Xin chào các bạn. Với những bạn đang tìm hiểu và làm việc về Deep Leanring thì framework Pytorch không còn xa lạ nữa. PyTorch là một Neural Network Dynamic Framework. Nói đến tính động Dynamic thì cũng sẽ có các Framwork được gọi là Static Neural Network Framework như Tensorflow, Keras, Theano … và điểm khác biệt cơ bản giữa chúng nằm ở hai điểm sau:
- Trong các Static Framework thì đồ thị tính toán (computation graph)) được định nghĩa trước, sau đó được compile và tiến hành ném các mẫu dữ liệu qua đồ thị để tính toán. Bạn có thể tưởng tượng điều này giống như một người làm đường ống nước. Trước tiên anh ta sẽ phải xây dựng đường ống và các van liên kết các đường ống (tương tự như xây dựng kiến trúc một mạng nơ ron) và sau đó anh ta mới đổ nước vào đường ống (tương tự như việc fit dữ liệu vào mô hình)
- Còn đối với một Dynamic Framework thì sao. Nó sẽ không thực hiện việc khởi tạo graph trước mà sẽ tiến hành chạy ngay khi bạn fit dữ liệu vào trong mô hình. Sẽ không có các thao tác biên dịch khiến cho việc tính toán được thực hiện nhanh chóng.
Một trong những ưu điểm dễ thấy nhất của Pytorch đó là việc nó rất gần với ngôn ngữ Python mà không phải đưa vào các khái niệm về Graph, Session phức tạp. Điều này khiến cho các bạn chuyển đổi từ các package khác (nhất là bạn nào quen sử dụng Numpy) sang Pytorch một cách dễ dàng hơn. Do không còn dựa trên Graph nên việc debug có thể thực hiện trực tiếp trong mô hình mà không cần phải khởi tạo một Session giống như trong TF 1.X. Và đó cũng chính là hướng tiếp cận mà TF 2.X đang hướng tới. Thực sự giúp cho các developer thuận tiện hơn trong quá trình học và sử dụng Framework. Ở bài này chúng ta sẽ bắt đầu với các ví dụ đơn giản trong việc sử dụng Pytorch nhé. OK chúng ta bắt đầu thôi

Khái niệm về Tensors
Xử lý MLP với Numpy
Tensor là một khái niệm cơ bản trong Deep Learning. Nó được sủ dụng để thể hiện các ma trận, mảng nhiều chiều (thường là lớn hơn 2 chiều). PyTorch là một framework về Deep Learning thì đường nhiên không thể không based trên Tensor rồi. Tuy nhiên trước khi tìm hiểu khái niệm này được xử lý thế nào trong Pytorch thì chungs ta hãy cùng nhau thực hiện một ví dụ đơn giản với một package quen thuộc trong xử lý dữ liệu đó chính là Numpy để thấy được các cách tính toán với Tensor.
![]()
Trong thư viện Numpy, chúng ta có thể thực hiện nhiều thao tác với mảng nhiều chiều. Có thể viết trực tiếp các hàm activation function cũng như tính toán các đạo hàm. Như vậy chúng ta hoàn toán của thể thực hiện việc training các mạng đơn giản như MLP bằng Numpy Dưới đây chúng ta sẽ xây dựng một MLP đơn giản với 2 hidden layer và thực hiện các thao tác forward, tính toán hàm loss, backward bằng Numpy nhé. Các bạn có thể hình dung kiến trúc của MLP trong hình sau:

Giờ thì code thôi:
- Import thư viện:
1 2 | <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np |
- Khởi tạo dữ liệu random
1 2 3 4 5 6 | n<span class="token punctuation">,</span> input_dim<span class="token punctuation">,</span> hidden_dim<span class="token punctuation">,</span> output_dim <span class="token operator">=</span> <span class="token number">64</span><span class="token punctuation">,</span> <span class="token number">784</span><span class="token punctuation">,</span> <span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">10</span> <span class="token comment"># Create random input and output data</span> x <span class="token operator">=</span> np<span class="token punctuation">.</span>random<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>n<span class="token punctuation">,</span> input_dim<span class="token punctuation">)</span> y <span class="token operator">=</span> np<span class="token punctuation">.</span>random<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>n<span class="token punctuation">,</span> output_dim<span class="token punctuation">)</span> |
- Khởi tạo weight random
1 2 3 4 | # Randomly initialize weights w1 = np.random.randn(input_dim, hidden_dim) w2 = np.random.randn(hidden_dim, output_dim) |
- Khởi tạo learning rate
1 2 | learning_rate <span class="token operator">=</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">6</span> |
- Khởi tạo quá trình forward
