests), “mã vị trí” (location code), “loại kho” (type of warehouse), v.v.
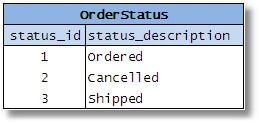
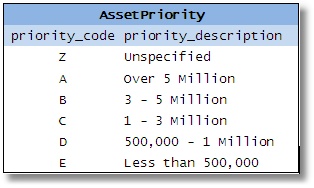
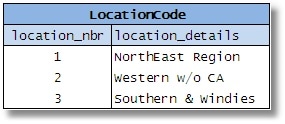

Hình 2-5
Sau đó người thiết kế sẽ kết hợp tất cả chúng lại với nhau vì các cột tương tự nhau. Anh ta cho rằng mình sẽ loại bỏ các bảng dư thừa đi và đơn giản hóa CSDL, từ đó sẽ giảm được số lượng bảng, tiết kiệm không gian, cải thiện hiệu quả, v.v. Mọi người cũng cho rằng điều này sẽ giảm tính phức tạp của SQL được yêu cầu, bởi vì một quy trình được lưu trữ/một lộ trình đơn lẻ có thể được viết nhằm truy cập bất cứ kiểu dữ liệu nào
Thế thì vấn đề ở đây là gì?
- Đầu tiên, bạn đã làm mất ý nghĩa của việc đảm bảo cho dữ liệu được chính xác; tính ràng buộc. Chính hành động kết hợp các phần tử khác nhau vào một bảng duy nhất mà bạn không có các phương tiện khai báo nhằm giới hạn những giá trị của một loại nhất định nào đó. Không có cách nào dễ dàng để thực thi những ràng buộc của khóa ngoại (foreign key) đơn giản mà không phải thêm giá trị categoryid trong tất cả các khóa tham chiếu cả.
- Thứ hai, bạn bắt buộc phải biểu diễn từng kiểu dữ liệu dưới dạng một chuỗi thuộc cùng kiểu này trong bảng tra cứu chung. Việc trộn lẫn các kiểu dữ liệu khác nhau có thể gây ra vấn đề, bởi vì kiểm tra ràng buộc không thể được thực thi mà không có hành động hack code trên diện rộng. Trong ví dụ chúng tôi đưa ra, nếu đoạn code giảm giá thuộc kiểu CHAR(3) và location_nbr thuộc kiểu INT(4), thì kiểu dữ liệu của cột “code” sẽ là gì trong bảng tra cứu chung?
- Thứ ba, bạn tự mình làm cho thiết kế cứng nhắc và khó khăn về sau. Bạn có thể tự hỏi rằng làm sao mà một thiết kế linh hoạt và đơn giản như thế lại cứng nhắc được? Hãy xem xét ví dụ về sơ đồ bảng tra cứu chung của chúng tôi, tưởng tượng rằng bảng “LocationCode” bao gồm những cột khác có thể là “region”. Hậu quả của việc thêm một trạng thái vào bảng “DiscountType” là gì? Để thay đổi một hạng mục, bạn sẽ phải cân nhắc chuyện nhường chỗ cho tất cả các hàng trong bảng bất kể rằng cột mới có thể áp dụng lên chúng được hay không. Về tính phức tạp thì sao? Thông thường ý tưởng sử dụng các bảng tra cứu chung xuất phát từ ý tưởng khái quát hóa các phần tử trong một bảng biểu diễn một “thứ” nào đó nhiều hơn bất cứ thứ gì khác.
Ngược lại với quy tắc cơ bản này là một bảng được thiết kế tốt thể hiện một bộ những dữ liệu về phần tử hoặc các mối quan hệ cùng loại. Vấn đề trong việc khái quát hóa phần tử là bảng tra cứu sẽ trở thành một đống nhiều hàng không liên quan nhau: Hậu quả là bạn sẽ làm mất đi tính chính xác của ý nghĩa, sau đó là sự lúng túng và thường là những phức tạp không mong muốn.
