Hello friends. It’s me again – Minh Monmen – who will accompany you in the next interesting moments (if you still read all the articles). His story is just the last day to attend a meetup group Vietkubers about K8S in Hanoi. Which contains a Zero-downtime section when upgrading the cluster . Actually, I feel that their presentation lacks something, so going home must quickly reassure all my knowledge about this issue to re-systemize the rules. It is also convenient to rewrite some lines so that you can consult and discuss with you.

First things first
Name, as I said above: Minh Monmen . (Take advantage of promoting small names  ).
).
Knowledge required before reading:
- What is Kubernetes , of course
- K8S manifest written in yaml
- Deploy app to K8S
I plan to write this article into a series, because the zero-downtime problem is not that simple. Application has a variety of conditions, so the problems that each application faces are different. In this first part, I will cover the basic concepts, as well as an ideal case application called k8s for us to test. If you support, then I will have the motivation to continue writing part 2, part 3 about the more difficult cases I have met. Otherwise, it must be … okay =)).
Okay? Let’s begin!
Note: In the lesson, there may be some terms / words that I have not used correctly because I have not yet thought of a way to express it in standard words only. You can just understand the meaning you want to say, don’t retort the sentence.
Stateful and stateless app
You’ve probably heard the term ” stateless and stateful” already. However, I think it is not easy to understand it properly. I also discovered that many articles now mention stateless , stateful and assume that the reader has to understand what these two terms mean. However, according to personal experience when his other training you see most are taking the order out at all.

In fact, stateless or stateful are two words with only two very general properties and many aspects, while people often understand it in a very restrictive way. The default example of anything with a session is stateful, having a token is stateless, … Nope, nope and nope.
Stateful and stateless should be understood in each context. For example, we have a shopping cart app running 3 instances:
GET /cartHTTP request is called stateless in connection context: because this request opens a new connection to the server, then closes that connection. All the information it needs to transmit is contained in the request .GET /cartHTTP request is called stateful in the application context: because to get cart information, the server must store information about the cart from previous requests with session / cookie.- If the session is stored on a common persistent storage between instances, for example, a redis is outside, then our instance is stateless , since our instance doesn’t actually store any information from the previous request. Redis to save the other session is stateful
- If the session is saved in-memory on each instance, then our instance is stateful .
Through the above example, we can see that depending on the specific context, what we are talking about may have different stateless or stateful properties.
In this article, I will mention an ideal application with k8s. A stateless application in the instance context and also stateless in the connection context. The criteria it needs to achieve are:
- Do not save information directly on the instance app.
- Request form response-response immediately.
Zero-downtime and problems encountered
Maybe I don’t need to tell you what the term zero-downtime is to kiss? Zero-downtime is an application with no downtime – obviously. However, in order to achieve zero-downtime status, we have to combine many factors, from proper code app, to implementation to standard. Zero-downtime must be satisfied in the following cases:
- Scale up the application, increase the running instance.
- Scale down the application, reduce the number of instances running.
- Update the application with the new version.
- Update deployment infrastructure (update software, update hardware).
This case is the case of the initiative, here I will not mention the passive case as an error, the node down, … because they are outside the scope of this article.
The part that Vietkubers talks about is actually just a case of updating the deployment software . That is the tip of the zero-downtime deployment. In order to achieve zero-downtime in that case, your application must first qualify for the zero-downtime process. The necessary conditions are:
- There is a graceful shutdown mechanism
- There is enough time to move requests to other instances before shutdown
- New Instance must be ready to handle requests when joining load-balancing
From these two conditions we can see that with different applications there will be different cases to solve. For example, some cases are as follows:
- The request-response application has a fast response time , does not depend on instance handling (ideally – case in this article)
- Req-res application has a slow response time (eg applications that upload, handle large data, …)
- Application req-res depends on the previous processing / request instance (eg frontend SPA apps when calling css / js, …)
- Application uses persistent connection (eg websocket application, …)
Prepare tools
Ideal application
For simplicity, in this article I will demo for you an ideal stateless application, req-res format and fast response time. gcr.io/google-samples/hello-app is a unique image docker that shows the running hostname and version of the container, ideal for our testing when making app updates to the new version.
Test tool
I will use a tool called fortio to make a request to the app on our cluster k8s. This tool will help us create a constant request to the app and statistically ask for errors.
Environment
1 The K8S cluster is active or local K8S (running with minikube) is fine, because we are testing zero-downtime at the instance-pod level , not at the k8s node level.