1 2 3 4 5 6 7 8 9 10 11 | <span class="token comment"># Loop for 100 epochs</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">500</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># Forward pass: compute predicted y</span> h <span class="token operator">=</span> x<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>w1<span class="token punctuation">)</span> h_relu <span class="token operator">=</span> np<span class="token punctuation">.</span>maximum<span class="token punctuation">(</span>h<span class="token punctuation">,</span> <span class="token number">0</span><span class="token punctuation">)</span> y_pred <span class="token operator">=</span> h_relu<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>w2<span class="token punctuation">)</span> <span class="token comment"># Compute and print loss</span> loss <span class="token operator">=</span> np<span class="token punctuation">.</span>square<span class="token punctuation">(</span>y_pred <span class="token operator">-</span> y<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span>i<span class="token punctuation">,</span> loss<span class="token punctuation">)</span> |
- Tiến hành quá trình backward
Vãn tiếp tục trong vòng for trên chúng ta tiến hành quá trình tính toán đạo hàm cho từng layer và thực hiện gradient descent để cập nhật trong số.
1 2 3 4 5 6 7 8 9 10 11 12 | <span class="token comment"># Backprop to compute gradients of w1 and w2 with respect to loss</span> grad_y_pred <span class="token operator">=</span> <span class="token number">2.0</span> <span class="token operator">*</span> <span class="token punctuation">(</span>y_pred <span class="token operator">-</span> y<span class="token punctuation">)</span> grad_w2 <span class="token operator">=</span> h_relu<span class="token punctuation">.</span>T<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>grad_y_pred<span class="token punctuation">)</span> grad_h_relu <span class="token operator">=</span> grad_y_pred<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>w2<span class="token punctuation">.</span>T<span class="token punctuation">)</span> grad_h <span class="token operator">=</span> grad_h_relu<span class="token punctuation">.</span>copy<span class="token punctuation">(</span><span class="token punctuation">)</span> grad_h<span class="token punctuation">[</span>h <span class="token operator"><</span> <span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token number">0</span> grad_w1 <span class="token operator">=</span> x<span class="token punctuation">.</span>T<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>grad_h<span class="token punctuation">)</span> <span class="token comment"># Update weights</span> w1 <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> grad_w1 w2 <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> grad_w2 |
- Kết quả chạy
1 2 3 4 5 6 7 | Epoch <span class="token number">334</span> loss <span class="token operator">=</span> <span class="token number">0.007659277493960106</span> Epoch <span class="token number">335</span> loss <span class="token operator">=</span> <span class="token number">0.007318882365965462</span> Epoch <span class="token number">336</span> loss <span class="token operator">=</span> <span class="token number">0.006993647426368092</span> Epoch <span class="token number">337</span> loss <span class="token operator">=</span> <span class="token number">0.006682912079723925</span> Epoch <span class="token number">338</span> loss <span class="token operator">=</span> <span class="token number">0.006386000771141572</span> Epoch <span class="token number">339</span> loss <span class="token operator">=</span> <span class="token number">0.006102330948624104</span> |
Việc sử dụng numpy để xây dựng một mạng nơ ron có một nhược điểm lớn đó là không thể tận dụng được GPU để tính toán cho các phép toán trên ma trận khiến cho quá trình training trở nên lâu hơn rất nhiều. Hơn nữa có một module rất quan trọng trong PyTorch bên cạnh việc tính toán ma trận đó là việc Automatic differentiation giúp cho quá trình tính toán đạo hàm trở nên dễ dàng hơn. Giờ chúng ta cùng chuyển quá PyTorch xem sao nhé
Xây dựng MLP với Pytorch
Điểm khác biệt của PyTorch Tensor
Tensor trong Pytorch cũng có dạng y hệt như n-dimentional array của Numpy nhưng được add thêm vào đó một số tính năng hữu ích trong quá trình training với nhiều function được operate trên nó. Việc casting giữa các device khác nhau như CPU và GPU khiến cho việc tính toán trên Tensor được dễ dàng hơn. Ngoài ra, tensor trong Pytorch còn được sử dụng trong việc track đồ thị tính toán và gradients cùng nhiều công cụ hữu ích khác

Giờ chúng ta sẽ thử define lại mạng trên một cách thủ công nhưng không dùng Numpy Array mà sử dụng Torch Tensor nhé.