Mục đích chính của hệ quản trị cơ sở dữ liệu DBMS là nhằm thực thi những quy tắc quản lí cách mà dữ liệu được trình bày và điều khiển. Hãy đảm bảo rằng bạn không nhầm lẫn giữa các thuật ngữ “khái quát hóa”, “sử dụng lại”, v.v trong văn cảnh thiết kế CSDL, nơi mà bạn không có quyền kiểm soát những gì đang được thiết kế. - Thứ tư và cũng là điều cuối cùng, bạn đối mặt với vấn đề thực thi về mặt vật lý. Trong khi việc thiết kế logic được xem là hoàn toàn tách biệt với việc thực thi vật lý thì trong các sản phẩm DBMS như server SQL, việc thực thi vật lý có thể bị ảnh hưởng bởi thiết kế logic và ngược lại. Với những hãng lớn, những bảng tra cứu chung có thể lên đến hàng trăm hoặc hàng ngàn hàng và yêu cầu sự điều chỉnh bảng vật lý rất nhiều. Các vấn đề trùng lặp và khóa trong những bảng lớn như thế cũng phải được kiểm soát. Việc biểu diễn nội bộ của một nhóm hàng chuyên biệt của bảng trong bộ nhớ vật lý có thể là một yếu tố quyết định xem các giá trị có thể được truy cập và xử lý bằng truy vấn SQL hiệu quả tới đâu.
Lời đề xuất chung đó là luôn luôn dùng các bảng tách biệt nhau cho từng phần tử logic, xác định các cột thích hợp với từng kiểu dữ liệu, các ràng buộc và tham chiếu chính xác. Tốt hơn là nên viết một đoạn chương trình và thủ tục để truy cập và xử lý dữ liệu trong các bảng mà không hướng tới code động (dynamic code).
Bảng tra cứu chung không phù hợp với thiết kế CSDL nhạy cảm, dù là dưới hình thức sửa chữa tạm thời ngắn hạn hay là một giải pháp khả thi lâu dài đi chăng nữa. Mặc dù tính toàn vẹn được thực thi trong ứng dụng đôi khi được các lập trình viên ưa chuộng hơn, nhưng DBMS phải là nhân tố bắt buộc trung tâm của toàn bộ tính toàn vẹn. Bởi vì mục tiêu hàng đầu của việc thiết kế CSDL cho sẵn là nhằm duy trì tính toàn vẹn và đúng đắn logic của dữ liệu, nên các bảng tra cứu chung chính là một trong những sai lầm tệ hại nhất mà một lập trình viên có thể phạm phải.
(2) Câu hỏi khó cho ràng buộc kiểm tra
Ràng buộc kiểm tra phục vụ nhiều mục đích, nhưng lại gây ra khó khăn cho các nhà thiết kế theo 2 hướng sau:
- Họ bỏ sót việc khai báo (declare) các ràng buộc kiểm tra thích hợp khi cần thiết.
- Họ không nhận biết được khi nào thì dùng một ràng buộc mức cột (column level) thay vì một bảng có ràng buộc khóa ngoại.
Các ràng buộc trong SQL Server có thể phục vụ nhiều mục đích khác nhau, bao gồm cả việc hỗ trợ các ràng buộc theo miền (domain constraint), ràng buộc theo cột và, ở một mức độ nào đó, có thể là ràng buộc theo bảng. Mục đích cơ bản của một CSDL là để bảo toàn tính toàn vẹn của dữ liệu, và các ràng buộc được định nghĩa tốt đem đến những phương thức tuyệt vời để kiểm soát những giá trị nào được cho phép trong một cột.
Thế thì bạn có nên tránh việc sử dụng ràng buộc kiểm tra hay không? Vâng, hãy cùng nhau xem xét các trường hợp khi mà một bảng tham chiếu (bảng có khóa ngoại) có thể được sử dụng nhằm giới hạn cột bằng một bộ các giá trị cụ thể.

Hình 6
Ở đây, các giá trị ins_code trong bảng PolicyHolders có thể được giới hạn theo 2 cách. Cách đầu tiên liên quan tới việc sử dụng một bảng tra cứu có các giá trị cho phép với ins_code. Cách thứ hai là dùng ràng buộc kiểm tra cho bảng PolicyHolders như sau:
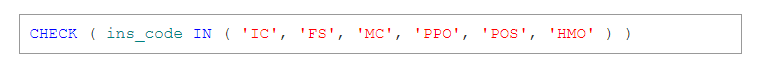
Vậy thì kinh nghiệm chọn phương pháp đúng đắn là gì? Những người lão luyện trong thiết kế CSDL xem xét 3 tiêu chí cụ thể nhằm điều chỉnh lựa chọn của họ giữa việc dùng ràng buộc kiểm tra hay dùng bảng riêng có chứa ràng buộc khóa ngoại.
- Nếu danh sách các giá trị thay đổi theo thời gian, bạn phải dùng một bảng tách biệt có ràng buộc khóa ngoại hơn là ràng buộc kiểm tra.