Deploy with the default configuration
And now is the time to start deploying the application. I have a K8S manifest with the following deployment and service:
1 | <span class="token key atrule">apiVersion</span> <span class="token punctuation">:</span> apps/v1 <span class="token key atrule">kind</span> <span class="token punctuation">:</span> Deployment <span class="token key atrule">metadata</span> <span class="token punctuation">:</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> hello <span class="token punctuation">-</span> app <span class="token key atrule">spec</span> <span class="token punctuation">:</span> <span class="token key atrule">replicas</span> <span class="token punctuation">:</span> <span class="token number">2</span> <span class="token key atrule">selector</span> <span class="token punctuation">:</span> <span class="token key atrule">matchLabels</span> <span class="token punctuation">:</span> <span class="token key atrule">app</span> <span class="token punctuation">:</span> hello <span class="token punctuation">-</span> app <span class="token key atrule">template</span> <span class="token punctuation">:</span> <span class="token key atrule">metadata</span> <span class="token punctuation">:</span> <span class="token key atrule">labels</span> <span class="token punctuation">:</span> <span class="token key atrule">app</span> <span class="token punctuation">:</span> hello <span class="token punctuation">-</span> app <span class="token key atrule">spec</span> <span class="token punctuation">:</span> <span class="token key atrule">containers</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> gcr.io/google <span class="token punctuation">-</span> samples/hello <span class="token punctuation">-</span> app <span class="token punctuation">:</span> <span class="token number">1.0</span> <span class="token key atrule">imagePullPolicy</span> <span class="token punctuation">:</span> Always <span class="token key atrule">name</span> <span class="token punctuation">:</span> hello <span class="token punctuation">-</span> app <span class="token key atrule">ports</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">containerPort</span> <span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token punctuation">---</span> <span class="token key atrule">apiVersion</span> <span class="token punctuation">:</span> v1 <span class="token key atrule">kind</span> <span class="token punctuation">:</span> Service <span class="token key atrule">metadata</span> <span class="token punctuation">:</span> <span class="token key atrule">name</span> <span class="token punctuation">:</span> hello <span class="token punctuation">-</span> app <span class="token key atrule">spec</span> <span class="token punctuation">:</span> <span class="token key atrule">type</span> <span class="token punctuation">:</span> NodePort <span class="token key atrule">ports</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">port</span> <span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">targetPort</span> <span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">nodePort</span> <span class="token punctuation">:</span> <span class="token number">30001</span> <span class="token key atrule">protocol</span> <span class="token punctuation">:</span> TCP <span class="token key atrule">selector</span> <span class="token punctuation">:</span> <span class="token key atrule">app</span> <span class="token punctuation">:</span> hello <span class="token punctuation">-</span> app |
Then try applying to the cluster:
1 | $ kubectl apply -f hello-app.yaml deployment.apps/hello-app created service/hello-app created $ kubectl get pods NAME READY STATUS RESTARTS AGE hello-app-789b7b9c97-hf9rr 1/1 Running 0 2s hello-app-789b7b9c97-tfdwj 1/1 Running 0 2s |
Please turn on another terminal window and run the following command to monitor the changes of service, replicaset and pod on k8s:
1 | $ <span class="token function">watch</span> -n 2 <span class="token string">"kubectl get services && kubectl get replicasets && kubectl get pods"</span> |
The above command means that the following command will be called once every 2 seconds
Let’s try running on our app:
1 | $ <span class="token function">curl</span> http://157.230.xxx.yyy:30001/ Hello, world <span class="token operator">!</span> Version: 1.0.0 Hostname: hello-app-789b7b9c97-hf9rr $ <span class="token function">curl</span> http://157.230.xxx.yyy:30001/ Hello, world <span class="token operator">!</span> Version: 1.0.0 Hostname: hello-app-789b7b9c97-tfdwj |
So, we have successfully deployed version 1.0 hello-app with NodePort service at port 30001 on the server. Try curl on the endpoint above and we will see the running pods load-balancing in turn to respond to our request.