- Import torch
1 2 | <span class="token keyword">import</span> torch |
- Define data tensors
1 2 3 4 5 6 | n<span class="token punctuation">,</span> input_dim<span class="token punctuation">,</span> hidden_dim<span class="token punctuation">,</span> output_dim <span class="token operator">=</span> <span class="token number">64</span><span class="token punctuation">,</span> <span class="token number">784</span><span class="token punctuation">,</span> <span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">10</span> <span class="token comment"># Create random input and output data</span> x <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>n<span class="token punctuation">,</span> input_dim<span class="token punctuation">)</span> y <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>n<span class="token punctuation">,</span> output_dim<span class="token punctuation">)</span> |
- Define weight tensor
1 2 3 4 | <span class="token comment"># Randomly initialize weights</span> w1 <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>input_dim<span class="token punctuation">,</span> hidden_dim<span class="token punctuation">)</span> w2 <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>hidden_dim<span class="token punctuation">,</span> output_dim<span class="token punctuation">)</span> |
- Training process
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | learning_rate <span class="token operator">=</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">6</span> <span class="token keyword">for</span> t <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">500</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># Forward pass: compute predicted y</span> h <span class="token operator">=</span> x<span class="token punctuation">.</span>mm<span class="token punctuation">(</span>w1<span class="token punctuation">)</span> h_relu <span class="token operator">=</span> h<span class="token punctuation">.</span>clamp<span class="token punctuation">(</span><span class="token builtin">min</span><span class="token operator">=</span><span class="token number">0</span><span class="token punctuation">)</span> y_pred <span class="token operator">=</span> h_relu<span class="token punctuation">.</span>mm<span class="token punctuation">(</span>w2<span class="token punctuation">)</span> <span class="token comment"># Compute and print loss</span> loss <span class="token operator">=</span> <span class="token punctuation">(</span>y_pred <span class="token operator">-</span> y<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">pow</span><span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">if</span> t <span class="token operator">%</span> <span class="token number">100</span> <span class="token operator">==</span> <span class="token number">99</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>t<span class="token punctuation">,</span> loss<span class="token punctuation">)</span> <span class="token comment"># Backprop to compute gradients of w1 and w2 with respect to loss</span> grad_y_pred <span class="token operator">=</span> <span class="token number">2.0</span> <span class="token operator">*</span> <span class="token punctuation">(</span>y_pred <span class="token operator">-</span> y<span class="token punctuation">)</span> grad_w2 <span class="token operator">=</span> h_relu<span class="token punctuation">.