- Nếu danh sách giá trị có số lượng lớn hơn 15 hoặc 20 thì bạn nên cân nhắc chuyện dùng một bảng tách biệt.
- Nếu danh sách các giá trị được chia sẻ hoăc được sử dụng lại tối thiểu 3 lần hoặc hơn trong cùng CSDL thì bạn càng cớ cơ sở để dùng một bảng tách biệt.
Chú ý rằng thiết kế CSDL là một sự kết hợp giữa nghệ thuật và khoa học, vì vậy cần phải cân bằng giữa hai yếu tố này. Một người thiết kế có kinh nghiệm có thể giữ cân bằng cho hai yếu tố này dựa trên đánh giá tường tận về những yêu cầu cụ thể.
(3) Entity – Attribute – Value table (EAV: Phần tử – Thuộc tính- Bảng giá trị)
Lý tưởng thì một bảng sẽ thể hiện một bộ các phần tử, mỗi phần tử của bảng có một bộ các thuộc tính được thể hiện qua các cột. Đôi khi, các nhà thiết kế có thể bị cuốn vào một thế giới “mô hình” (paradigms) lập trình thay thế và cố gắng thiết lập chúng. Một mô hình như thế được gọi là mô hình Phần tử – Thuộc tính – Giá trị (hoặc trong một số ngữ cảnh gọi là object-attribute-model), đó cũng là tên thường gọi cho một bảng có 3 cột, một cột đại diện cho kiểu dữ liệu của phần tử, một cột dành cho thông số hoặc thuộc tính hay tính chất của phần tử đó và cột thứ ba là giá trị thực tế của tính chất đó.
Hãy xem qua ví dụ bên dưới về một bảng ghi lại những dữ liệu của nhân viên:
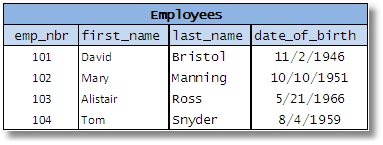
Hình 7
Lúc này phương pháp EAV đảo lộn các dữ liệu nhằm thể hiện các thuộc tính dưới dạng các giá trị ở một cột và các giá trị tương ứng với các thuộc tính đó nằm ở cột khác.
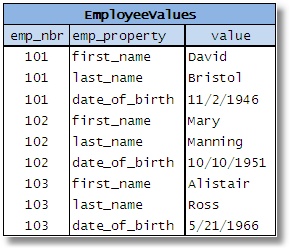
Hình 8
Tới đây thôi, không cần phải có thêm nhiều bảng, tất cả các dữ liệu đều có thể được để chung vào một bảng duy nhất. Phát minh này được biết đến nhờ vào vai trò của những nhà thiết kế CSDL đơn giản, những người này quyết định rằng khi các yếu tố dữ liệu là vô danh, được nhận biết một phần hoặc khó nhận biết thì tốt nhất là dùng EAV. Vấn đề là những người mới rất chuộng việc áp dụng phương pháp này trong CSDL SQL và hậu quả thường là một mớ hỗn loạn. Thực tế, nhiều người cho rằng thật may mắn khi họ không biết bản chất của dữ liệu.
Thế thì những lợi ích nào được đưa ra đối với EAV? Vâng, chẳng có lợi ích nào cả. Vì các bảng EAV chứa bất cứ kiểu dữ liệu nào nên chúng ta phải cố định dữ liệu ở một vùng giới hạn trong bảng với những cột thích hợp nhằm sử dụng chúng hiệu quả. Trong nhiều trường hợp, có những phần mềm client-side hoặc middleware sẽ ngầm thực hiện việc này, do đó sẽ khiến cho người dùng nhầm tưởng rằng mình đang làm việc với dữ liệu được thiết kế tốt.
Mô hình EAV có một hệ thống các vấn đề.
- Đầu tiên, lượng dữ liệu lớn không thể kiểm soát chính nó được.
- Thứ hai, không có cách khả thi nào để xác định những ràng buộc cần thiết – bất cứ ràng buộc kiểm tra tiềm năng nào cũng sẽ phải bao gồm việc tạo ra mã cứng trên diện rộng cho các tên thuộc tính thích hợp. Chính vì một cột đơn lẻ chứa tất cả các giá trị có thể nên kiểu dữ liệu thường là VARCHAR(n).
- Thứ ba, đừng bao giờ nghĩ về chuyện có những khóa ngoại hữu dụng.