Now let’s revise the deployment image on version 2.0
1 | <span class="token punctuation">...</span> <span class="token key atrule">spec</span> <span class="token punctuation">:</span> <span class="token key atrule">template</span> <span class="token punctuation">:</span> <span class="token key atrule">spec</span> <span class="token punctuation">:</span> <span class="token key atrule">containers</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> gcr.io/google <span class="token punctuation">-</span> samples/hello <span class="token punctuation">-</span> app <span class="token punctuation">:</span> <span class="token number">2.0</span> <span class="token punctuation">...</span> |
Start deploying fortio:
1 | $ fortio load -qps 100 -t 60s <span class="token string">"http://157.230.xxx.yyy:30001/"</span> |
The above order fortio loaded 100 requests / s during the 60s
And apply a new image:
1 | $ kubectl apply -f hello-app.yaml deployment.apps/hello-app configured service/hello-app unchanged |
This is the test result:
1 | Sockets used: 11 <span class="token punctuation">(</span> for perfect keepalive, would be 4 <span class="token punctuation">)</span> Code -1 <span class="token keyword">:</span> 2 <span class="token punctuation">(</span> 0.1 % <span class="token punctuation">)</span> Code 200 <span class="token keyword">:</span> 3964 <span class="token punctuation">(</span> 99.9 % <span class="token punctuation">)</span> Response Header Sizes <span class="token keyword">:</span> count 3966 avg 116.9705 +/- 1.858 min 0 max 117 <span class="token function">sum</span> 463905 Response Body/Total Sizes <span class="token keyword">:</span> count 3966 avg 182.95386 +/- 2.905 min 0 max 183 <span class="token function">sum</span> 725595 All <span class="token keyword">done</span> 3966 calls <span class="token punctuation">(</span> plus 4 warmup <span class="token punctuation">)</span> 60.572 ms avg, 66.0 qps |
So there is still a small amount (0.1%) of requests that fail when we update the app. Why so?
Find out the problem
First, let me mention the mechanism for replacing K8S pods . There are two types of replacing the K8S-deployed pod that are:
- Recreate : stop all old pods and start starting new pods
- Rolling Update : Start the new pods and stop the old pods at the same time, controlling with the minimum number of active pods (
maxUnavailable) and the maximum number of new pods (maxSurge). More details about these 2 parameters here
Here to achieve zero-downtime, we will apply the Rolling update mechanism. Thus K8S will start the new pods to receive new requests, and interrupt the old pods at the same time. This mechanism is applied by default . See more here
However, look more carefully at the lifecycle of a pod:
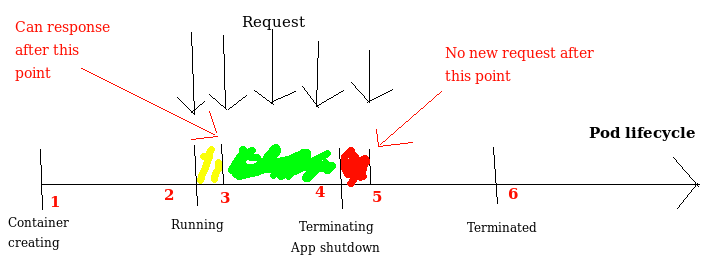
The picture above shows four normal operating states including Container Creating , Running , Terminating , Terminated of a pod. In theory, the request will be routed to the processing pod during the period from point 2 to point 4. To keep no request in error, the application needs to be able to process the request at point 2, and stop receiving requests from score 4. However, in fact, our application will:
- App takes startup time. Therefore, when the application is capable of processing the request, it is reversed from number 2 to score 3
- Update routing on k8s. For service types that are expose out via nodeport or ingress, K8S and ingress controllers will take time to update routing, while the app has received the signal to stop processing from the 4 points. And the internal mechanism of why it takes time is not enough time to talk here. Therefore the request receiving pod point is pushed from point 4 (starting Terminating status) to point 5
From the above reasons, two red and yellow time periods if there is a request to the pod will fail. This affects the old pod stop process (red part) and uses the new pod (gold section).
Solution
I will solve each process one by one. The first is with the gold part.
Readiness check
To solve the problem The application takes time to start , K8S provides us with a tool called Readiness probe . This is essentially a test configuration. Accordingly, K8S will perform a regular Readiness probe to check whether the application is really ready to process the request, and then to request the request to the pod.