</span>t<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>mm<span class="token punctuation">(</span>grad_y_pred<span class="token punctuation">)</span> grad_h_relu <span class="token operator">=</span> grad_y_pred<span class="token punctuation">.</span>mm<span class="token punctuation">(</span>w2<span class="token punctuation">.</span>t<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> grad_h <span class="token operator">=</span> grad_h_relu<span class="token punctuation">.</span>clone<span class="token punctuation">(</span><span class="token punctuation">)</span> grad_h<span class="token punctuation">[</span>h <span class="token operator"><</span> <span class="token number">0</span><span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token number">0</span> grad_w1 <span class="token operator">=</span> x<span class="token punctuation">.</span>t<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>mm<span class="token punctuation">(</span>grad_h<span class="token punctuation">)</span> <span class="token comment"># Update weights using gradient descent</span> w1 <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> grad_w1 w2 <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> grad_w2 |
- Kết quả
1 2 3 4 5 | <span class="token number">99</span> <span class="token number">1442.7469362142501</span> <span class="token number">199</span> <span class="token number">13.328768673383937</span> <span class="token number">299</span> <span class="token number">0.26145767173260204</span> <span class="token number">399</span> <span class="token number">0.008008871590855948</span> |
Chúng ta thấy rằng việc tính toán cũng không khác gì so với việc sử dụng Numpy. Đây cũng chính là ly do mình đã nói ngay từ đầu bài viết là PyTorch sẽ là một Framwork rất phù hợp cho các bạn đã quen sử dụng với Numpy trước đó rồi. Tiếp theo chúng ta sẽ đi tìm heiuer một module rất quan trọng trong PyTorch đó chính là AutoGrad
Khái niệm về AutoGrad
NẾu như các bạn mới chỉ độc hai ví dụ phía trên thì chắc hẳn các bạn sẽ thấy hơi bị ngợp với những tính toán. Việc này vừa nhàm chán vừa dễ bị sai nữa. Các bạn thấy không, chỉ với một mạng neural 2 lớp ẩn đơn giản như trên thôi mà việc tính toán qsu trình forward cũng như backward đã mất quá ư nhiều code của các bạn rồi chứ nói gì đến các mạng siêu to khổng lồ cỡ vài trăm triệu thậm chí vài tỷ tham số thì tính toán sao đây. Đây chính là lúc mà AutoGrad phát hiuy hiệu quả của nó. Như các bạn đã biết các thao tác tính toán trong qus trình backward của một mạng nơn ron đều dựa trên một quy tắc đó là Chain Rule hay đạo hàm của hàm hợp. Và module AutoGrad được sinh ra để giải quyết vấn đề tính toán đạo hàm phức tạp đó
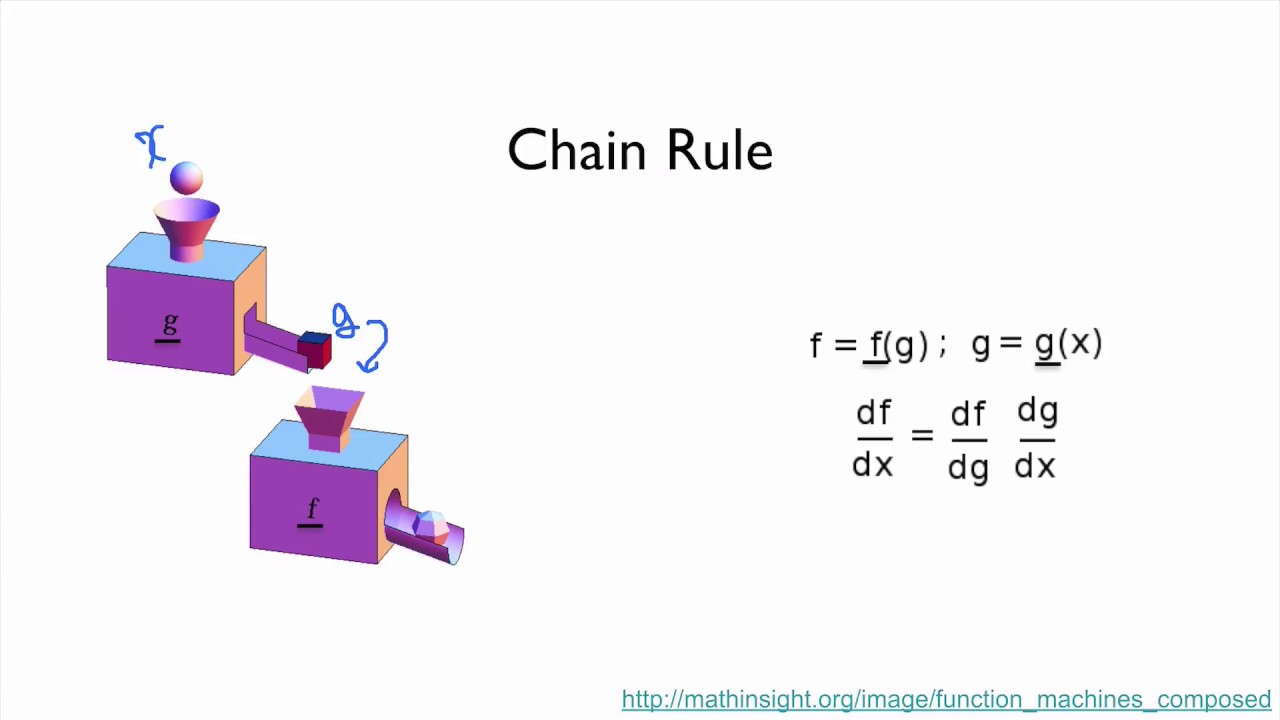
PyTorch sử dụng automatic differentiation trong module Autograd. Trong quá trình forward sẽ định nghĩa đồ thị tính toán với các node là các Tensors và các cạnh sẽ là các function tính toán giá trị của Tensor đầu ra khi đưa vào Input Tensor. Quá trình Backpropagating cũng được tính toán thông qua biểu đồ này cho phép bạn dễ dàng tính toán giá trị của đạo hàm. Bây giờ chúng ta sẽ sử dụng autograd để xây dựng mạng 2 lớp nói trên xem có dễ dàng hơn không nhé.