- Thứ tư, truy vấn (query) luôn có những phức tạp và rắc rối. Một số người cho rằng sẽ có lợi khi có thể chèn nhiều dữ liệu vào cùng một bảng khi cần thiết – họ gọi đó là tính “có khả năng thay đổi”. Trong thực tế, vì EAV trộn lẫn dữ liệu và lý lịch dữ liệu nên càng khó hơn để điều khiển dữ liệu ngay cả trong những yêu cầu đơn giản. Hãy xem xét một truy vấn đơn giản để gọi ra những nhân viên sinh sau năm 1950. Với mô hình truyền thống, ta có:

Trong một mô hình EAV, đây là một cách để viết một truy vấn có thể so sánh được:

List 1
Với những ai có kinh nghiệm với transact-SQL thì cứ thêm vài cột mới vào kèm theo các kiểu dữ liệu khác và thử vài truy vấn để kiểm tra kết quả.
Giải pháp cho cơn ác mộng EAV thì lại khá đơn giản: Phân tích và nghiên cứu xem nhu cầu của người dùng là gì và xác định yêu cầu dữ liệu một cách cởi mở. Một CSDL quan hệ sẽ duy trì tính toàn vẹn và nhất quán của dữ liệu Gần như là bất khả thi để tạo ra một trường hợp (case) thiết kế một CSDL như thế mà không có yêu cầu đã được xác định cẩn thận. Chấm hết!
(4) Các xâm lấn ứng dụng trong thiết kế CSDL
Có vài cách thức mà một ứng dụng có thể xâm phạm tới trường quản lý dữ liệu. Tôi sẽ giải thích ngắn gọn hai cách thức và đề xuất vài hướng dẫn về cách ngăn chặn điều ày.
Thực thi tính toàn vẹn thông qua các ứng dụng
Những người đề xướng ứng dụng dựa trên tính toàn vẹn thường cho rằng những ràng buộc ảnh hưởng tiêu cực tới việc truy cập dữ liệu. Họ cũng cho rằng việc áp dụng các quy tắc một cách chọn lọc dựa trên nhu cầu của ứng dụng là con đường tốt nhất để thực hiện.
Hãy cùng nhau xem xét chi tiết vấn đề này. Có bất cứ tính toán, so sánh và phân tích thống kê nào tốt để giải quyết sự khác nhau khi thực thi giữa những quy tắc giống nhau được yêu cầu bởi hệ quản trị CSDL (DBMS) và ứng dụng hay không? Một ứng dụng có thể thi hành các quy tắc có liên quan tới dữ liệu hiệu quả tới đâu? Nếu các quy tắc giống nhau đều được yêu cầu bởi nhiều ứng dụng thì có thể tránh việc sao chép code hay không? Nếu có một cơ chế thực thi tính toàn vẹn trong hệ quản trị CSDL rồi thì tại sao lại phải nghĩ ra những thứ đã có sẵn để làm gì nữa?
Giải pháp rất đơn giản.
Không cần dựa vào điều gì khác để hoàn thành và sửa chữa ngoại trừ chính CSDL. Khi nói không cần dựa vào thứ gì khác, ý của tôi là không cần tới người dùng hay các ứng dụng bên ngoài CSDL. Mặc dù có thể đúng là những sản phẩm DBMS hiện tại có thể không thành công trong việc thực thi tất cả các ràng buộc khả thi, nhưng nó cũng không đủ nhạy để cho ứng dụng hay người dùng thực hiện nhiệm vụ đó.
Có lẽ bạn sẽ thắc mắc tại sao lại khá tệ khi dựa vào ứng dụng để thực thi tính toàn vẹn dữ liệu phải không? Phải, nếu chỉ có một ứng dụng trên một CSDL thì đó không hẳn là vấn đề. Tuy nhiên thường thì các CSDL hoạt động như kho chứa dữ liệu trung tâm và phục vụ nhiều ứng dụng. Vì vậy, các quy tắc phải được thực thi trên tất cả các ứng dụng. Những quy tắc này cũng có thể thay đổi.
Theo như hướng dẫn chung, các CSDL thường đóng nhiều vai trò hơn là chỉ là những kho chứa dữ liệu; chúng là nguồn của những quy tắc gắn liền với dữ liệu. Hãy khai báo những ràng buộc nhất quán trong CSDL khi có thể với từng quy tắc cần được thực thi. Sử dụng các trigger và thủ tục (procedure) được lưu trữ sẵn chỉ khi nào việc thực thi tính toàn vẹn trong khai báo thông qua khóa và những ràng buộc không khả thi. Chỉ có những quy tắc cụ thể cho ứng dụng mới cần phải được thực hiện thông qua ứng dụng.