To configure Readiness probe we add the following manifest segment:
1 | <span class="token punctuation">...</span> <span class="token key atrule">containers</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> gcr.io/google <span class="token punctuation">-</span> samples/hello <span class="token punctuation">-</span> app <span class="token punctuation">:</span> <span class="token number">2.0</span> <span class="token key atrule">readinessProbe</span> <span class="token punctuation">:</span> <span class="token key atrule">httpGet</span> <span class="token punctuation">:</span> <span class="token key atrule">path</span> <span class="token punctuation">:</span> / <span class="token key atrule">port</span> <span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">initialDelaySeconds</span> <span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">periodSeconds</span> <span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">successThreshold</span> <span class="token punctuation">:</span> <span class="token number">1</span> <span class="token punctuation">...</span> |
The Config above tells K8S to run the test by making a request http
GET /to the container on port 8080 . Interval is 5 seconds. Time to wait 5 seconds to start. The number of successful attempts to count is ready: 1
By checking the Readiness probe , we delay the forward request to the pod until the application is ready (score 3).
Prestop hook
To solve the problem of updating routing on K8S takes time , we will interfere with a lifecycle hook of K8S named preStop . Prestop hook is called synchorous before sending the shutdown signal to the pod . PreStop hook is simply waiting for a moment to load balancer to stop the forward request to the pod before shutting down the app
1 | <span class="token punctuation">...</span> <span class="token key atrule">containers</span> <span class="token punctuation">:</span> <span class="token punctuation">-</span> <span class="token key atrule">image</span> <span class="token punctuation">:</span> gcr.io/google <span class="token punctuation">-</span> samples/hello <span class="token punctuation">-</span> app <span class="token punctuation">:</span> <span class="token number">2.0</span> <span class="token key atrule">readinessProbe</span> <span class="token punctuation">:</span> <span class="token key atrule">httpGet</span> <span class="token punctuation">:</span> <span class="token key atrule">path</span> <span class="token punctuation">:</span> / <span class="token key atrule">port</span> <span class="token punctuation">:</span> <span class="token number">8080</span> <span class="token key atrule">initialDelaySeconds</span> <span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">periodSeconds</span> <span class="token punctuation">:</span> <span class="token number">5</span> <span class="token key atrule">successThreshold</span> <span class="token punctuation">:</span> <span class="token number">1</span> <span class="token key atrule">lifecycle</span> <span class="token punctuation">:</span> <span class="token key atrule">preStop</span> <span class="token punctuation">:</span> <span class="token key atrule">exec</span> <span class="token punctuation">:</span> <span class="token key atrule">command</span> <span class="token punctuation">:</span> <span class="token punctuation">[</span> <span class="token string">"/bin/bash"</span> <span class="token punctuation">,</span> <span class="token string">"-c"</span> <span class="token punctuation">,</span> <span class="token string">"sleep 15"</span> <span class="token punctuation">]</span> <span class="token punctuation">...</span> |
The preStop configuration above is simply running a bash command waiting for 15s and sending shutdown signal to the app.
Achievement
This is the lifecycle diagram of the pod after we have added readliness probe and lifecycle. We can see that the shutdown app from point 5 is pushed back to 7. So the request to push into the pod within the update routing time (number 4 -> 5) is still handled completely. Also readiness probe also informs K8S to push new requests into pod from score 3.

Let’s change the version app and follow fortio:
1 | $ kubectl apply -f hello-app.yaml deployment.apps/hello-app configured service/hello-app unchanged |
1 | $ fortio load -qps 100 -t 60s <span class="token string">"http://157.230.xxx.yyy:30001/"</span> <span class="token punctuation">..</span> . Sockets used: 8 <span class="token punctuation">(</span> for perfect keepalive, would be 4 <span class="token punctuation">)</span> Code 200 <span class="token keyword">:</span> 4833 <span class="token punctuation">(</span> 100.0 % <span class="token punctuation">)</span> Response Header Sizes <span class="token keyword">:</span> count 4833 avg 117 +/- 0 min 117 max 117 <span class="token function">sum</span> 565461 Response Body/Total Sizes <span class="token keyword">:</span> count 4833 avg 183 +/- 0 min 183 max 183 <span class="token function">sum</span> 884439 All <span class="token keyword">done</span> 4833 calls <span class="token punctuation">(</span> plus 4 warmup <span class="token punctuation">)</span> 49.618 ms avg, 80.5 qps |
All done, zero-downtime.
Conclude
So I showed you two practical problems I have handled when deploying the application on K8S to ensure zero-downtime when rolling update your application.
- Handle readiness probe
- PreStop hook configuration
Hope you will gain some experience from this article to apply to your work. If you are interested in having trouble connecting persistent, sticky session, etc. when dealing with zero-downtime, please comment in support so I can have more motivation to write.
Thank you.