- Require grad cho weights tensor
1 2 3 4 | <span class="token comment"># Randomly initialize weights</span> w1 <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>input_dim<span class="token punctuation">,</span> hidden_dim<span class="token punctuation">,</span> requires_grad<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">)</span> w2 <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>hidden_dim<span class="token punctuation">,</span> output_dim<span class="token punctuation">,</span> requires_grad<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">)</span> |
- Training sử dụng autograd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | <span class="token keyword">for</span> t <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">500</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># Forward </span> y_pred <span class="token operator">=</span> x<span class="token punctuation">.</span>mm<span class="token punctuation">(</span>w1<span class="token punctuation">)</span><span class="token punctuation">.</span>clamp<span class="token punctuation">(</span><span class="token builtin">min</span><span class="token operator">=</span><span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">.</span>mm<span class="token punctuation">(</span>w2<span class="token punctuation">)</span> <span class="token comment"># Compute loss </span> loss <span class="token operator">=</span> <span class="token punctuation">(</span>y_pred <span class="token operator">-</span> y<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">pow</span><span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">if</span> t <span class="token operator">%</span> <span class="token number">100</span> <span class="token operator">==</span> <span class="token number">99</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>t<span class="token punctuation">,</span> loss<span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># backward </span> loss<span class="token punctuation">.</span>backward<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token comment"># Update gradident </span> <span class="token keyword">with</span> torch<span class="token punctuation">.</span>no_grad<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> w1 <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> w1<span class="token punctuation">.</span>grad w2 <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> w2<span class="token punctuation">.</span>grad <span class="token comment"># Manually zero the gradients after updating weights</span> w1<span class="token punctuation">.</span>grad<span class="token punctuation">.</span>zero_<span class="token punctuation">(</span><span class="token punctuation">)</span> w2<span class="token punctuation">.</span>grad<span class="token punctuation">.</span>zero_<span class="token punctuation">(</span><span class="token punctuation">)</span> |
- Kết quả
1 2 3 4 5 6 | <span class="token number">99</span> <span class="token number">1283.6190185546875</span> <span class="token number">199</span> <span class="token number">14.63010311126709</span> <span class="token number">299</span> <span class="token number">0.3335697054862976</span> <span class="token number">399</span> <span class="token number">0.010790261439979076</span> <span class="token number">499</span> <span class="token number">0.0006669819122180343</span> |
Sử dụng Neural Network Module
Trong PyTorch có một module mà bạn sẽ phải sử dụng rất nhiều đó chính là Neural Network Module. Nếu hiểu đơn giản việc xây dựng một mạng nơ ron là sắp xếp các layers, định nghĩa các learnable parameter và sử dụng đạo hàm để tối ưu các tham số đó theo hàm loss mà ta muốn thì việc sử dụng nn module sẽ giúp cho ta thực hiện các công việc đó ở mức high-level tức ở mức tổng quát nhất, dễ dàng nhất. Nó tương tự với các package như Keras, Tensorflow Slim với Tensorflow. Trong nn pcakage định nghĩa nhiều modules nhỏ gần như tương đương với các loại layers trong một mạng nơ ron. Một modules sẽ nhận đầu vào và đầu ra đều là các tensor. Module nn cũng định nghĩa các loss function phổ biến thường được sử dụng trong khi xây dựng một mạng nơ ron.