Application nhỏ có ảnh hưởng lớn
Đang có một xu hướng nổi lên trong giới lập trình viên khi coi CSDL như là một phần của “application domain”. Thường thì các bảng được thêm vào khi cần bởi các lập trình viên ứng dụng và sau đó các cột được được thêm vào khi đã hoàn tất.
Điều này rất thuận lợi bởi vì nó tránh được những phần phiền phức của quá trình thiết kế như thu thập yêu cầu, v.v. Kinh nghiệm cho ta thấy trong hầu hết các doanh nghiệp, các ứng dụng được dùng rồi lại bị loại bỏ, chỉ có các CSDL mới thường được duy trì lâu dài mà thôi. Vì thế sẽ hợp lí hơn khi ta cố gắng phát triển một thiết kế tốt dựa trên các quy tắc cụ thể với từng bộ phận theo lĩnh vực kinh doanh tùy vào ngữ cảnh. (Teorey, 1994).
(5) Sử dụng nhầm lẫn các giá trị dữ liệu (data value) với ý nghĩa phần tử dữ liệu (data element)
Trước hết chúng ta hãy làm rõ một số thuật ngữ: Một “data value” nói đến giá trị của một thuộc tính của phần tử, còn một “data element” ám chỉ từng đơn vị của lý lịch dữ liệu chẳng hạn như tên cột hoặc tên bảng. Bằng việc nói rằng sử dụng sai giá trị dữ liệu với nghĩa phần tử dữ liệu, tôi đang muốn nói đến hành động phân chia các giá trị thuộc tính của một phần tử nào đó và thể hiện nó trong các cột và bảng. Joe Celko gọi nó chính xác với cái tên là “phân chia thuộc tính”
Hãy xem xét một bảng dữ liệu thể hiện số liệu doanh thu của vài nhân viên bán hàng cho một công ty. Giả sử rằng thiết kế bên dưới được chấp nhận nhằm đơn giản hóa việc gọi dữ liệu để hiện thị:
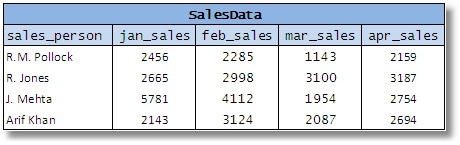
Hình 9
Bạn sẽ thấy ở đây một thuộc tính đơn lẻ trong mô hình kinh doanh, “lượng doanh số” (sales amount) được trình bày dưới dạng một chuỗi các cột. Điều này khiến mọi chuyện khó khăn hơn cho hầu hết những người dùng sơ đồ như thế.
Thế thì điều gì khiến một thiết kế làm cho mọi người ngán ngẩm đến thế?
- Việc sao chép những ràng buộc gây nên rắc rối này. Bất cứ ràng buộc nào áp dụng lên doanh số hàng tháng sẽ phải được định nghĩa cho mỗi cột riêng biệt.
- Nếu không thay thế bảng thì bạn không thể thêm doanh số cho tháng mới. Một giải pháp thay thế dở tệ là dùng các cột ghi lại toàn bộ doanh số có thể có trong từng tháng và dùng giá trị NULL cho các tháng không có doanh số.
- Và cuối cùng, có chút khó khăn trong việc thể hiện những truy vấn đơn giản tương đối, chẳng hạn như so sánh doanh số giữa các nhân viên bán hàng hoặc tìm ra doanh số cao nhất hàng tháng.
Nói thêm, nhiều người coi vấn đề này là một sự vi phạm dạng chuẩn 1. Đây quả thật là một hiểu nhầm vì không có cột nào chứa nhiều giá trị ở đây cả. Để có thêm giải thích chi tiết, vui lòng tìm đọc bài viết ngắn sau “Các sự thật và Hiểu nhầm về Dạng chuẩn 1 (1NF)”.
Phương pháp lý tưởng để thiết kế bảng này sẽ trông như sau:
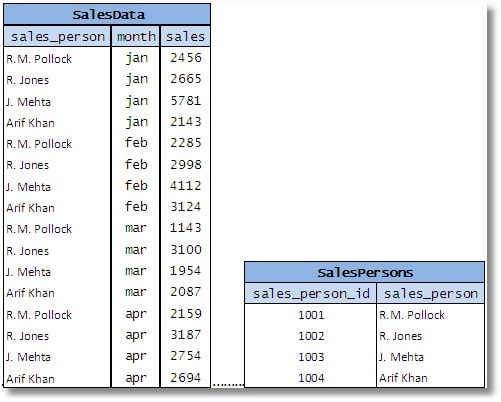
Hình 10
Tất nhiên là bạn có thể dùng một bảng riêng biệt cho nhân viên bán hàng và sau đó tham chiếu nó bằng một khóa ngoại, tốt nhất là một khóa thay thế đơn giản chẳng hạn như sales_person_id như bên trên.