Sau đây là ví dụ việc sử dụng nn module để xây dựng một mạng nơ ron 2 lớp ẩn:
1 2 3 4 5 6 7 8 9 10 11 | N<span class="token punctuation">,</span> D_in<span class="token punctuation">,</span> H<span class="token punctuation">,</span> D_out <span class="token operator">=</span> <span class="token number">64</span><span class="token punctuation">,</span> <span class="token number">1000</span><span class="token punctuation">,</span> <span class="token number">100</span><span class="token punctuation">,</span> <span class="token number">10</span> x <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>N<span class="token punctuation">,</span> D_in<span class="token punctuation">)</span> y <span class="token operator">=</span> torch<span class="token punctuation">.</span>randn<span class="token punctuation">(</span>N<span class="token punctuation">,</span> D_out<span class="token punctuation">)</span> model <span class="token operator">=</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>Sequential<span class="token punctuation">(</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>D_in<span class="token punctuation">,</span> H<span class="token punctuation">)</span><span class="token punctuation">,</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>ReLU<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>H<span class="token punctuation">,</span> D_out<span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token punctuation">)</span> |
chúng ta có thể thấy Sequential module khá giống với Keras. Ý tưởng chung của chúng là như vậy tuy nhiên sử dụng PyTorch còn còn thế giúp chúng ta tùy biến nhiều hơn thế nữa bằng việc kế thừa lại torch.Module. Chúng ta tiến hành training thử mạng trên
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | loss_fn <span class="token operator">=</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>MSELoss<span class="token punctuation">(</span>reduction<span class="token operator">=</span><span class="token string">'sum'</span><span class="token punctuation">)</span> learning_rate <span class="token operator">=</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">4</span> <span class="token keyword">for</span> t <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">500</span><span class="token punctuation">)</span><span class="token punctuation">:</span> y_pred <span class="token operator">=</span> model<span class="token punctuation">(</span>x<span class="token punctuation">)</span> loss <span class="token operator">=</span> loss_fn<span class="token punctuation">(</span>y_pred<span class="token punctuation">,</span> y<span class="token punctuation">)</span> <span class="token keyword">if</span> t <span class="token operator">%</span> <span class="token number">100</span> <span class="token operator">==</span> <span class="token number">99</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>t<span class="token punctuation">,</span> loss<span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token comment"># Zero the gradients before running the backward pass.</span> model<span class="token punctuation">.</span>zero_grad<span class="token punctuation">(</span><span class="token punctuation">)</span> loss<span class="token punctuation">.</span>backward<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">with</span> torch<span class="token punctuation">.</span>no_grad<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">for</span> param <span class="token keyword">in</span> model<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> param <span class="token operator">-=</span> learning_rate <span class="token operator">*</span> param<span class="token punctuation">.</span>grad |
Chúng ta thấy việc cập nhật tham số vẫn được thực hiện cách thủ công và điều này thực sự là không cần thiết. PyTorch hỗ trợ sắn cho chúng ta một module để thực hiện điều này đó chính là module optim chúng ta sẽ tìm hiểu nó trong phần tiếp theo
Sử dụng module optim
Như đã trình bày ở phía trên thì việc tối ưu các trọng số trong khi traininig một mạng nơ ron thì không cần phải làm thủ công như thế. Thực tế là có rất nhiều các loại optimizers khác có nhiều cách cập nhật trong số khác chứ không chỉ đơn giản như cách cập nhật phía trên (của SGD). Có thể kế đến như AdaGrad, RMSProp, Adam ….