Nếu bạn đang mắc kẹt với một bảng được thiết kế như hình 9, bạn có thể tạo ra một resultset từ code theo những cách khác nhau:
1. Dùng truy vấn UNION


Thông thường, bạn sẽ phải kiểm tra dựa theo các bảng bên dưới, và cân nhắc những thứ như là kích thước của dữ liệu và các index có sẵn nhằm chắc chắn rằng phương pháp nào hiệu quả nhất.
Biến thể khác của phương pháp này là phân chia các thuộc tính giữa các bảng, tức là dùng các giá trị dữ liệu như một phần của tên bảng đó. Cách này thường được áp dụng với nhiều bảng có cấu trúc tương tự nhau. Hãy xem xét tập hợp các bảng sau:
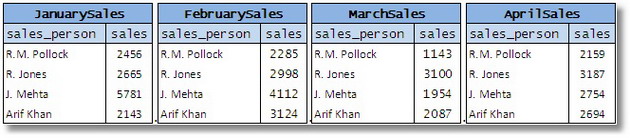
Hình 11
Ở đây, từng giá trị riêng biệt của thuộc tính “month” được gán cho từng bảng. Thiết kế này cũng có những khuyết điểm tương tự chẳng hạn như việc sao chép các ràng buộc và khó khăn trong việc biểu diễn các truy vấn đơn giản. Để trở nên hữu ích, các bảng sẽ được kết hợp bằng UNION để tạo nên một bảng đơn lẻ với một cột thêm vào biểu diễn tháng. Cách này dễ hơn là bắt đầu với một bảng cơ sở (base table) đơn lẻ.
Chúng ta cần cẩn thận tránh nhần lẫn giữa việc phân chia các thuộc tính với nguyên lý thiết kế logic có phân chia bảng, tức là một quá trình sắp xếp lại dữ liệu được hoàn thành ở mức độ vật lý, từ đó tạo nên một tập con dữ liệu nhỏ hơn từ một bảng hoặc index lớn nhằm quản lý và truy cập chúng hiệu quả.
Chú ý thêm là vấn đề này đã được thảo luận khá kĩ bởi những nhà lý luận quan hệ một cách chi tiết đối với những hạn chế mà nó tác động lên những cập nhật view. Một vài người định nghĩa nó là một dạng vi phạm trực tiếp tới nguyên lý thông tin (một nguyên lý quan hệ yêu cầu việc thể hiện của tất cả các dữ liệu trong một CSDL phải riêng biệt như các giá trị trong một bảng) và đề xuất rằng không có hai bảng nào trong một CSDL chứa các ý nghĩa chồng nhau (overlapped meanings). Vốn dĩ ban đầu được định nghĩa là “Nguyên lý thiết kế mới”, việc đề xuất cho từng bảng có một nghĩa hoặc tính chất duy nhất ngày nay được biết với cái tên “Nguyên lý của thiết kế trực giao” trong các tài liệu quan hệ.
Kết luận
Luôn luôn xứng đáng khi đầu tư thời gian nghiên cứu trong việc thực hiện mô hình một sơ đồ CSDL thật tốt. Không những nó cung cấp cho bạn một sơ đồ có thể duy trì và có thể truy cập một cách dễ dàng, mà nó còn giúp bạn vá những lỗ hổng theo định kỳ. Thường thì các nhà thiết kế CSDL tìm kiếm đuờng tắt nhằm tiết kiệm thời gian và công sức. Bất chấp vẻ hào nhoáng bên ngoài, thì hầu hết các giải pháp chắp vá đều không thể tồn tại lâu và kết thúc bằng việc tiêu tốn thêm thời gian, công sức và tiền bạc. Một thiết kế trơn tru đủ chuẩn có thể yêu cầu không gì nhiều hơn là tuân theo vài quy tắc đơn giản, đi cùng quyết tâm làm theo những quy tắc đó nhằm tạo nên những chuyên gia CSDL chân chính.
Theo Anith Sen
Nguồn bài viết : https://www.red-gate.com