Module optim được sinh ra để giải quyết vấn đề đó. Nó được implement sẵn nhiều optimizers thường được sử dụng khi training một mạng nơ ron. Chúng ta có thể training lại mạng nơ ron định nghĩa phía trên bằng module này như sau
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | optimizer <span class="token operator">=</span> torch<span class="token punctuation">.</span>optim<span class="token punctuation">.</span>Adam<span class="token punctuation">(</span>model<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> lr<span class="token operator">=</span>learning_rate<span class="token punctuation">)</span> <span class="token keyword">for</span> t <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span><span class="token number">500</span><span class="token punctuation">)</span><span class="token punctuation">:</span> y_pred <span class="token operator">=</span> model<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># Compute and print loss.</span> loss <span class="token operator">=</span> loss_fn<span class="token punctuation">(</span>y_pred<span class="token punctuation">,</span> y<span class="token punctuation">)</span> <span class="token keyword">if</span> t <span class="token operator">%</span> <span class="token number">100</span> <span class="token operator">==</span> <span class="token number">99</span><span class="token punctuation">:</span> <span class="token keyword">print</span><span class="token punctuation">(</span>t<span class="token punctuation">,</span> loss<span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> optimizer<span class="token punctuation">.</span>zero_grad<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token comment"># Backward pass: compute gradient of the loss with respect to model</span> <span class="token comment"># parameters</span> loss<span class="token punctuation">.</span>backward<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token comment"># Calling the step function on an Optimizer makes an update to its</span> <span class="token comment"># parameters</span> optimizer<span class="token punctuation">.</span>step<span class="token punctuation">(</span><span class="token punctuation">)</span> |
Câu truyện trở nên đơn giản hơn rât snhieuef với chỉ một câu lệnh optimizer.step().
Viết custom module với nn.Module
Như chúng ta đã thấy ở phía trên thì việc định nghĩa một model đang khá đơn giản. Tuy nhiên khi thiết kế một mạng nơ ron với nhiều layers, nhiều kết nối, nhiều thành phần custom thì cần sử dụng cách khác đó chính là nn.Module. Chúng ta tham khảo mạng 2 lớp phía trên được viết lại như sau
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <span class="token keyword">class</span> <span class="token class-name">TwoLayerNet</span><span class="token punctuation">(</span>torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>Module<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> D_in<span class="token punctuation">,</span> H<span class="token punctuation">,</span> D_out<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token triple-quoted-string string">""" In the constructor we instantiate two nn.Linear modules and assign them as member variables. """</span> <span class="token builtin">super</span><span class="token punctuation">(</span>TwoLayerNet<span class="token punctuation">,</span> self<span class="token punctuation">)</span><span class="token punctuation">.</span>__init__<span class="token punctuation">(</span><span class="token punctuation">)</span> self<span class="token punctuation">.</span>linear1 <span class="token operator">=</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>D_in<span class="token punctuation">,</span> H<span class="token punctuation">)</span> self<span class="token punctuation">.</span>linear2 <span class="token operator">=</span> torch<span class="token punctuation">.</span>nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>H<span class="token punctuation">,</span> D_out<span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token triple-quoted-string string">""" In the forward function we accept a Tensor of input data and we must return a Tensor of output data. We can use Modules defined in the constructor as well as arbitrary operators on Tensors. """</span> h_relu <span class="token operator">=</span> self<span class="token punctuation">.</span>linear1<span class="token punctuation">(</span>x<span class="token punctuation">)</span><span class="token punctuation">.</span>clamp<span class="token punctuation">(</span><span class="token builtin">min</span><span class="token operator">=</span><span class="token number">0</span><span class="token punctuation">)</span> y_pred <span class="token operator">=</span> self<span class="token punctuation">.</span>linear2<span class="token punctuation">(</span>h_relu<span class="token punctuation">)</span> <span class="token keyword">return</span> y_pred |
Như chúng ta đã thấy, việc định nghĩa theo kiểu kế thừa lại nn.Module sẽ giúp chúng ta dễ dàng custom kiến trúc của mạng hơn bằng việc xử lý các Tensor trong hàm forward. Lúc này việc khai báo model tương đương với việc khởi tạo instance của class trên
1 2 | model <span class="token operator">=</span> TwoLayerNet<span class="token punctuation">(</span>D_in<span class="token punctuation">,</span> H<span class="token punctuation">,</span> D_out<span class="token punctuation">)</span> |
Tổng kết
Trên đây là các thành phần cơ bản để implement một mạng nơ ron với PyTorch. Các bạn nên thực hành nhiều hơn với các tập dữ liệu đươn giản để hiểu kĩ hơn nhé. Hẹn gặp lại các bạn trong các bài viết sau